目次
はじめに
はじめまして!今年2月にABEJAにデータサイエンティストとして入社しました真鍋と申します。
こちらは、ABEJAアドベントカレンダー2022の2日目の記事になります。
2日目にしていきなり限界野球オタク丸出しの記事ですが 野球は2番最強打者論もあるくらいなので縁起の良い数字ですね、はい。
アイデア
ある程度野球を見ている方なら想像ができるのではないかと思いますが、野球の試合では、「あ、そりゃ打たれるわ」という球があったりしますよね。
ど真ん中に棒球が行ったりとか、同じ球が何球も続いたりとか…
ただ、それが「打たれるべくして打たれた」球なのか、「打者が上手くて打たれた」球なのかは、結構感覚によるものだと思います。
そういう感覚を、少しでも数値化したい、というところから着想を得ています。
実は「速球の次の変化球」や「内角高めの後の外角低め」が危ないというような、「実は危ない」パターンを新発見的に出せたら嬉しいな…と思いつつ、
「この球、打者が振らなかったからよかったけど、実は危なかったよ」みたいなことが言えるようになればいいな、と企んでいます。
検証方法
データ準備
まずは一球ごとのデータセットを確保します。 MLBのデータは、pybaseballというライブラリを使えば、数年分でも簡単に取得可能です。 pybaseballの詳細は、手前味噌ですが以前Qiitaに私的にまとめているので、そちらをご参照ください↓ qiita.com
Statcast自体は、2020年にホークアイが全球場に導入されたので、データのとり方が大きく変わったようです。
ホークアイ自体は、テニスのプロマッチ等で使用されているものですが、日本でも、昨年スワローズが神宮球場でのデータを公開して、話題になりましたね。
From 2015-19, Statcast consisted of a combination of camera and radar systems. That changed in 2020, with the arrival of Hawk-Eye. A camera system previously known for powering the instant replay system in professional tennis, among other things, Hawk-Eye offers increased tracking ability as well as a host of exciting new features. Each club now has 12 Hawk-Eye cameras arrayed around its ballpark.
(引用元: MLB公式HP 用語集よりStatcastについて) www.mlb.com
データの取得方法の変化がデータの品質に影響する可能性もあるため、2020年以降のデータで検証します。
*NPBの一球データをスポナビ等からスクレイピングする方法もありますが、今回は回転数やリリース位置、守備シフト有無等の精緻なデータでの検証が可能なMLBのデータで見てみます。
分析アプローチ
もともとは被打率か被長打率を予測させたかったのですが、空振りやファールの取り扱いが難しく、かつ予測結果も芳しくなかった (「絶対打たれないマン」が多発してしまった) ので、 最終的には空振りか、当たった際にどれくらいのハードヒットになるかを予測する、所謂分類モデルに落ち着きました。
データ通の野球ファンの方は「バレル」についてはすでにご存じかもしれないですが、Statcastでは、そのバレルを含めて6つの打球タイプを定義しています。
launch_speed_angle
Launch speed/angle zone based on launch angle and exit velocity.
1: Weak
2: Topped
3: Under
4: Flare/Burner
5: Solid Contact
6: Barrel
(引用元: Baseball Savantより、出力用CSV公式ドキュメント) baseballsavant.mlb.com
要は、打球タイプは打球速度・角度に基づいて算出されており、私の意訳になりますが、 「1. 弱いコンタクト」「2. ボテボテのゴロ」「3. ポップフライ」「4. 強烈なゴロ/ライナー」「5. 良いコンタクト」「6. バレル」くらいの感覚です。 イメージ的には以下のような打球角度・速度になります。

(引用元: Twins Daily。こちらの画像自体は他サイトでも掲載あり)
今回は、その6つの打球タイプに、「0. 空振り」を加えます。バントの空振りも空振りとみなします。
AIモデルには0~6を予測させたかったのですが、なかなか難しい…ということで、1~3を「1. 弱いコンタクト」、4/5を「2. 良いコンタクト」、6を「3. バレル」としてクラスを少し丸めて、この0~3を予測してもらいます。
* ファールボールも対象に入れてもよかったのですが、「ファールの質」の定義をしないといけないので、対象外にしました。
「球威に差し込まれたファール」と「捉えたファール」は違うと思いますが、そこは明確に定義されているわけではなさそうなので、考慮から外した次第です。
ちなみに、Statcastではファールボールも打球角度と打球速度は取れています。
データ取得
pybaseballを使うと、3年分のデータが2行のPythonコードで取得できてしまいます。
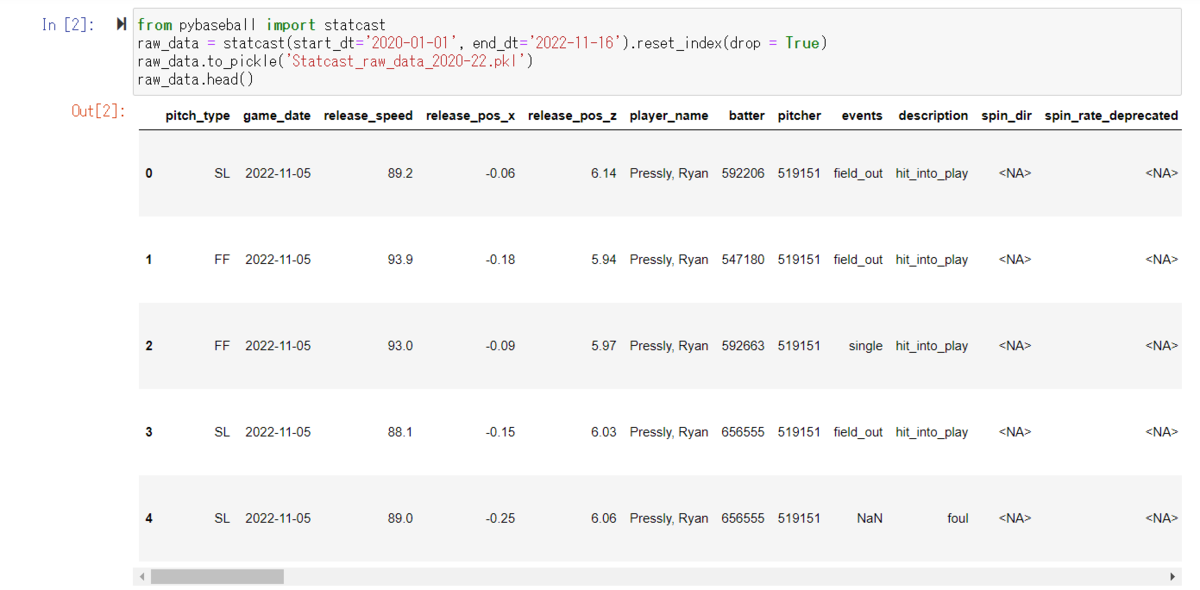
上記Statcastのリンクによると60試合の短縮シーズンだった2020年でも、26万球以上のデータがトラッキングされているため、162試合だと70万球近くなるはず…と考えるとこんなものなのですが、改めて180万球というのはすごいものですね。
前処理・特徴量エンジニアリング
得られた181万行のデータに対して、日付の年・月・日への分解や空白列の削除、カテゴリカル変数の定義等の基礎的なものを含め、前処理・特徴量エンジニアリングを行っていきます。
基本的には、野村克也さんの書籍や、野球中継での解説者の方のコメントを参考にしつつ、私自身が年間100試合近く現地観戦することもある中で思ったこと等を踏まえて、入れられる範囲で特徴量を入れています。
特徴量は400個ほど付与しています。レコード数が多く、私がローカルで実験的にやっていた環境でもメモリエラーを簡単に吐いてしまうレベルでした。恐るべし… 個々の特徴量の具体的な説明は省きますが、例えば以下のような想定で特徴量を入れ込んでいます。
- 配球の比率はデータとして打者も見ている
- 前の球と同じ球速帯だとタイミングを修正してあわせられる
- 同じ球種やコースが続くのは危ない
- 同じ試合でも1球目と100球目では球も走らなくなる
- 同じ球種でも「いつもより速度が出ていない」場合は危ない
- 同じ球種・球速でも回転やリリース位置が悪いと危ない
- 直近の調子が重要。三振が多い/打球を捉えられている等で調子がおおよそわかる
- 直近の数球が「狙い球」に影響することがある (ストレートが続いている、遅い球が続いている…等)
このほかにも、成績を情報として食わせるほうが良いと思ったのですが、「前日までの成績」は取得に時間がかかり、前年成績を入れたら精度が落ちてしまったので、外しました。
成績自体は300個以上の項目が取れるので、精査すれば有効な特徴量もあるだろうとは推測しますが、単純にシーズン成績でそれだけの種類の成績が取れるなんて、すごいですよね…
また、最後にデータの絞り込みをしています。「振った上でどうなるか」を予測させたいので、最初は「前に飛んだか空振りした球」に絞ろうと思っていたのですが、そうすると、データが不均衡になってしまう、かつ、「空振り」を予測しやすいモデルになってしまうので、その打席の「結果球」に絞ることとします。
*例えば、空振り→空振り→内野ゴロという打席がデータ3つぶん、ボール→ボール→外野フライという打席はデータ1つぶんになる。空振りだけデータが多くなってしまう
また、打球速度や角度等、所謂リークになってしまうカラムを、最後に落としています。この記事では、投球のデータが取れた瞬間に「仮に打者が振っていたらどうなるか」を予測させたいので、投球のデータまでは取れる、その結果は打球タイプ以外使わない、という組み方をしています。
*バレルを例にとると、打球速度・角度の組み合わせ次第ではバレルが確定してしまうので、これらの情報を与えてしまうと、カンニングできてしまいます
学習
手法は、まずはLightGBMを使います。
どちらかというと特徴量エンジニアリングで色々工夫余地があると感じたため、手法であれこれ試すよりは、少しでも多く特徴量エンジニアリングを試すこととします。
あまり時系列固有の特徴がないと言えばないですが、時系列データにはなるので、sklearnのTimeSeriesSplitでデータを5分割して、クロスバリデーションしたいと思います。
結果
モデルとしては約60%の精度でした (クロスバリデーションの5つ目のIterationで58.5%)。
ちなみに、6つあった打球の種類に空振りを加えて、7種類で予測をさせたときの精度が40%強でした。


ちなみに特徴量エンジニアリングで作った特徴量では、「直近50打席・100打席でのクラス0 (空振り) の割合」や「z方向への加速の平均との差」というような特徴量が上位15~20位に入ってきておりました。
考察
このモデルが最も「空振りが取れる」と予測したのは、以下の選手でした。
*下記では、予測値が0なら0、1以上なら1を返すように予測値を補正して、補正予測値の平均を出しています。なのでこの数値が少ないほど、0を予測している場合が多い、ということになります

野手が混ざってますね 基本的には、打者を制圧するようなクローザーが多いかな?その中で先発投手のジェイコブ・デグロム投手がランクインするのは、さすがバケモンって感じですね。ちなむと、昨年まで阪神で無双していたロベルト・スアレス投手が27位でした。
私自身は2008年以来のブルージェイズファンなのですが、ブルージェイズの首位はトレバー・リチャーズ 投手で全体41位、2位はなんと菊池雄星投手 (59位) でした。チーム的には、K/9の1位と3位なので、まあこんなものかな?
ちなみに、純粋なクラスの平均値をとった時は、2位のエドウィン・ディアズ投手が1位でした。こちらは、コンタクトの質 (弱いコンタクト/良いコンタクト/バレル) も考慮に入れているので、
モデルが「最もハードヒットされにくい」と予測した投手ともいえるでしょう。ディアズ投手は「最も打てないクローザーの1人」といわれることもあるので、感覚的にはそうなのかもしれない。
ちなみにディアズ投手といえば、登場曲の生演奏で登場するシーンがかっこいい!と日本の野球ファンの間でも話題になりましたね。
最後に、せっかくサムネイル画像にしたので、マーくんこと田中将大投手の、2020年 (日本復帰前の最終年) の予測結果を見てみましょう (*筆者は巨人ファンです プロ野球12球団のファンクラブ全制覇してるなんて口が裂けても言えない)
サムネイルの写真は、私が現地観戦時に撮影したマーくんの日本復帰後最初の1球なので、この記事では、アメリカでの最後の1球を見てみます。
www.mlb.com
あいにく、ポストシーズンで被弾したのがMLBでの最後の1球になってしまったわけですが、予測結果は…まさかの1. (弱いコンタクト) でした。
実際には「バレル」だったので、やはりハードヒットを予測するのは難しいのかも…
まとめ
使えそうな雰囲気はありますが、もう一押しも二押しもできそうですね。 もっとやりたかった、できたかもしれないなと思う特徴量エンジニアリングの例としては、
成績の充実 (試合開始時点での年間成績、直近○○試合での成績、コース別の打率等)
連続で同じ高さ/内角・外角に投げた回数
打者左右別での球種比率
前の打者、その前の打者への配球
走者や守備選手に関する指標 (UZRや、3年間のUZR平均等)
…色々出てきますね。時間の都合で割愛しましたが、例えば球速や回転数、変化量は「リーグ平均との差」なんかも効きそう。
また、MLBでどこまで打者の「タイプ」があるかはわからないですが、日本だと「来た球を打つ」タイプや「狙い球を最後まで絞って待つ」タイプ等、打者のアプローチも多様なため、そのような情報も入れられると面白いかもしれません。
後は、本当に実用化するのであれば、「空振りかファウルか前に飛ぶか」を予測するモデルと、「(前に飛ぶ場合に) どれだけハードヒットになりそうか」を予測するモデルとか、「打球速度」「打球角度」をそれぞれ予測させるとか、アプローチも色々検証できそうです。
どこかで続編にチャレンジできたらとは思いますが、何も考えずにプライベートのローカル環境 (Windows + Jupyter Notebook) で実行して、何回もメモリエラーでプログラムが逝ってしまったので、今度はカチっと環境を整えてやりたいところです。
ABEJAについて
株式会社ABEJAでは共に働く仲間を募集しています! このモデルをもっとイケてるものに改善してやりたい、野球に限らずAIで面白いことがしたい、AIで社会を変えていくことに興味がある方は、ぜひこちらの採用ページからエントリーください。
