はじめに
こんにちは、Labsチームの藤本です。本日は他己紹介ということで、ABEJA Data Scienceチームの紹介をしていきます。今回はテックブログと言うより会社紹介になってしまいましたが、続編ではもう少し掘り下げる予定です。DSチームでは、主に機械学習や統計の技術を軸とし、お客様のデータの分析やエンジニアリングを通し、価値を出すべく日々データと格闘しています。僕が所属しているLabsでも機械学習技術がコアである所は同じなのですが、Labsが研究開発やプロト作りなどを中心にしているのに対し、DSチームでは実際に役に立つ技術をバシバシ作れている、そんな部署になります。
本記事では、ABEJAの頭脳の集合体とも言えるこのDSチームの紹介と、これまで多くの案件を進める中で培ってきたノウハウ・作ってきた仕組みを紹介していきます。ABEJAやDSチームに興味がある方にご一読いただけますと幸いです。
ABEJAにおけるDSのお仕事
どんな仕事?
上でも述べたように、DSチームでは、主にお客様のデータを分析したり、機械学習モデルを生成して推論モデルを構築します。対象となるデータも多種多様で、様々な業種、種類、タスクを扱います。これまでの案件でも、小売・製造・建設・物流など様々なものがありました。

仕事の内容としては、主にはDSチームで分析やモデル構築を行い、更にそのモデルをお客様の現場で利用すべく、WebAPIやエッジデバイス等で呼び出せるように実装していきます。 また、後に詳しく説明しますが、単にモデルを開発するだけではなく、お客様との要件調整の段階からプロジェクトに関わり、実現可能性なども考慮した上で、実行可能かつ価値が出るような方針を立てる事もします。機械学習に対する世の中の期待が大きい中で、解決することが非常に難しい課題・要望も多く、それをそのまま受けるのではなく、適切な問題に落とす事が価値のある結果に繋げるために重要となってきます。要件定義と聞くと「そりゃそうだろ」と思うかもしれませんが、機械学習はとりわけ不確定要素が多く、要件定義にもノウハウが必要となってきます。ABEJAでは機械学習プロジェクトを古くから手掛けている事もあり、多くの失敗も経験を乗り越え、レビュー制度などの形で仕組み化してきました。
以下のような、失敗しやすいケースを集めたセミナーなども開催しています笑
どんな人達?
多種多様な業界・タスクを扱うため、仕事を担うチームのメンバーも幅広い知識を持ち、色々な方が在籍しています。国籍も、日本人だけではなく外国籍の方もいたり、またKaggleマスターや、何社もスタートアップを立ち上げ且つスイーツを作るのが趣味な方など様々です。
過去の記事はコチラ
- きっかけは麻雀。Kaggle Masterが語る「好き」から始まる機械学習の道|テクプレたちの日常 by ABEJA|note
- 仕事の中身は「ドラクエの上級職」 データサイエンティストたちのリアル㊦ | 株式会社ABEJA
業務の進め方
プロジェクトが始まる前に、誰がどの案件を担当するかというアサインを決定します。その際に、プロジェクトに求められるスキル要件、リソースの空き状況、DSメンバーの希望(どんな部分を経験したいか)によって、誰がアサインされるかを決めます。1名アサインされるケースもあれば、メインDS/サブDS、メインDS、アドバイザーDS、メインDS複数名など、プロジェクトの規模やメンバーの状況によって変わります。プロジェクトがスタートすると、PM(Project Manager)や、場合によってはシステム開発のエンジニアと一緒に案件を進めていきます。
データの分析・モデル構築のフェーズは以下の3つあります。

アセスメントフェーズ
営業段階のタイミングでゴールを精査せずに決めてしまうと、無理な精度目標や工数になってしまう恐れがあり、営業段階でゴールが確立していることは稀です。多くの場合は、まずはアセスメントのフェーズからスタートし、PMと一緒にお客様とゴールの詳細の決定や開発・分析の方針を議論します。このフェーズでサンプルのデータを受領し、DSのメンバーが初期検証を行います。初期検証では、例えば画像分析であれば、どういったバリエーションがあるか・見つけたい対象がどう写っているか、などを確認します。その上で、データの収集の計画を練ったり、アノテーションの方針を決めます。データと方針がある程度見え次第、なるべく早くデータの収集やアノテーションを開始します。
PoCフェーズ
PoCフェーズでは、プロジェクトのゴールを達成できるかを検証します。データ分析やモデル構築を行い、中間報告・最終報告を通してお客様に結果を報告します。
最も多いのは、EDAをした上で目的としているモデルを構築・チューニングし、「モデルが実用上耐えうる精度が出るか?」を検証することです。基本的なモデルを構築する以外に、データ・タスクの特性に合わせた技術的な工夫をしたり、論文を調査して新しい手法を試したり、出来る限り目的を達成できるよう努力します。
また、モデルを構築するだけでなく、モデルが誤認識した場合にそれがどういうケースなのか?運用上カバーする方法があるのか?今後改善できる余地はあるのか?といった分析であったり、簡単にデモするための開発等もPoCフェーズで行うこともあります。
インテグレーションフェーズ
インテグフェーズでは、機械学習モデルの実運用に向け、PoCフェーズで開発したモデルをお客様のシステムに組み込んだり、既存システムがない場合は新たなシステム開発に着手していきます。より具体的には、DSメンバーとエンジニアメンバーが協力して、PoCで開発したモデルをABEJA Platform(後述)に実装するなどして、お客様が利用できるような仕組みを構築します。機械学習以外の部分、例えばフロントエンドやバックエンドの仕組みなどは、主にエンジニアのメンバーが開発を進めます。
ABEJA DSの特徴
①運用を意識したモデル開発
ABEJAでは、ABEJA Platformという機械学習モデルを開発・運用するための仕組みを持っています。ABEJA Platformでは、アノテーションをするためのツール群、過去のどの学習でどのデータを使ったかの管理、再学習をするための仕組み、推論をWebAPIとしてデプロイする仕組みなどをもっています。

このプラットフォームを使うことによって、多様な業種のお客様へ、機械学習のモデルの価値を提供できることを大きな特徴としています。この仕組みを活かすことにより、ABEJAではPoCをデータ分析・モデル開発で終わりにせず、モデルをシステムの中に組み込み運用し続ける所までをゴールとし、APIを通して推論する基盤を用意したり、継続的に機械学習モデルを再学習して精度を向上させたりといったモデルの運用に繋げることを大きな特徴としています。
②要件定義フェーズの早い段階からの連携
案件を進めるにあたり、そのゴールの設計が最も大事なプロセスの一つです。AIに対する期待が高い事が多く、殆どの場合は初期段階で検討されたゴールは、達成が困難です。例えば、センサに映らないような異常を検知したり、将来の需要を外部要因の入力無しに予測したりなどがあります。難しい案件をそのまま受けても炎上しますし、かといって案件を断り続けるわけにもいきません。
こういった要望に答えるため、ABEJAではDSチームが営業や要件定義などのフェーズから積極的に参加し、方針を検討します。会話の中で課題を整理して本当に解くべき問題を再定義したり、データの収集の方法の提案などもします。例えば、エリア内に人が立ち入った事を検知したいといった場合に、多くの場合はDeep Learningで物体検出をして欲しいという要望からスタートするのですが、整理してみると差分検知で良い場合や、時にはセンサを置くだけで良い場合もあります。もちろん実際にはそう簡単な問題になる事は稀ですが、データを実際に確認しながらゴールを上手く設計することにより、高速・高精度になるケースはいくらでもあります。与えられた問題に対する分析・モデル開発だけではなく、様々な業種において、課題の把握やゴールの設計に関わるのは一つの面白みではないかと思います。
③技術・情報共有の仕組み
機械学習の技術は日進月歩であり、少しでも勉強を怠ると直ぐに時代に取り残されます。これまでに解けなかった問題が、1ヶ月後に現実的な速度で解けるようになることも珍しくありません。DSチームではこういった最新技術に対する日々の勉強や、その他各自案件で開発した技術に関する技術情報の共有会の場を毎週設けています。また、ABEJAではDSチーム内での情報共有の仕組みだけではなく、社内の小規模なカンファレンス「ABECON」を始めとして、ハッカソン・アイデアソンなど様々なイベントを開いています。いつも開いてくれる皆さん、ありがとうございます。
日々のタスクなどの進捗に関する情報共有は、以前までgithubを使っていましたが、最近は全社的に情報をNotionに集約している流れに乗って、Notionへと移行しました。朝会や進捗確認の場などで、それぞれのタスクを確認します。
日々の取り組みや制度
ここまでに、DSチームの仕事や特徴を紹介してきましたが、具体的な取り組みを一つずつ紹介していきます。
①DS Review(提案内容議論・レビュー会)
営業段階で引き合いがあった際に、どのような提案にするかを議論する場です。お客様からの相談に対して、その案件を受けられるかどうかや、受けるとしても方針が問題ないかなどをチェックします。例えば、機械学習に関する案件の場合であれば、学習データの有無やアノテーションの難易度、タスクの難易度、どの程度の精度であればどういった価値が出せそうかどうか、そもそも別の方法で解けないかなどを精査します。議論に必要な情報が足りなければ、それを明確化していきます。
レビューシート
- 案件を進める上で重要となるポイントをテンプレートにしたシート、これを予め埋めておくことで受注前の抜け漏れを防げる
②中間レビュー(実装方針議論・レビュー会)
PoCにおいてデータの理解をした後に「どういったアプローチで進めるか?」「どういう方針で実装していくか?」を決めていく段階で、その方向でよいのか?他に考えられるアプローチはあるのか?といったところをDSメンバーでレビュー・ディスカッションする場です。
プロジェクトメンバー以外のデータサイエンティストからの違う視点でのコメント・アイデアで、よりよいアプローチを見つけてPoCの成功率をあげたり、お互いの技術交流になることを目的としています。
③プロジェクト振り返り会

一連の案件デリバリーが終わったあと、関わったDSメンバーを中心にプロジェクト全体を振り返る為の会を実施しています。
- 振り返り会コンテンツ例
- お客様からのフィードバック内容確認と分析
- プロジェクト進行の振り返り
- デリバリータイムライン
- 取り扱ったデータとEDAについて
- ナレッジの整理
- すべての実験(モデルとチューニング)と結果
- プロジェクトの学び確認
- 全体KPT (Keep, Problem, Try)
- etc...
④Brainstorming (学習・スキルアップ機会)
週に1回程度、各自がテーマを持ち寄り、案件で開発した技術や利用した技術、その他興味あるテーマなどを共有します。
具体的には、最近読んだ論文の紹介、ライブラリの機能紹介、自身が参加したKaggleコンペのソリューション共有、直近の業務でのプロジェクトの共有など幅広く行っています。また、ただ共有するだけでなく、「こういう技術の適応は出来ないのか?」「これも近いものであるよね」などインタラクティブなやりとりもあります。
⑤DS codebook (技術蓄積&再利用性向上の仕組み)
案件をたくさんこなす中で過去のソースコードを検索・再利用する仕組みがあれば効率的なフィージビリティテストや開発活動が可能になります。これを実現する為に「DS codebook」という社内DSメンバー起点のプロジェクトが発足しました。DS Codebookは主に以下の役割があります。
- ソースコードのテンプレート化・モジュール化の促進

- 過去プロジェクトで使ったソースコードの検索・可読性・再利用性の向上

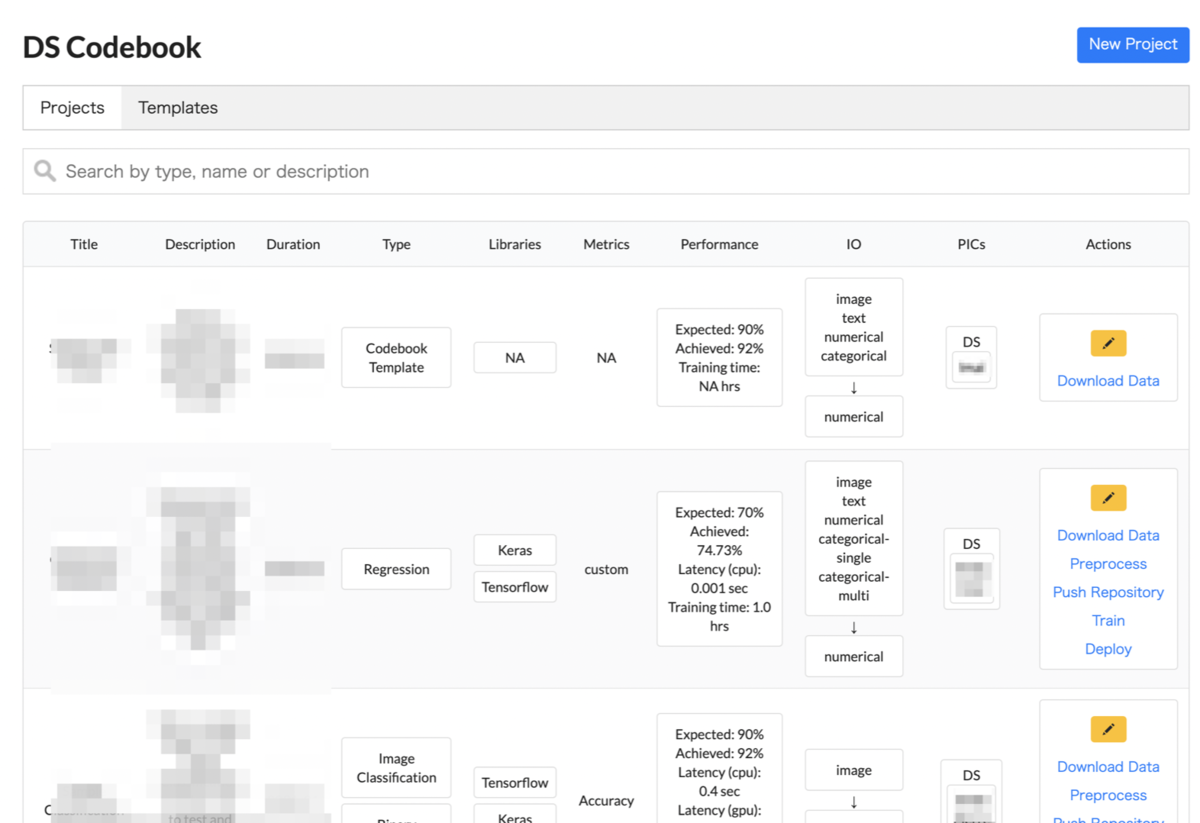
- 前述のABEJA Platformを用いることで学習や推論の再現性担保
過去のプロジェクトのリポジトリは存在するが、どうやって実行するか分からない、案件ごとにコードの構造化がバラバラ、何をしているのか読み解けない....みたいなことはよくあると思いますが、それを極力なくすことが出来ると思っています。
おわりに
本記事ではDSチームの業務や、PoCで失敗しないためのノウハウを幾つか紹介しました。お客様からの要望に従って分析・モデル構築するだけではなく、要件の定義から運用まで広く携われるところが面白い所なんじゃないかと思います。また、本記事ではあくまでDSの仕事に絞って紹介しましたが、案件以外の個々の様々な取り組みを、会社としてバックアップできるような体制作りもしています。

ちょっと話を聞いてみたい、もう少し詳しく知りたいなどありましたら、是非ともご連絡ください。 DSチーム、HRメンバー共々心よりお待ちしております。
参考:取り扱っている技術スタック
DSチーム内で取り扱っている技術スタックを下記にまとめております。ご興味があれえばご一読くださいませ。
