
1. はじめに

こんにちは、ABEJAの服部です。昨日、ABEJAが主催しているABEJA SIX2022でも発表がありましたが、NVIDIA社のGPUを利用し、ABEJA内で日本語版 巨大言語モデル(GPT)を作りました。一部のモデルは一般公開に向けて準備中です。なかなか巨大言語モデルを作る機会はないと思うので、モデルづくりにあたっての苦労した点であったり、道のりについてお話できたらと思います!
2. そもそもGPTとは??
GPTとは、与えられた文章から次の単語を予測する深層学習を用いた言語モデルです。そして繰り返し単語を予測することで文章を生成することができます。また文章の生成だけでなく、様々な言語タスクでも良い精度を出しています。GPTではTransformerといったBERTなどで使われている構造を使って、大量パラメータを持ったモデルを、大量データで事前学習させているのが特徴です。
OpenAIからGPT-2, GPT-3と発表されており、モデルのサイズも大きくなると共に精度も向上しています。GPT-3は精度が高すぎて、フェイクニュースなどに悪用されるのではないか?危険すぎるのでは?と発表された当時は話題になっていました。ちなみに以前アドベントカレンダーで、GPT-2に対して「データサイエンティストとはなにか?」を聞いたことがあります。 興味ある方がいましたらこちらも御覧ください。
3. ABEJAで作ったGPTモデルについて
3.1 モデルサイズ
GPTといっても様々なサイズ(パラメータ数)のモデルが存在します。GPTはTransformerのモデル構造で、Transformer部分のAttention Headの数、layer数、隠れ層の数あたりがサイズとしての変動要素です。Scaling Lawという言葉も使われていますが、この数を増やしてモデルを巨大にすればするほど精度があがっていくといわれています。サイズが大きいものは精度が良かったとしてもFinetuningや推論コストが高くなるため、今回私達も様々なパラメータサイズのモデルを作りました。日本語対応モデルとしては既にいくつかの企業や個人の方々がGPTモデルを公開しています。(2022年7月現在。かつ漏れがある可能性はご了承ください)先人たちには感謝しかないです。
| モデル名 | パラメータサイズ | |
|---|---|---|
| rinna/japanese-gpt-1b | 1.3B | |
| rinna/japanese-gpt2-medium | 336M | |
| rinna/japanese-gpt2-small | 110M | |
| rinna/japanese-gpt2-xsmall | 37M | |
| gpt-neo-japanese-1.3B | 1.3B | |
| GPT-J-6B | 6B | |
| gpt-j-japanese-6.8b | 6.8B | |
| new | ABEJA model1 | 750M |
| new | ABEJA model2 | 2.7B |
| new | ABEJA model3 | 6.7B |
| new | ABEJA model4 | 13B |
公開済みのモデルにも様々なパラメータサイズのモデルがありますが、6.7B, 13Bあたりは他のモデルと比べても大規模であることが分かるかと思います。
3.2 データセット
今回学習にあたっては4つのオープンデータを使いました。
Wikipedia
Wikipediaデータセット、多くの日本語言語モデルで使用されている
CC100
Wikipediaに次いで、日本語言語モデルで多く使用されている。元々はfacebookresearch/XLMの学習に使用されたが、エジンバラ大学の協力のもと数多くの言語に翻訳されている
OSCAR
Common Crawlで集められたデータがベース、クローリングされたコーパスを言語分類することで得られた多言語コーパス、オリジナル版と重複削除版が存在しており、今回のタスクでは後者を使用
mC4
Common Crawlで集められたデータがベース、AllenAIによって作成されたバージョンを使用した。108の言語に対応している。今回ABEJAではGPTの一部のバージョンで使用した。
3.3 参考にしたコード
今回学習にあたり、オープンソースとして公開している学習コードをいくつか参考にさせていただきました。具体的には、巨大モデルはGPT-neox、小規模なモデルはrinna社のコードを参考にさせていただいています。改めまして、先人たちには感謝です。
- Rinna GPT
- GPT-neox
3.4 モデルの学習
モデルを学習させる部分についてです。実際にはモデルを学習させるところまでが大変であるので、ここまで来ると祈る時間が増えます。GPTモデルの学習時の性能評価としてはPPL(perplexity)を使いました。PPLは「次の単語の予測をいかに正しく出来たか?」を測る評価指標になります。予測が正解に近いほど、PPLは小さくなっていきます。PPLについてはこちらの記事がわかりやすいです。
ただし、GPTとしての性能として、PPLで全てが決まるか?というとそうとは言えません。実際にはGPT-3などの論文では多くの事前学習したモデルを使って言語タスクを解いた時の性能で評価しています。ちょうど日本語の評価データセットが公開されたところでしたがタイミング的にも間に合わず、PPLで評価しました。改めて各言語でのデータセットの整備といった活動の大事さを感じました。
せっかくここまで育てたモデルが・・・
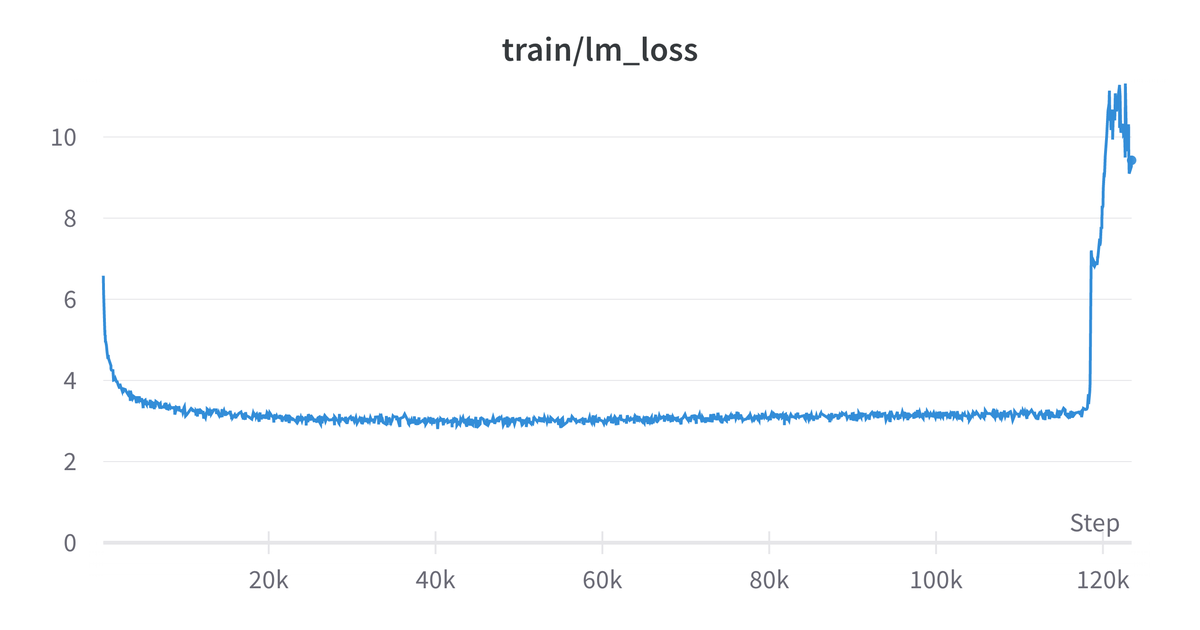
特に大きいモデルについては、最初はうまくいっているように見えて途中でLossが発散してしまい学習に失敗してしまう事象が発生していました。1週間くらいかけたモデルが急に学習失敗したときの絶望感は何とも言えません。。ただ、幸いなことに後述する並列学習によりLossの発散に早期に気づけました。これが数ヶ月学習した後だとしたら立ち直れません。またこの学習の失敗については、後述のモデルアーキテクチャの工夫をすることで解決することが出来ました。こちらは実際に発散した時のLoss曲線です。
4. 技術的な工夫点
4.1 データセットの前処理
データセットに対しての前処理も一つの重要な要素でした。BERTやGPTなどのTransformer系のモデルは古典的な手法に比べると前処理の重要性は減っているとも言われますが、それでも侮れません。実施した前処理全てについては語りませんが、実際、前処理をすることで改善するような事例もいくつか見られました。データセットの中には、URLやサイト上よく表示される定型記号のようなものが存在します。こういったものを除くのは重要でした。例えば、パンくずリストやメニューのような文章もデータセットの中には多々ありました。(例: 企業情報 - 事業内容 - お問い合わせ - リンク - )これを含めたデータで学習したモデルは、出力する文章についてもパンくずリストを含むような出力をしてしまう傾向がありました。こういった、 モデルに出力してほしいものと違う傾向があるデータを除く というのはGPTでは特に大事かと思います。
また、今回の学習ではhuggingface datasetsをそのまま使うのでなく、前処理後のデータをプレーンテキストとして保存したものを利用しました。そうすることで学習時間の短縮になります。その時、問題となったのがインスタンスのディスク容量と処理速度です。huggingface datasetsのダウンロード分、それを展開する分、プレーンテキストとして保存する分と本来のデータサイズの3倍のディスクサイズが必要となります。こちら当初予定を見誤り、前処理途中でディスクサイズオーバーとなってしまったこともありました。また処理速度も非常に重要でそのまま前処理を行うと数週間という非常に長い時間を要してしまいます。大量のCPUを用意し、今回は並列処理を行うことでこの問題を解決しました。
また、一部のデータセットでは前処理の内容によっては時間が大量にかかりすぎる問題も発生しました。
4.2 GPT-neoxの活用
弊社でもGPTほどの大きなモデルを学習することは初の試みでした。なかでも知見として蓄積できてよかったのはモデルの並列学習です。GPT-neoxでは大規模モデルをGPUのメモリに乗せるために、様々な工夫を取り入れています。中でもDeepSpeedによる並列化の力は偉大でした。
論文
https://aclanthology.org/2022.bigscience-1.9.pdf
We use the AdamW (Loshchilov and Hutter,2019) optimizer, with beta values of 0.9 and 0.95 respectively, and an epsilon of 1.0E−8. We extend AdamW with the ZeRO optimizer (Rajbhandari et al., 2020) to reduce memory consumption by distributing optimizer states across ranks. Since the weights and optimizer states of a model at this scale do not fit on a single GPU, we use the tensor parallelism scheme introduced in Shoeybi et al. (2020) in combination with pipeline parallelism (Harlap et al., 2018) to distribute the model across GPUs.
PyTorch等で複数GPUを活用する際に最も広く使われているであろう手法はDataParallelであり、こちらは各GPUにバッチデータを分配してそれぞれの結果を統合するような仕組みです。しかし、この手法ではモデルそのものは分割されないため、今回学習したような13Bパラメーターのモデルでは各GPUのメモリに乗り切りません。(40GBメモリのA100ですら乗りません・・・)
そこでDeepSpeedの出番です。イメージ図のようにBaselineがDataParallelだとすると、DeepSpeedではParameter、Gradient、Optimizer Stateすら各GPUで並列化して処理することで省メモリを実現しています。
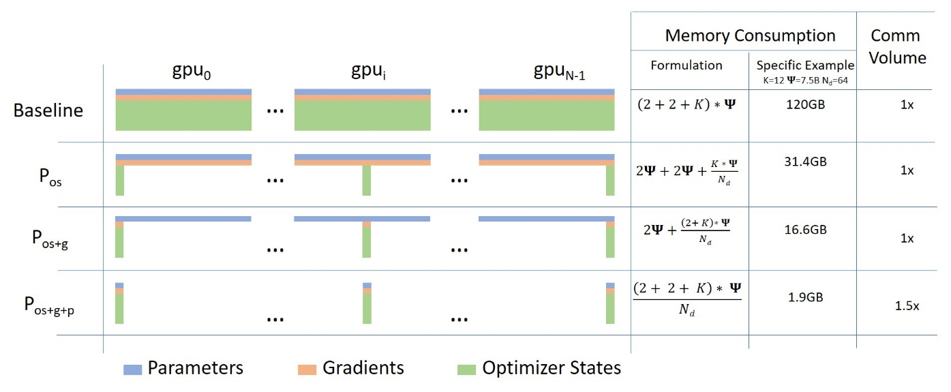
DeepSpeed使っただけといってしまえばそれまでですが、GPT-neoxではDeepSpeedの他にPipe ParallelとTensor parallelism(詳細割愛)も組み込まれていているためコード理解が難航しました。
内部的なスケジュール事情として、これらの理解含めて学習完了まで比較的短い時間で持っていく必要がありその点は苦労しながら進めました。
4.3 並列VMでの学習
GPTの学習には、多大なる計算時間がかかります。極端な話1つのGPUだけで学習していたら、いつまで経っても学習が終わりません。内部的なスケジュール事情としても出来るだけ短期間で終わらせたいという思いがありました。そこで、今回複数マシンでの並列学習にチャレンジしました。上記のモデル並列化はあくまで一つのマシンに複数GPUが載っていることが前提となりますが、今回は複数GPUが載っているマシンを複数台使う並列化を行いました。並列学習により、同じ時間でもより先の経過を見れるので、モデルの修正・改善を早く行うことができました。こちらの詳細については別記事にて投稿予定ですのでそちらを是非御覧ください。
4.4 モデルアーキテクチャの工夫
今回モデルを作るにあたって、ただ既存のGPTのモデルを使うのでなく、アーキテクチャにおいてもいくつか変更を加えました。GPT-2が出たのが2018年でその後出たGPT-3もモデルの構造自体は変わっていないので、その4年間にモデル自体の改善に関する研究も出ていたら参考にすべきでは?と考えました。具体的には今年2022年4月にGoogleから発表された PaLM(Pathways Language Model) などを参考にいくつか細かな改善をしました。 こちらの詳細については別記事にて投稿予定ですのでそちらを是非御覧ください。
PaLMに関するGoogleのブログ ai.googleblog.com
5 学習したGPTのアウトプット例
せっかくなのでGPTの出力例も一部ご紹介したいと思います。
5.1 失敗モデルたちの作品集
学習に失敗したモデルたちは時々恐ろしいアウトプットを作り出します。
'ロボットと人間の関係は、 」と、その言葉に「この国は、この国を滅ぼす」と答えている。' '東京オリンピックは、 」と、その言葉に「この国は、この国を滅ぼす」と答えている。'
何をインプットしてもこの国を滅ぼそうとしてくるようで非常に怖いモデルです
“遊戯王は、「お前の顔を見て、お前の顔を見て、お前の顔を見て、お前の顔を見て、お前の顔を見て、お前の顔を見て、お前の顔を見て、お前の顔を見て、お前の顔を見て、お前の顔を見て、お前の顔を見て、お前の顔を見て、お前の顔を“
こちらも非常に怖いです。
特に恐怖を感じたものをピックアップしましたが、GPTでは繰り返し、同じ文言を繰り返してしまう事象が時々発生します。 (繰り返し自体は再帰的な文書生成時のアルゴリズムによって回避は可能です)
5.2 完成モデルの出力例
苦難を乗り越え完成したモデルで文章を生成してみます。
2.7Bモデル
Input: 人とAIが共生するために今考えなければいけないことは、 Output: 人とAIが共生するために今考えなければいけないことは、「AIが人間の仕事を奪う」という考え方を捨てることです。
Input: AI開発で必要なことは、 Output: AI開発で必要なことは、「AIを使って何をしたいのか」という目的を明確にすることです。
6.7Bモデル
Input: テクノロジーが世の中に浸透するには、 Output: テクノロジーが世の中に浸透するには、「作る人」と「使う人」の両方の「心」の進化が必要です。私たちはテクノロジーが進歩する度に新しいテクノロジーの技術者を増やし、常にユーザーの視点に立った細かな工夫を凝らし続けてきました。
Input: 「愛とは何ですか?」と聞くと、 OUtput: 「愛とは何ですか?」と聞くと、答えは簡単。「まずは愛すること」。そして愛されること。答えはシンプルで、これに尽きます。
13Bモデル
Input: 100年後に必要とされる会社は、 Output: 100年後に必要とされる会社は、製品・サービスの開発力ではなく、多様化するニーズに対応したサービス・製品を生み出し、市場へ提供し、信頼を獲得することで、競争優位性を保つことができる‖攻めのIT企業‖です。
Input: 人とAIが協調するためには、 Output: 人とAIが協調するためには、空気を読む能力や、コミュニケーションを推進するために必要な情報が、人とAIに紐づいているといった「人間とAIのインターフェイス」を実現することが重要となる。
かなり自然ではないでしょうか。 そして哲学じみたことを語ったり、愛について説いてくれたりもするようです。
5.3 少しFine-tuningした結果
お試しで青空文庫の芥川龍之介の文章で一晩Fine tuningしてみました。
Input: 人と鬼が共生するためには、 Original GPT: 人と鬼が共生するためには、いったいどれほどの軋轢が必要なんでしょうか? 芥川龍之介GPT: 人と鬼が共生するためには、天上から加護を加えなければならぬ。
恥ずかしながら芥川龍之介について深く知らないですが、originalに比べると芥川龍之介っぽいのではないでしょうか。(もし芥川通の方の視点では全然違ったら申し訳ないです・・・)
6. 最後に
第二弾、第三段の記事も後日公開予定なので乞うご期待ください!
6.1 採用メッセージ
ABEJAでは幅広い業界のプロジェクトを扱っており、様々なデータに触れられます。ABEJAは画像系のイメージを持っている方も多いかもしれませんが、自然言語処理の分野にも取り組んでいます。お客様からの要望に従って分析・モデル構築するだけではなく、ゼロから解決策を検討・提案・実行できるところが、難しくもあり面白い所でもあります。幅広いだけでなく、深い知識も得られるよう、ナレッジシェアなどにも力を入れています。ちょっと話を聞いてみたい、もう少し詳しく知りたいなどありましたら、是非ともご連絡ください。 DSチーム、HRメンバー共々心よりお待ちしております。
6.2 ABEJAで学習したGPTモデルの今後について
今回作成したモデルは社内でも活用予定ですが、一部モデルについては現在一般公開に向けて準備中です(gpt-neoxを使うことで公開が少し複雑になっていたりします)。乞うご期待ください!また、ABEJAのメンバーとしてGPTの活用に関わりたい方や、ビジネスとしてABEJAの学習したGPTモデルを活用したい方からのご連絡もお待ちしております!
