 こんにちは!競馬愛が止まらず、昨年テックブログで競争馬に関する記事を公開してしまった、データサイエンティストの安倍(あんばい)と申します。社内では馬ニキと呼ばれています。
tech-blog.abeja.asia
こんにちは!競馬愛が止まらず、昨年テックブログで競争馬に関する記事を公開してしまった、データサイエンティストの安倍(あんばい)と申します。社内では馬ニキと呼ばれています。
tech-blog.abeja.asia
世はまさに大LLM時代。このウェーブに少し乗り遅れたなと思いつつ、専門であるレコメンドシステムと、LLMで何かできないだろうかと思い、執筆したのが本記事になります。本記事では主に以下の2点についてご紹介します。
- 既存のパーソナライズレコメンドモデルとLLMの統合についての設計、実装及び評価
- LLMを用いたレコメンドシステムのメリット、デメリット、実運用面での課題点
オープンデータを用いた、アニメレコメンドシステムを実装し、LLMに統合する過程で感じた、LLMならではの素晴らしさや、難しさや、課題感をお伝えすることができたらと思います。
目次
概要
本記事では、LLMを用いた対話型レコメンドシステムの構築を目指します。
ChatGPTや、その他既存のLLMは、学習に用いたデータのみを用いてレコメンドを行います。
例えば、GPT-4は2021年9月までの情報しかなく、それ以降のアイテム情報をレコメンドすることはできません。本システムでは、Retrieval DBと、協調フィルタリングやMatrix Factorizationなどの既存アルゴリズムを用いることで、この問題の解決を目指します。
システム概要図を見ていきましょう。
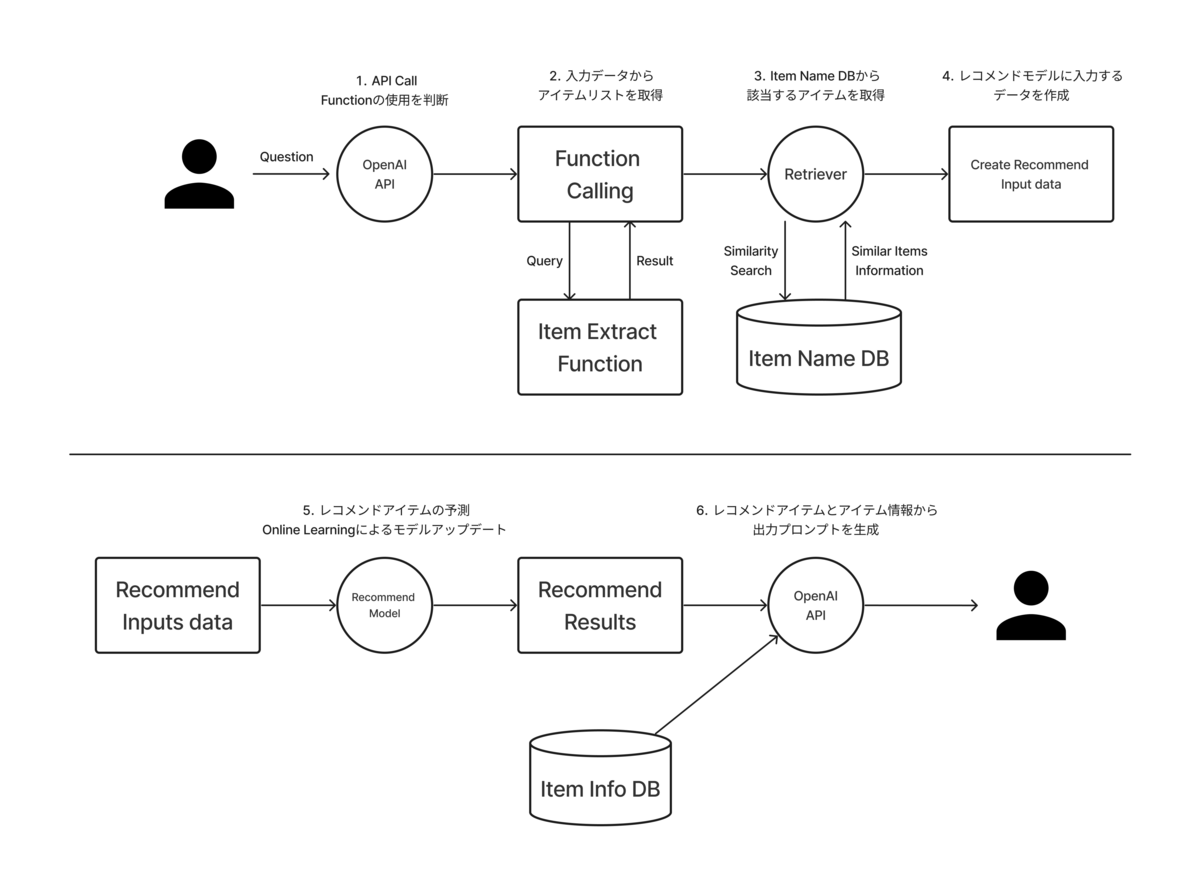
今回構築したシステムは、以下の入力形式を想定し、主に6つのステップを経て、レコメンド結果を取得します。
入力文章: おすすめの〇〇(作品や商品)を教えてください。 私が好きな〇〇(これまでに閲覧した作品や、所持している物)は以下の通りです。 - Item A, Item B, Item C ステップ: 1. OpenAI Function Callingを用いて、関数の利用を推定 2. ユーザの入力文章から、アイテム情報を取得する関数を実行 3. ItemDBから対象アイテムの情報を取得 4. レコメンドモデルに入力する情報を作成 5. レコメンドするアイテムを予測 6. 予測結果と商品情報を要約し出力
ステップ1〜4では、入力された文章から、レコメンドモデルに入力するデータを作成するための前処理を行います。ステップ4, 5では、前処理されたユーザ情報を元に、レコメンドするアイテムの予測を行います。最後に、ステップ6ではアイテムのメタ情報を含めて、LLMを用いて要約、出力を行います。
事前知識
本セクションでは、事前知識として、レコメンドシステムの基礎である協調フィルタリングと、Matrix Factorizationについて、簡単に説明をします。
ChatGPT、Retrievalについては、既に弊社Tech Blogにて公開されていますので、下記の記事をご覧下さい。 tech-blog.abeja.asia
協調フィルタリング (Collaborative Filtering)
レコメンドシステムの基本的な思想は以下の2点です。
- アイテムAを閲覧・購買したユーザは、アイテムBも閲覧・購買する傾向がある - アイテムAを閲覧・購買したユーザには、アイテムBをレコメンドする
この思想を最もシンプルに表現している代表的なアルゴリズムの1つが、協調フィルタリング (Collaborative Filtering)です。
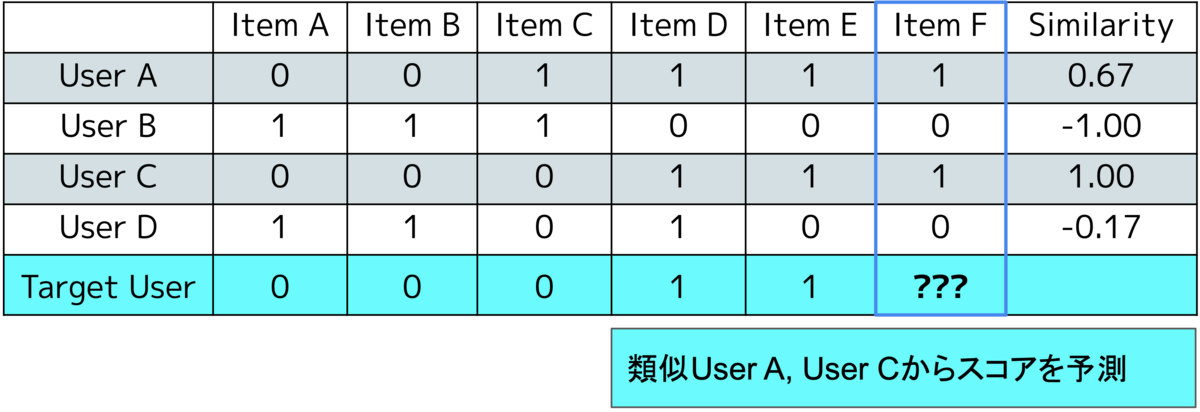
上記の表は、各ユーザが各アイテムを閲覧したかどうかを表します。
ここで、Target Userへレコメンドするアイテムについて考えていきましょう。 具体的には、Target Userが閲覧していないアイテム、Item Fをレコメンドするかどうかという問題を考えます。
まず初めに、Target Userの閲覧履歴と、各ユーザの閲覧履歴の類似度を算出します。類似度の計算にはコサイン類似度や、ピアソン相関係数、Jaccard係数等が使用されます。今回の例題ではピアソン相関係数を用いて類似度計算を行いました。
次に、Item Fのスコアを計算します。今回のような0,1の離散値であれば、類似度が高いTOP N件のユーザのVoting結果を予測値として扱います。0〜100の様な連続値であれば、加重平均を用いるなどして、予測値を算出します。
今回の例では、User AとUser Cが、類似度が高いユーザとなります。AとCはどちらもItem Fを閲覧しているため、Target UserにItem Fをおすすめするという結論になります。
協調フィルタリングはシンプルながらも、年齢や居住地といったユーザ属性、タイトルや値段などのアイテム情報を使わずに、レコメンドを作成することができるというメリットがあります。
Matrix Factorization
協調フィルタリングの例題では、ユーザ数が5件、アイテム数が6件という非常に小さなデータセットで説明を行いました。
現実世界での協調フィルタリングの利用について考えてみましょう。AmazonやYouTube、普段利用しているサービスを想像していただくと分かる通り、ユーザ数とアイテム数は数千から数万を超える規模で存在します。この高次元なデータ量の中で、ユーザ毎に類似度を計算し、レコメンドアイテムを算出するのは、非常に負荷の高い作業となります。そこで、次元削減を行うことで、より効率的なレコメンドの作成を可能としたのが、Matrix Factorizationです。
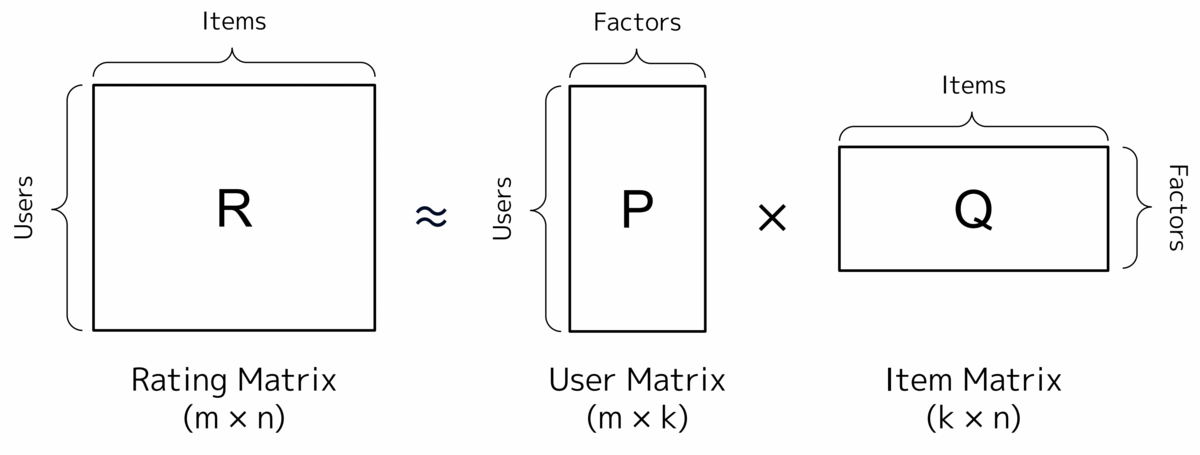
上記の図は、Matrix Factorizationの概要図です。Rating Matrix(評価行列)はm人のユーザ、n個のアイテムから構成されます。Matrix Factorizationではこれを、k次元()への次元削除を行い、各評価値の予測を行います。まず初めに、数式を見ていきましょう。
User Matrix(ユーザ行列) と、Item Matrix(アイテム行列)
のドット積の値が、Rating Matrix
を近似する様に学習を行います。
引用: Matrix Factorization-based algorithms — Surprise 1 documentation
は実際の評価値を表し、
が予測値を表します。実測値と評価値の二乗誤差を最小化するよう、SGD(確率的勾配降下法)を用いて学習を行います。
サンプルデータを用いて、アルゴリズムの流れを確認してみます。
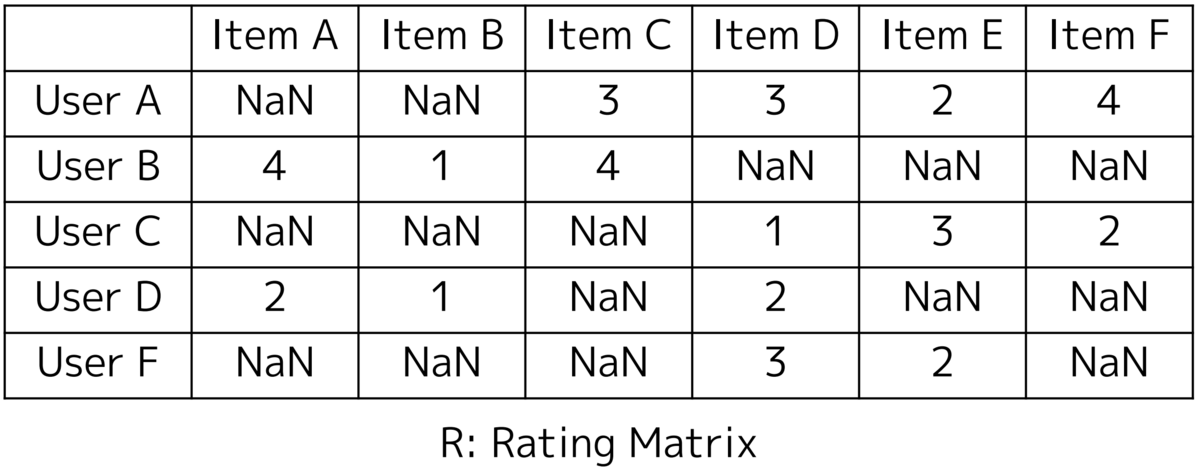 協調フィルタリングで説明した例題を、各アイテムのスコアを1〜5点で評価したものに改変しました。0は未評価と見なし、NaNに置き換えています。
協調フィルタリングで説明した例題を、各アイテムのスコアを1〜5点で評価したものに改変しました。0は未評価と見なし、NaNに置き換えています。
この評価行列を近似するために、まずはUser Matrix
と、Item Matrix
をランダムな値で作成します。今回の例では潜在変数のサイズを3に設定しています。
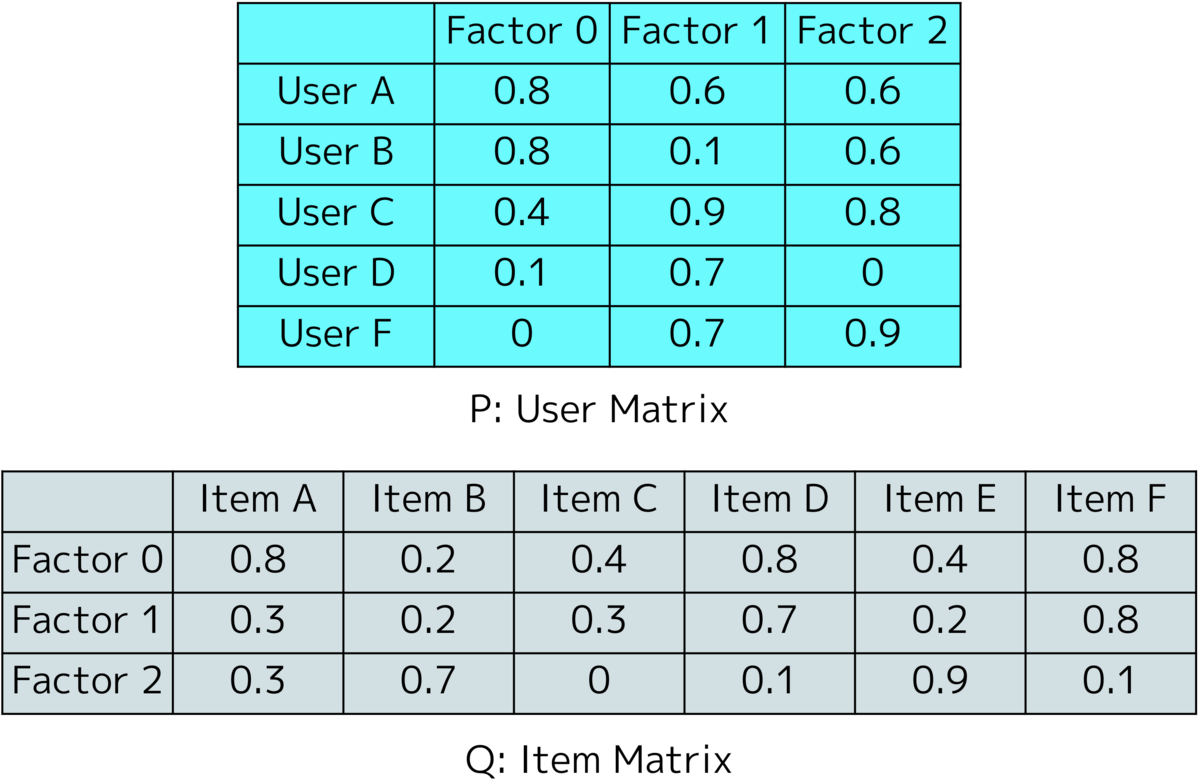
それでは評価値の推定を行ってみましょう。例として、User AのItem Cのスコアを推定します。
- User AのItem Cのスコア r: 3 - User AのUser Matrix特徴量 p: [0.8, 0.8, 0.6] - Item CのItem Matrix特徴量 q: [0.4, 0.3, 0.0]
評価値はとなります。
二乗誤差はとなり、この誤差を最小化するように学習を行います。
学習率を0.1とし、正則化項
は一旦無視をして、各潜在変数の値を更新してみます。
の更新例:
同様の処理を全ての値に適応し、繰り返していくことで近似行列を得ることができます。これ以降全て手作業は厳しいので、scikit-learnのNon-Negative Matrix Factorization (NMF)を使い、計算してみます。
from sklearn.decomposition import NMF model = NMF(n_components=3, init="random", random_state=0) P = model.fit_transform(X) Q = model.components_ approx_df = pd.DataFrame(np.dot(P, Q)) approx_df = approx_df.apply(lambda x: round(x, 1))
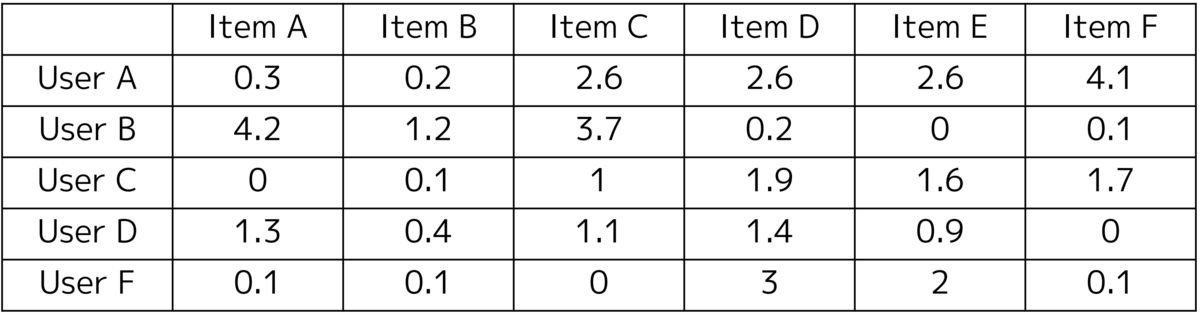
いかがでしょうか。評価行列と類似した行列を得ることができました。説明の都合上割愛しましたが、実際にはバイアス項や正則化項を導入するのが一般的です。
レコメンドシステムの実運用について
レコメンドシステムはECサイトやSNS、動画配信サイトや、スマートフォンアプリ等、様々な場所に導入されています。
今回ご紹介した協調フィルタリングやMatrix Factorizationといった技術はもちろんのこと、ディープラーニングを用いた、より高度なパーソナライズアルゴリズムや、コンテツベースと呼ばれる商品メタ情報を用いた手法、ルールベースのような簡易的なモデルなど、様々なアルゴリズムが採用されています。アルゴリズムの選定は、保有するデータの内容や、データ量、達成したい目的に応じて行います。
運用方法については、大まかに、バッチ処理とリアルタイムの2つに分類されます。
バッチ処理は、日次や週次といった単位で、事前に決められた件数のレコメンドリストを作成しておく方法です。ページを更新した際にレコメンドされるアイテムの顔ぶれが変わらない場合や、メールマガジンで送信されるもののほとんどが、バッチ処理で作成されたレコメンドです。
一方リアルタイムでは、ユーザの行動履歴を元に、即時にレコメンドリストの作成を行い出力します。ページを更新した際に表示されるコンテンツが違う場合は、リアルタイムレコメンドである可能性があります。(バッチ処理されたレコメンドリストをランダムに表示している可能性もありますが。)
リアルタイムレコメンドは、ユーザが利用するたびに、様々なアイテムをレコメンドすることができるため、一見よさそうに聞こえます。しかし、ユーザのログを取得し即時に予測・フロントページに表示する必要があるため、運用パイプラインはバッチ処理に比べ、非常に複雑になります。アルゴリズムの選定と同様に、様々な観点からどちらを採用するかを決定します。
レコメンドモデルの作成
LLMレコメンドシステムの難しさ
さて、ここらは実践編になります。実際にレコメンドモデルの作成を行います。
今回、モデルの設計を行うに伴い、最も重要となるのは、LLMを用いた対話型レコメンドであるという点です。バッチ処理、リアルタイム、LLMの比較をしてみましょう。
| バッチ処理 | リアルタイム | LLM | |
|---|---|---|---|
| 入力 | ユーザ行動ログ (クリック、購買など) |
ユーザ行動ログ (クリック、購買など) |
不定形な文章 |
| 出力 | レコメンドリスト (IDリスト) |
レコメンドリスト (IDリスト) |
文章 |
| 即時性 | 不要 | 必須 | 必須 |
| バリエーション | 作成されたレコメンドのみ | ユーザ行動により変化 | ユーザ入力文により変化 |
比較表より、少なくとも、以下の4つはクリアするべきハードルとなります。
- LLMは対話型という性質上、不定形な文章しか得られず、学習データに変換する必要がある
- 出力も文章であるため、出力プロンプトの設計や、要約が必要である
- 対話型のため、リアルタイムでレコメンド生成を行わなければいけない
- 入力文章に応じたレコメンドをしなければいけない
3,4の実現のため、Online Learningを用いてレコメンドモデルの作成を行います。1, 2については、LLMとの統合のセクションにてご紹介致します。
Online Learning
Online Learning(オンライン学習)は、ストリーム形式で取得されたデータを用いて、モデルを逐次更新する学習手法です。データ全てを用いて学習するバッチ学習とは異なり、1つのデータを用いて、学習を行います。今回は、PythonのOnline Learning用ライブラリRiverを用いて、Matrix Factorizationの実装を行います。 github.com
データセット
データセットは、Kaggle Datasetから、Anime Recommendation Database 2020を使用します。17,562件のアニメ情報と、325,772名のユーザの評価が含まれる、非常に規模の大きいデータセットです。これを用いて、ユーザにパーソナライズされた、アニメレコメンドモデルを作成します。 www.kaggle.com
実装と定性評価
それでは、Riverを用いてモデルの学習を行います。前処理については割愛し、学習部分のコードのみをご紹介します。GitHubに全てのコードをアップしておりますので、興味がある方は併せてご覧ください。
# Matrix Factorization parameters func_mf_params = { "n_factors": 10, "optimizer": optim.SGD(0.01), "initializer": optim.initializers.Normal(mu=0.0, sigma=0.1, seed=73), "l2": 0.1, } # Define model and metrics model = reco.FunkMF(**func_mf_params) metric = metrics.MAE() + metrics.RMSE() # Online Learning for x, y in dataset: y_pred = model.predict_one(user=x["user_id"], item=x["anime_id"]) metric = metric.update(y["rating"], y_pred) model = model.learn_one(user=x["user_id"], item=x["anime_id"], y=y["rating"]) print(metric) MAE: 0.264245, RMSE: 0.360384
学習コードはscikit-learnライクなインターフェースとなっており、非常に簡単に記述することができます。
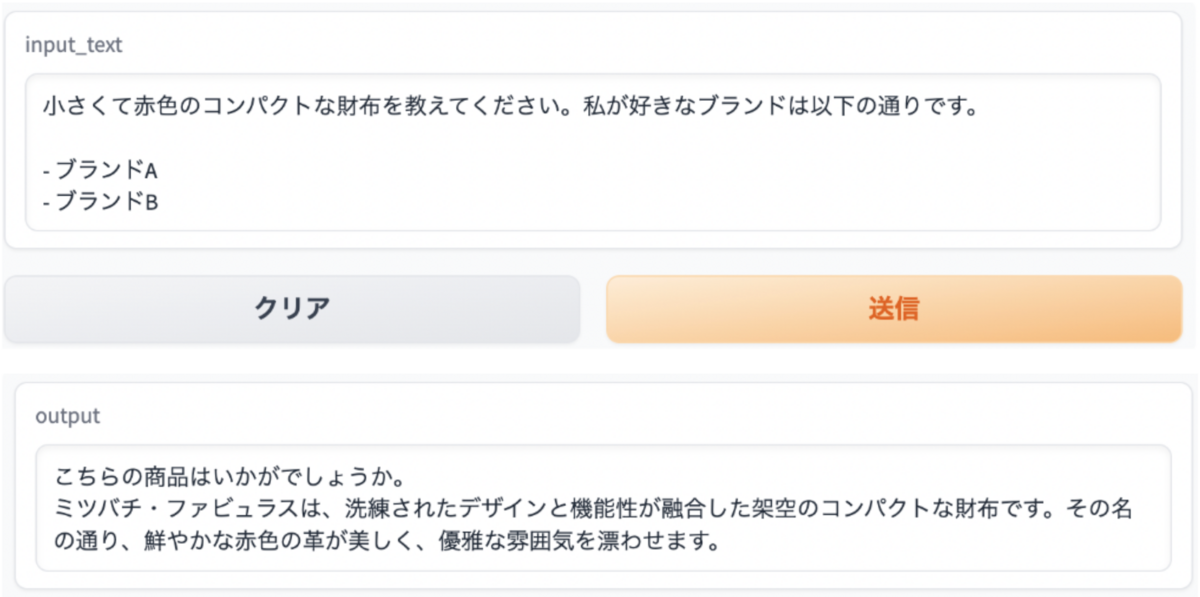
それでは、定性評価を行います。最も簡単な定性評価は、自分が好きな情報をモデルに入力し、自分が気に入る結果がレコメンドされるかを確認することです。
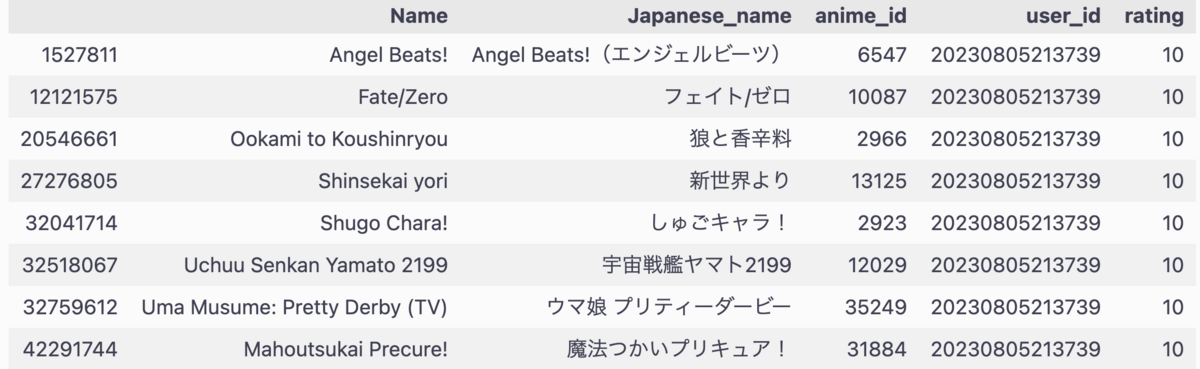
無事、筆者の嗜好が全世界に公開されました。これをテストデータとして、レコメンド結果を見ていきます。
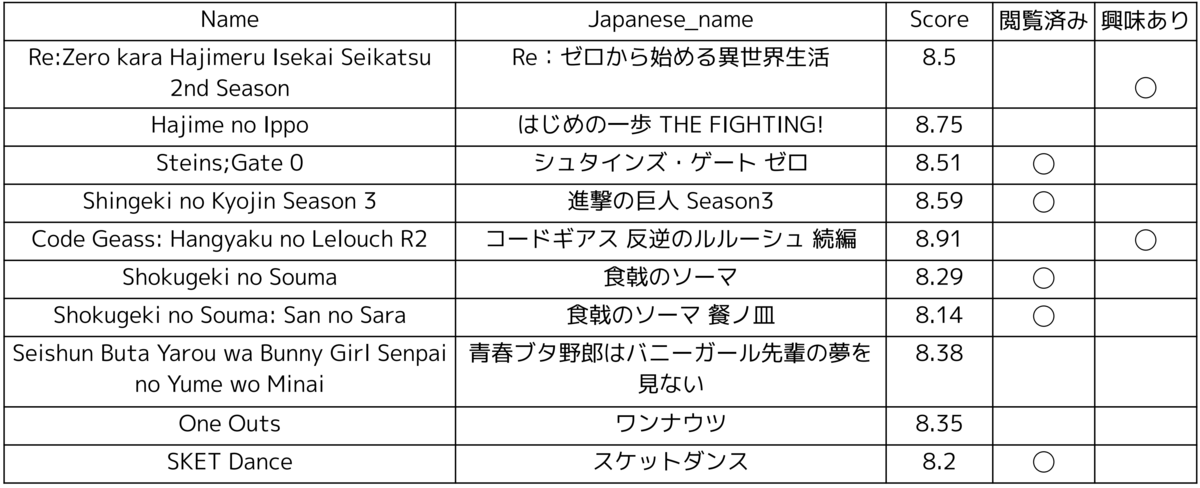 スコア上位10件の結果がこちらとなります。閲覧済み作品(アニメまたは漫画で閲覧)は5件、見たことはないが、興味がある作品は2件と、7/10が興味ある作品であるため、品質としては問題なさそうです。同じシリーズの作品や、同じ出版社の作品が出ていそうなど、改善余地はありそうですが、今回の目的はLLMでの利用のため、一旦はこのモデルをLLMに統合していきます。学習コードも公開していますので、興味がある方は、是非モデルを作成し、自身のレコメンド結果を確認してみてください。フィードバックお待ちしております。
スコア上位10件の結果がこちらとなります。閲覧済み作品(アニメまたは漫画で閲覧)は5件、見たことはないが、興味がある作品は2件と、7/10が興味ある作品であるため、品質としては問題なさそうです。同じシリーズの作品や、同じ出版社の作品が出ていそうなど、改善余地はありそうですが、今回の目的はLLMでの利用のため、一旦はこのモデルをLLMに統合していきます。学習コードも公開していますので、興味がある方は、是非モデルを作成し、自身のレコメンド結果を確認してみてください。フィードバックお待ちしております。
LLMとの統合
ここまではステップ5で用いる、レコメンドモデルの作成についてお話しをしてきました。本セクションでは、LLMとの統合について説明をしていきます。
Function Callingを用いたアイテムリストの取得
Step1, 2では、ユーザの入力文章から、ユーザが好むアイテムリストの取得を目指します。
ユーザ入力例文: おすすめのアニメを教えてください。私が好きなアニメは以下の通りです。 - Angel Beats! - Mahoutsukai Precure! - Ookami to Koushinryou - Shinsekai yori - Shugo Chara! - Uma Musume: Pretty Derby (TV) - Fate/Zero - Uchuu Senkan Yamato 2199
具体的には、上記のような文章からアイテム名を抽出し、Pythonリスト["Angel Beats!", "Mahoutsukai Precure!", "Ookami to Koushinryou".....,'Uchuu Senkan Yamato 2199']を取得します。
このリストを取得するために、OpenAI Function Callingを利用します。Function Callingは非構造なテキストデータから、構造化されたデータを抽出することが可能です。いちいち「このテキストから、アニメの名前を抽出し、Pythonのリスト形式で出力して。」とお願いをせずとも、高い精度で欲しいデータを出力してくれる便利機能です。それでは、実際のコードと、結果を見てみましょう。期待された結果が取得されているのが分かります。
# アニメ名を取得し、リスト形式で返却する関数 def get_anime_name(anime_name): anime_list = anime_name.split("\n") anime_list = [anime for anime in anime_list if anime] return anime_list # Function Callingに与える関数情報 functions = [ { "name": "get_anime_name_list", "description": "入力文章から、アニメ名のリストを作成する。", "parameters": { "type": "object", "properties": { "name": { "type": "array", "description": "アニメ名", "items": {"type": "string"}, } }, "required": ["name"], }, } ] # Function Callingの実行 response = openai.ChatCompletion.create( model="gpt-4", messages=[ {"role": "user", "content": prompt}, ], functions=functions, function_call="auto", temperature=0, ) message = response["choices"][0]["message"] candidate_list = json.loads(message["function_call"]["arguments"])["name"]
出力結果: candidate_list ['Angel Beats!', 'Mahoutsukai Precure!', 'Ookami to Koushinryou', 'Shinsekai yori', 'Shugo Chara!', 'Uma Musume: Pretty Derby (TV)', 'Fate/Zero', 'Uchuu Senkan Yamato 2199']
Retrieval用DBの作成と結果取得
次にRetrieval用のDBを作成します。システム概要図からも分かる通り、Item Name DBと、Item Info DBの2つのDBを作成しました。
Item Name DBは、入力文から取得されたアイテム名の名寄せを行います。
ユーザがアイテム名を直接入力する仕様上、どうしてもスペルミスや、大文字小文字の区別、記号の有無など、正しいアイテム名とは異なる形式で入力されることが予想されます。 そのため、事前にアイテム名をベクトル化したDBを作成し、名寄せを行うことで、この問題を解決します。
ベクトルDBの作成にはFaissを利用しました。DBを作成し、テストデータを用いて、最も類似度が高い作品を確認してみます。 github.com
# テストデータ test_anime_list = [ "AngelBeat", "Ookami to Koushinryo", "鬼滅の刃", "Kimetsu no Yaiba", ] for anime in test_anime_list: check_similarity_item(anime_name_db, anime) # 類似度(0に近いほど距離が近い) angel beats! 0.22996305 ookami to koushinryou 0.16843092 queen's blade: gyokuza wo tsugu mono 0.31180137 kimetsu no yaiba 0.12329282
正しく名寄せできていることが確認できました。今回は英語名のみを用いてDBの作成をしたため、日本語の「鬼滅の刃」については誤った結果を取得しています。 決め打ちとはなりますが、類似度が0.3を超えるデータは、使用しない設計としました。(新しいアイテムとしてDBに登録するといった処理を加えてみるのもの良いかもしれません。)
余談にはなりますが、英語と日本語を混ぜたDBの作成も行い、同様の実験を行いました。残念ながら、こちらは非常に精度の低い結果となり、Retrieval DBの作成の難しさを知ることとなりました。英語のみにおいても、文字を小文字に統一するなどして、精度向上の工夫をしています。
Item Info DBについては、レコメンドリストに、アイテムのメタ情報を付与して出力することを目的に作成しました。Item Name DBの内容に加え、作品ジャンル、作品概要を追加しています。
レコメンドリストの作成と結果の出力
名寄せされたアイテム名を取得することができたため、これを用いてレコメンドリストの作成を行います。
今回、レコメンドモデルの作成に使用したデータセットでは、ユーザが視聴したアニメに対し、0〜10点で評価を行っています。システム利用者が、わざわざ嫌いな作品を入力しないだろうという仮定の元、最高得点の10点を一律に付与しレコメンドアイテムの予測を行います。レコメンド実装で紹介した、テストデータに対するレコメンド結果に加え、Item Info DBから、各アニメの情報を取得し、LLMで要約を行います。使用したプロンプトは以下の通りです。
template_recommend = """You are anime recommender system. Follow the Output rules and introduce the anime in the Recommend Lists. # Recommend Lists - {input} # Output rules - Show anime name, genere and descriptions. """
{input}がレコメンド結果のアイテム名のリストになります。このリストに対し、アニメ名、ジャンル、概要を加えて紹介を行います。最後に、以下のプロンプトで日本語翻訳したものを、最終結果としてユーザに出力します。
template_translate = """あなたはアニメをおすすめするレコメンドシステムです。 以下の英語の文章は、アニメの紹介をしています。日本語に翻訳、意訳してください。 -- - {english_result} """
通常のレコメンドシステムであれば、レコメンドリストのIDを元に、フロントページにアイテムを表示するだけですが、追加の情報を加えた紹介文章の作成や、翻訳ができるのは、LLMの魅力の1つですね。それでは出力結果を見てみましょう。
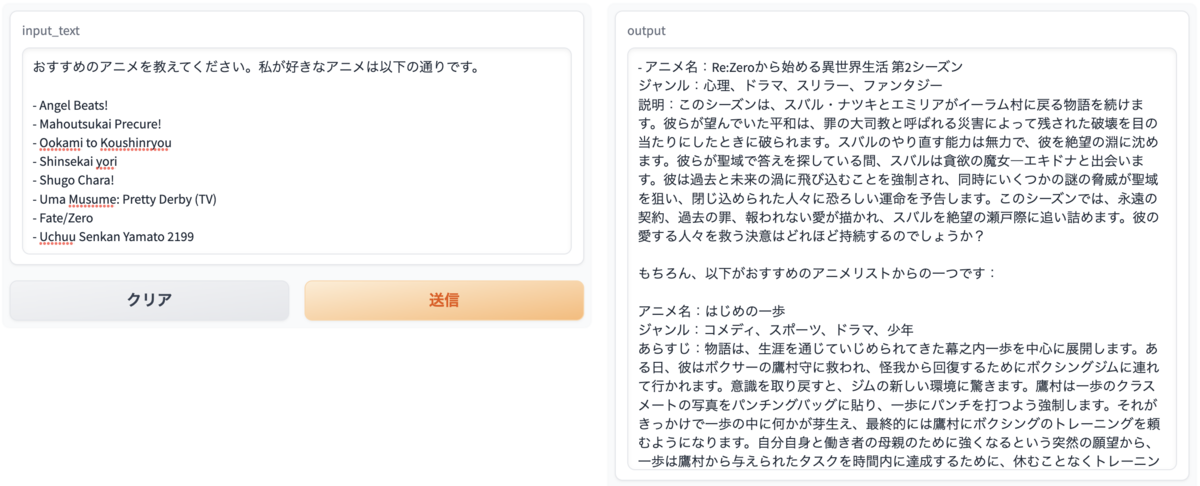
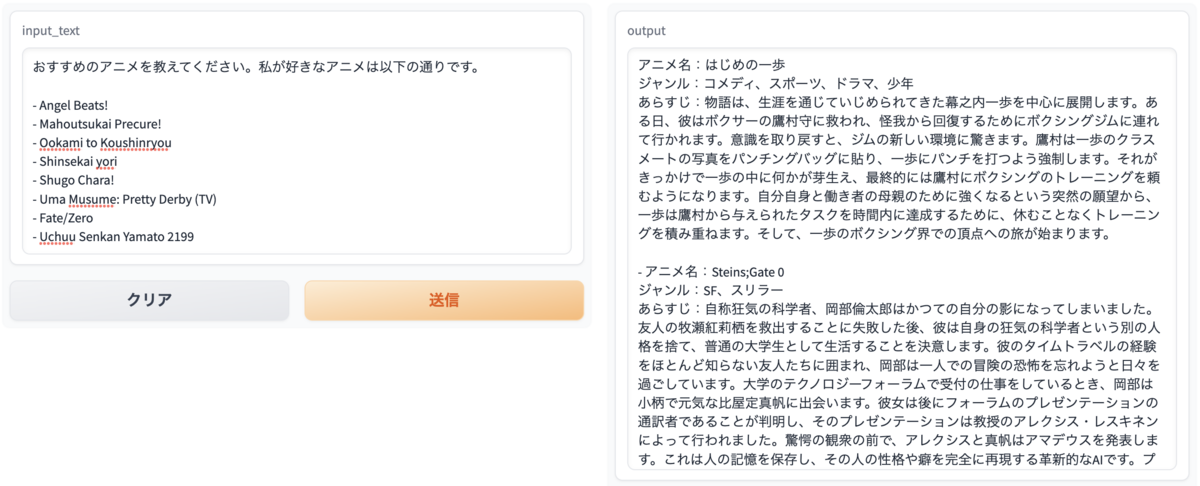
Web UIはGradioを使用し作成をしました。アニメ名に加え、ジャンルと概要を加えたレコメンドが出力されました! www.gradio.app
ChatGPTとの比較
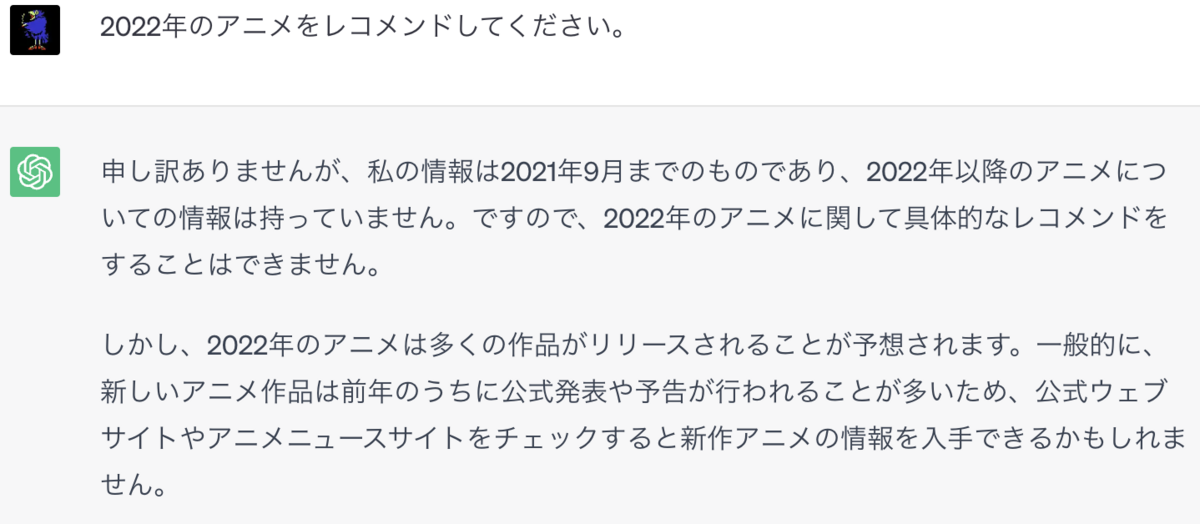
レコメンド結果の評価のため、ChatGPT (GPT-3.5)にも同様の文章を入力し、結果を確認してみます。

予想よりも、ちゃんとしたレコメンドが返ってきました。Matrix Factorizationでもレコメンドされた、STEINS;GATEシリーズが出ているのは驚きです。
一方で、ジャンル情報が欠落していたり、概要が非常に短いといった違いが出ました。また、2021年9月までのデータで学習されているため、それ以降の作品については、やはりレコメンドされることはありませんでした。今回作成したシステムは、最新の作品を考慮しやすく、より詳細なアニメ情報を付与できることが最大の強みと言えそうです。
LLMレコメンドシステムの強みと弱さ
最後に、システムを実装していく中で感じた、LLMレコメンドのメリットとデメリットをまとめたいと思います。
メリット
インタラクティブ性
従来のレコメンドシステムの多くは、ユーザのアクセスログやクリックログなど、無意識のうちに行動した、暗黙的なログを使用して学習を行います。 これに対し、LLMレコメンドシステムは対話型のため、ユーザが明示的にデータを入力することができます。そのため、ユーザは従来と比較し、よりインタラクティブにシステムを利用することができます。
柔軟なレコメンド結果
従来のレコメンドシステムのゴールは、レコメンドするアイテムの予測でした。システム的に言い換えると、レコメンドするアイテムのIDを出力し、そのIDを参照し、Webページにアイテムを表示したり、メールマガジンを作成します。LLMを取り入れることで、LLMが得意な文章生成はもちろん、要約や翻訳、検索など、様々なタスクを組み合わせることができます。そのため、柔軟かつ、よりユーザにパーソナライズされた出力を得ることが可能です。
デメリット
入力文章の柔軟性が低い
Function Callingを用いることで構造化された情報が取得できる、と言いつつも、ある程度決められた入力形式に従う必要があります。今回のようなフリーな入力形式では、適切な結果を得られない可能性や、想定外のエラーが発生する可能性が高いため、一定の制限を考える必要があります。
DBに無い情報や、想定外の質問には対応できない
当然ですが、ベクトルDBに無い情報は扱うことができません。作品名程度であれば、事前に類似度の閾値を設定し判断したり、検索を行うなどして、DBに登録することは可能かもしれません。しかし、LLM特有の「もう少し〇〇なものをレコメンドして」のような、追加の質問には対応ができません。言い換えると、ユーザが好むアイテム名以外の情報は扱うことができません。そのため複数のパターンを想定し、場合によってはコンテンツベースのレコメンドや、ルールベースのレコメンドなど、複数モデルを準備する必要があります。
レスポンス速度
LLMレコメンドのデメリットというよりも、今回設計したシステムの一番の問題点がレスポンス速度です。文章を入力してから出力が返ってくるまでに、何と、驚愕の約3分。とても実運用できるレベルではありません。
最も時間がかかる処理が、レコメンド結果の要約と翻訳です。文字数の指定や、プロンプトの変更、Retrieval DBの構造化の見直しなど、改善ポイントは多く存在しそうです。また、モデルや関連ファイルのロードについても、プログラムを実行する度に行うため改善の余地があります。
終わりに
最後までご覧いただきありがとうございました!本記事ではLLMレコメンドシステムの実装及び評価を行いました。 LLMならではの強みを活かすことができる一方で、運用面については多くの課題が見受けられました。これらの内容が、少しでも何かの参考になれば幸いです。
LLMの登場により、レコメンドシステムの在り方が大きく変わるのではないかと、個人的には考えています。これまでは、利用したサービス側が取得した行動ログをベースに、レコメンドを作成していました。これは、WEBサービスならではの構造ですが、今後は、実店舗でもレコメンドシステムが導入されるのではないかと考えています。
例えば、画像認識を用いて、着用している服を分析し、その場でおすすめの商品をレコメンドしてくれる世界が来るかもしれません。気に入らなければ、その場で「もっとこうして!」と言えば、音声認識を用いて文字起こしを行い、LLMに入力し、新たなレコメンドを作成してくれます。こんなに面白くて、ゆたかな世界を実装していきたいですね。
本記事で実装したコードは、GitHubにて公開しております。また、Twitterにて情報を発信しておりますので、合わせてご確認頂けたらと思います。最後までお付き合い頂き、ありがとうございました。 github.com twitter.com
採用情報
ABEJAでは一緒に働く仲間を募集しています!ご興味がある方は、是非、採用ページをご確認下さい! careers.abejainc.com
