
こんにちは!株式会社 ABEJA で ABEJA Platform 開発を行っている坂井(@Yagami360)です。世間では ChatGPT などの大規模言語モデル(LLM)による対話型 AI が盛り上がってますね。クオリティーも凄いし AI 業界以外でも盛り上がってると嬉しいですよね。この数年で一段と AI の社会実装が業界以外の人にも目に見える形で進んできたなあと実感しております。
自分は普段業務では ABEJA Platform という AI プロダクトやその周辺プロダクトのバックエンド開発とフロントエンド開発をやっているのですが、AI 業界所属していながら ChatGPT などの LLM 全然追いかけれていない状態になっちゃてて自責の念にかられているので、このブログ執筆という良い機会に ChatGPT の仕組みについて調べてみました。
本記事の対象読者としては、以下のようになります
- ChatGPT の基本原理から知りたいけど、自然言語処理(NLP)も強化学習も知らない。
- 但し、ディープラーニングはある程度詳細レベルで知っている。線形代数程度の数学も知っている
本記事では、ChatGPT の原理や仕組みの説明に終始しており、ChatGPT の使い方や OpenAI API の使用方法、ChatGPT の改良方法等の話は一切記載していません。
ChatGPTを使って見つつも基本原理からきちんと理解しておくことで、対話型 AI の課題や今後の進歩の方向性・実現可能性等を誰かがそう言ってたとかいう理由じゃなくて、自分なりに考察できるようになるメリットがあると思ってます。

ChatGPT を理解するにあたっては、上図ロードマップのように自然言語処理(NLP)と強化学習の2つの分野を理解する必要があります。少々長い道のりになりますので記事を前編と後編に分けました。
前編記事では、自然言語の基礎から Transformer → GPT-3 → GPT-3.5 までを説明します。
後編記事では、強化学習の基礎から PPO までを説明した上で、メインコンテンツである InstructGPT → ChatGPT を説明します。後編記事は以下にあります。
自然言語処理と強化学習の長い歴史を振り返っていくので長い記事になっちゃってますが、お付き合い頂けると幸いです
- 自然言語処理(NLP)の基礎事項
- Transformer
- GPT-1
- GPT-2
- GPT-3
- GPT-3.5
- 後編へ続く・・・
- 採用情報
自然言語処理(NLP)の基礎事項
自然言語処理(NLP)とは、日本語や英語のような人間が扱う言語(自然言語といいます)をコンピューターで扱う際に如何に処理させるかの技術分野です。ChatGPT のような対話型 AI も広い分野でみるとこの技術分野に属します。
NLP における one-hot ベクトル表現
自然言語処理(NLP)における全ての大前提として、自然言語における文章や単語をニューラルネットワークやディープラーニングなどの機械学習モデルで扱うためには、当然ながら文章や単語を計算可能な形で表現する必要があります。NLP においては、自然言語における文章や単語を one-hot ベクトル表現という形で計算可能な形で表現します。
この NLP における one-hot ベクトル表現というのは具体的には、例えば「今日は天気が良い」という文章があったときにそれぞれの単語を
- 「今日」⇒ (1, 0, 0, 0, 0)
- 「は」⇒(0, 1, 0, 0, 0)
- 「天気」⇒ (0, 0, 1, 0, 0)
- 「が」⇒ (0, 0, 0, 1, 0)
- 「良い」⇒(0, 0, 0, 0, 1)
という風に各単語を一意のベクトルで表現する方法です。*1
各単語をベクトルとして計算可能な形にすることで、各単語(のベクトル表現)をニューラルネットワークやディープラーニングなどの機械学習モデルの入力データとして入力できるようになります。
但し、単語を one-hot ベクトル表現するだけでは、one-hot ベクトルに各単語の意味や各単語の概念の類似性をもたせることができないという問題が出てきます。
単語の分散表現(埋め込み表現)
NLP においては、上記単語の one-hot ベクトル表現における問題を解決するために one-hot ベクトルを更に単語の分散表現(=埋め込み表現)という方法で、埋め込みベクトルに変換します。
これは単語の one-hot ベクトルを更に別のベクトル空間に埋め込む変換なのですが、具体的には、以下の式のように単語の one-hot ベクトルを埋め込み行列で変換することで、埋め込みベクトルに変換する操作になります。

各単語を埋め込みベクトルに埋め込むことで、以下の図のように埋め込みベクトル空間上で各単語の近い遠いといった距離の概念や類似度、加算減算といった構造を与えることができるようになります。
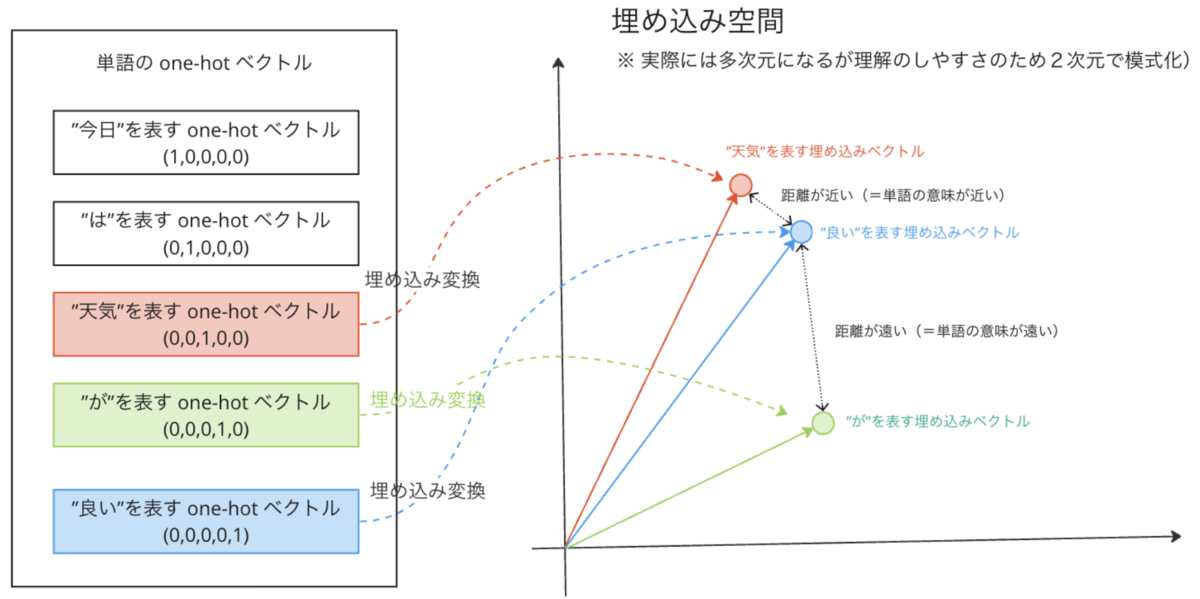
問題はこの単語をうまく表現できる埋め込み行列を如何に獲得するかというという話になるのですが、これはニューラルネットワークやディープラーニングモデルにおける埋め込み層とよばれる入力層で適切な学習を通じて獲得することになります。詳細は後段で説明します
言語モデル(LM : Language model)
ここまでは、NLP の大前提として、文章や単語如何に計算可能な形で扱うかの話を先にしておきましたが、ここからは本題の NLP で扱うモデル自体の話に移っていきます。
大規模言語モデル(LLM)や ChatGPT にしろ NLP における自然言語モデルは、言語モデル(LM : Language model)というのをベースにしています。
この言語モデル(LM : Language model)というのは、人間が扱う自然言語(日本語、英語など)の文章を、その文章が生成される確率で数理モデル化したものです。
これは、大雑把にいうと「”今日” “は” “天気” “が” “良い”」という意味が通じる自然な文章には高い確率を与えて、「”今日” “を” “良い” “天気”」という不自然な文章には低い確率を与えるというものです。
具体的には、言語モデルではある文章 の生成確率
を考えるのですが、その文章
は、以下の式のように各単語の one-hot ベクトルの連結で定義されます。但し、文章
が1つの文章として完結していることを表すために BOS と EOS という仮想文字も文頭と文末に連結します。
: BOS [Beggining Of Sequence]。文頭を表す仮想文字
: 各単語の one-hot ベクトル
- 例えば、「今日は天気がよい」という文章の場合は、
,
,
,
,
といった具合
- 例えば、「今日は天気がよい」という文章の場合は、
: EOS [End Of Sequence] 。文末を表す仮想文字
例えば、「今日は天気がよい」という文章があったときに「今日」「は」「天気」「が」「良い」という単語の羅列に分解した上でそれぞれを先に説明した one-hot ベクトルで表現し、それら one-hot ベクトルのリストと BOS, EOS を連結したものが文章 Y になります。
その上で言語モデルでは「文章の各単語の生成確率 は、その前後に出現した単語や単語列のみに依存する」という仮定を行います。
この仮定を行うことで、例えば という文章の場合は、文章
の生成確率
が、以下の式のように条件付き確率の積で定式化できます。
これを一般化すると、最終的に言語モデル(=文章の生成確率 )は以下の式で定式化できます。
: 単語の位置
よりも前に出現した
個の単語列
ここで重要なことは言語モデルは、あくまで自然な文章に高い確率を与えているだけで文章の真偽性や倫理性などは考慮していないという点です。ChatGPT では学習用データセットのアノテーションや強化学習による手法で有益性・真実性・無害性向上のための改善を行っていますが、そもそもこの言語モデルをベースにしているのでこれら問題がクリアできていません。他の LLM モデルにしろ言語モデルをベースにしている限りこれらの問題を完全にクリアすることはできないと個人的には思ってます(そもそもディープラーニング自体が確率的なモデルなのでその時点で 100% の真偽性や倫理性は原理的に無理な話ですが、、、)
言語モデルとニューラルネットワーク(ディープラーニング)
上記の言語モデルは、ニューラルネットワークやディープラーニングによってうまくモデル化できます。
そのことがわかりやすいように、単純なニューラルネットワークである多層パーセプトロンで言語モデルを如何にモデル化しているかを見ていきます

上図は、言語モデルを多層パーセプトロンで表現したものになっています。実際にはこんな単純なモデルではうまく文章を生成できませんが、わかりやすい説明のためにこのモデルが完璧に学習されているものとします。
このモデルでは、以下の手順で推論処理が行われます。
-
生成したい文章(この例では「”です”」)の前の単語リスト(この例では「”今日” ”は” ”天気” ”が” ”良い”」)それぞれの one-hot ベクトルを入力層に入力する。
-
入力層としての埋め込み層により、各単語の埋め込みベクトルを獲得する。
先に説明した単語の分散表現(埋め込み表現)を獲得するための埋め込み層というのは、この多層パーセプトロンでの例のようにニューラルネットワークやディープラーニングの入力層として実現されます
-
出力層で次の単語の出現確率を出力する。
このモデルが適切に学習されていれば、「”です”」が 0.84 という最も高い出現確率で出力され次の単語となります。
上記処理を今度は「”今日” ”は” ”天気” ”が” ”良い” ”です”」を入力して繰り返し、「”ね”」が最も高い出現確率で出力され次の単語となります。そして最終的に「”今日” ”は” ”天気” ”が” ”良い” ”です” ”ね”」という文章が生成される動作となります。
この動作は、生成した単語の前 C 個の単語のみを入力し、多層パーセプトロンを用いて、t 番目の単語の出力確率を繰り返し計算していることになるので、式で書くと
となります。これは言語モデルの式と同じなので、言語モデルはニューラルネットワークやディープラーニングによってうまくモデル化できることになります。
Transformer
ここからは Transformer*2について説明していきます。
Transformer は、従来の基礎的なネットワーク構造のモデル(CNN や RNN 等)と比較して学習用データセットとして大量のデータが必要というデメリットはあるものの、この数年前登場して以来 NLP の分野で革命をもたらした基礎モデルになっていて、近年の 大規模 LLM は全てこの Transformer とベースとしている超重要なモデルになっています。勿論 ChatGPT に関しても この Transformer をベースとしています。*3
Transformer が登場する以前は、自然言語処理(NLP)のタスクにおいて、seq2seq モデル*4のような encoder-decoder 構造を持つ RNN ベースのアーキテクチャが広く採用されていました。しかしながらこのモデルでは LSTM *5のような長期記憶構造を用いても変換精度が低い問題や学習時間が長いという問題が存在しました。attention 構造付き seq2seq モデル*6では、このような問題を解決するために入力系列のどの要素を重要視するかという attention 構造を導入していますが、依然として RNN 構造は残っているモデルになっています。
Transformer では、この attention 構造付き seq2seq モデルの RNN 構造を全て排除し、attention 構造のみ*7をもつような encoder-decoder モデルになっています。
そしてこの attention 構造により、翻訳タスクにおける変換精度と学習速度ともに従来のモデルからの大幅な向上を実現しています。
アーキテクチャの全体像

上図は、Transformer のアーキテクチャの全体像を示した図です。
Transformer は、左側の赤枠を encoder とし右枠の青枠を decoder とする encoder-decoder モデルになっています。encoder, decoder それぞれの内部構造は以下のようになります。
- encoder
encoder 側では、翻訳前の文章(例えば「”今日は天気が良い”」)を入力し、入力文章の各単語の埋め込み出力を decoder に入力します。具体的には、以下の処理が行われます
- 翻訳前の文章(例えば、「”今日は天気が良い”」)の one-hot ベクトルを、埋め込み層で単語の埋め込みベクトルに変換する
-
上記埋め込みベクトルに対して Positional Encoding(位置エンコード)で単語位置に応じた値を加算することで、間接的に単語の順番情報を加味する。(※ Positional Encoding についての詳細は、後述します)
-
上記単語の順番情報を加味した埋め込みベクトルに対して、{Multi-Head Attention → 残差接続 & 正規化レイヤー → Position-wise Feed-Forward Networks → 残差接続 & 正規化レイヤー}から構成されるレイヤーを N=6 回積み上げたネットワークで処理し、各単語の attention 出力を得る。(※ Multi-head attention, Position-wise Feed-Forward Networks については、後段で説明します)
- 上記 attention 出力を decoder の Multi-Head Attention 層に入力する
- decoder
decoder では、翻訳後文章の正解データ(例えば、”It's nice weather today”)と encoder からの翻訳前文章(例えば、「”今日は天気が良い”」)の各単語の埋め込み出力を入力として、翻訳後の文章を出力します。
- 翻訳前の文章(例えば、「”今日は天気が良い”」)の one-hot ベクトルを、埋め込み層で単語の埋め込みベクトルに変換する
- 上記埋め込みベクトルに対して Positional Encoding(位置エンコード)で単語位置に応じた値を加算することで、間接的に単語の順番情報を加味する
- 上記単語の順番情報を加味した埋め込みベクトルとに対して、{Multi-Head Attention → 残差接続 & 正規化レイヤー → Position-wise Feed-Forward Networks → 残差接続 & 正規化レイヤー}から構成されるレイヤーを N=6 回積み上げたネットワークで処理し、翻訳後の文章を出力します。Multi-Head Attention に関しては、encoder からの出力を入力する層と、翻訳後文章の正解データを入力する Masked Multi-Head Attention が存在します。(※ Multi-head Attention, Masked Multi-head Attention, については、後段で説明します。)
Positional Encoding

Transfomer では、RNN の構造をなくしたために、入力文書における各単語の順番情報を表現できなくなってしまっています。 そのため、入力文書における各単語を埋め込みベクトルに埋め込む際に、単語位置を定めるための Positional Encoding の行列 P, E を埋め込みベクトルに加算します。単語位置に応じた値を加算することで、間接的に単語の順番情報を加味できます。具体的には、Positional Encoding の行列 P, E の各要素は、以下の式で定義されます。

Multi-Head Attention
Multi-Head Attention を説明する前に、まずその基本となる部分から説明していきます
Attention
まず Attention から説明します。Attention とは以下の式で定義されるものになります。
: クエリ行列
: キー行列
: バリュー行列
:Attention weight
この式は、クエリ行列(Q)とキー行列(K)の内積で互いの類似度を計算して softmax で 0.0 ~ 1.0 に正規化。これを Attention wieight としてバリュー行列(V)と線形結合したものが Attention になるといってますが、この式は検索クエリ(Q)に一致するキー(K)に対応したバリュー(V)を取り出すといった辞書操作を行っていることと同値になります。その意味で Q, K, V はそれぞれクエリ行列、キー行列、バリュー行列といいます。
そして上式内の Attention weight 項は、文章における各単語同士の関連度を 0.0 ~ 1.0 の値で表したもので、例えば「”今日” ”は” ”天気” ”が” ”良い”」という文章の場合は、以下のようになるイメージです。従ってこの Attention weight から計算される Attention は、文中のある単語の意味を理解する時に文中の単語のどれに注目(Attention)すれば良いかを表すスコアになっています。
| クエリ/キー | 今日(k1) | は(k2) | 天気(k3) | が(k4) | 良い(k5) |
|---|---|---|---|---|---|
| 今日(q1) | 0.90=softmax(q1 x k1) | 0.10=softmax(q1 x k2) | 0.20=softmax(q1 x k3) | 0.10=softmax(q1 x k4) | 0.35=softmax(q1 x k5) |
| は(q2) | 0.10=softmax(q2 x k2) | 0.75=softmax(q2 x k2) | 0.10=softmax(q2 x k3) | 0.10=softmax(q2 x k4) | 0.10=softmax(q2 x k5) |
| 天気(q3) | ... | ... | ... | ... | ... |
| が(q4) | ... | ... | ... | ... | ... |
| 良い(q5) | ... | ... | ... | ... | ... |
※ Self-Attention(Q=K)の場合
Atenntion の式より、クエリ行列(Q)・キー行列(K)・バリュー行列(V)の値が決まれば Attention が計算できることはわかりますが、そもそもクエリ行列(Q)・キー行列(K)・バリュー行列(V)がどこから得られるかというと、Transformer の Multi-Head Attention にて下位ネットワーク層から得られますことになります。但し、その入力の仕方で次の Self-Attention と Source-Target Attention の2パターンに分類されます。
Self-Attention

Self-Attention では、クエリ行列(Q)・キー行列(K)・バリュー行列(V)の全てが自身の encoder or decoder の下位層から得られ、クエリ行列(Q)・キー行列(K)は一致します。
例えば「”今日” ”は” ”天気” ”が” ”良い”」という文章の場合、Self-Attention での attention weight は以下のようになるイメージです
| クエリ/キー | 今日(k1) | は(k2) | 天気(k3) | が(k4) | 良い(k5) |
|---|---|---|---|---|---|
| 今日(q1) | 0.90=softmax(q1 x k1) | 0.10=softmax(q1 x k2) | 0.20=softmax(q1 x k3) | 0.10=softmax(q1 x k4) | 0.35=softmax(q1 x k5) |
| は(q2) | 0.10=softmax(q2 x k2) | 0.75=softmax(q2 x k2) | 0.10=softmax(q2 x k3) | 0.10=softmax(q2 x k4) | 0.10=softmax(q2 x k5) |
| 天気(q3) | ... | ... | ... | ... | ... |
| が(q4) | ... | ... | ... | ... | ... |
| 良い(q5) | ... | ... | ... | ... | ... |
Source-Target Attention

キー行列(K)とバリュー行列(V)が encoder の中間層出力(source)から得られて、クエリ行列(Q)が decoder の中間層出力(target)から得られます。クエリ行列(Q)・キー行列(K)は一致しません。
Transformer におけるencoder は翻訳前文章を decoder は翻訳後文章を処理しますが、例えば「”今日” ”は” ”天気” ”が” ”良い”」⇒「”It””is””nice””weather””today”」という翻訳タスクの場合、Source-Target attention での attention weight は以下のようになるイメージです。
| クエリ/キー | 今日(k1) | は(k2) | 天気(k3) | が(k4) | 良い(k5) |
|---|---|---|---|---|---|
| It(q1) | 0.50=softmax(q1 x k1) | 0.45=softmax(q1 x k2) | 0.20=softmax(q1 x k3) | 0.25=softmax(q1 x k4) | 0.10=softmax(q1 x k5) |
| is(q2) | 0.10=softmax(q2 x k2) | 0.80=softmax(q2 x k2) | 0.10=softmax(q2 x k3) | 0.10=softmax(q2 x k4) | 0.10=softmax(q2 x k5) |
| nice(q3) | ... | ... | ... | ... | ... |
| weather(q4) | ... | ... | ... | ... | ... |
| today(q5) | ... | ... | ... | ... | ... |
Scaled Dot-Product Attention
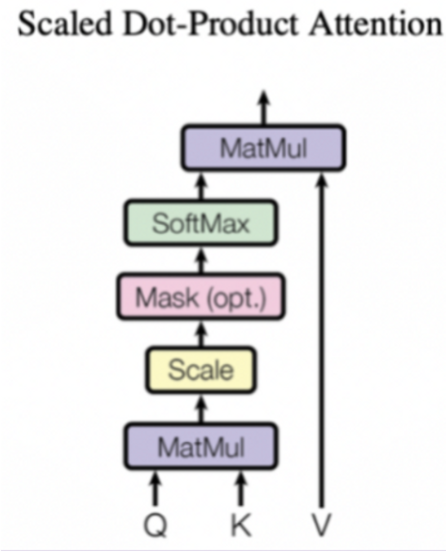
※ 上図の Mask (opt.) 部分は、後述の Masked Multi-head Attention の場合のみ有効になります
Transformer では、先の内積計算での attention 計算式に scale factor で正規化する処理を追加し、これを Scaled Dot-Product Attention と名付けてます。式で書くと、以下のようになります。
:scale factor
scale factor の 値は、キーの数(=単語の数)です。scale factor の値が大きい場合に内積の値が大きくなり、誤差逆伝播される softmax 出力の勾配が極端に小さくなる可能性があるので、scale factor での正規化処理を行っています。
Single-Head Attention

Scaled Dot-Product Attention は、ネットワーク層が存在しないので学習可能なパラメーターが存在しません。そのため、これ単独では入力された各単語の埋め込みベクトルの attention を計算できるだけで、学習を通じて最適な attention 出力を獲得ための埋め込みベクトルの変換を行うことができません。
Single-Head Attention では、クエリ(Q)キー(K)バリュー(V)の入力部分に学習パラメーターを持つ Liner 層を追加することで、学習を通じて最適な attention 出力を獲得するための埋め込みベクトルの変換を行うことができるようにしています。
Multi-Head Attention
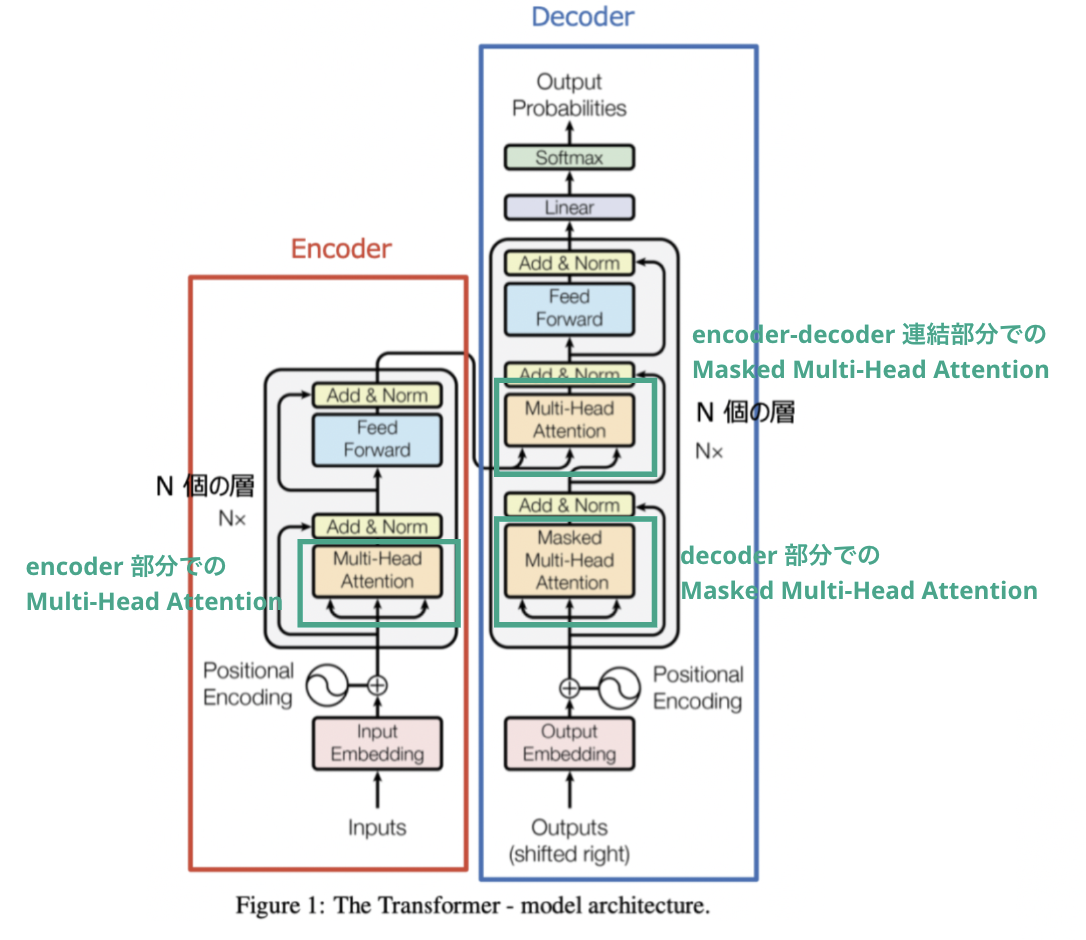
ここまで説明したところで、本題の Multi-Head Attention について説明していきます。Multi-Head Attention は、以下の3つの部分で存在しそれぞれ処理内容が違ってきます。
-
encoder 内部での Multi-Head Attention
encoder 内部の Multi-Head Attention で Self-Attention になります。即ち、クエリ行列(Q)・キー行列(K)・バリュー行列(V)全てが自身の encoder の下位層から得られます。クエリ行列(Q)とキー行列(K)が一致します。
-
encoder-decoder のボトルネック部分での Multi-Head Attention
encoder-decoder のボトルネック部分の Multi-Head Attention は、Source-Target attention になります。即ち、キー行列(K)とバリュー行列(V)が encoder の中間層出力(source)から得られて、クエリ行列(Q)が decoder の中間層出力(target)から得られます。クエリ行列(Q)・キー行列(K)は一致しません。
-
decoder 内部での Multi-Head Attention
decoder 内部の Multi-Head Attention で Self-Attention になります。即ち、クエリ行列(Q)・キー行列(K)・バリュー行列(V)全てが自身の decoder の下位層から得られます。クエリ行列(Q)とキー行列(K)が一致します。但し、decoder には翻訳後の正解データを入力するので、対象単語の次の単語の正解データをカンニングしてしまうことを防止するために、対象単語より次の単語に attention が加わらないようにするためのマスク処理が加わっています。
encoder 内部での Multi-Head Attention

encoder 内部の Multi-Head Attention で、上図の緑部分の箇所になります。
クエリ行列(Q)・キー行列(K)・バリュー行列(V)全てが自身の encoder の下位層から得られるので、Self Attention になります。
Multi-Head Attention の内部構造としては、先の Single-Head Attention を複数個(論文では8個)並列に束ねて、各 Single-Head Attention からの出力を concat で結合したもになってます。アンサンブルすることで、1つの Single-Head Attention のときより入力文章から様々な attention 特徴量を獲得できます。その結果、モデルの性能や汎化性能が向上する効果があります。
特に Single-Head Attention 内部の Scaled Dot-Product Attention における attention 出力は、前述の通り以下の式で算出できますが、この式は attention weight とで重み付き平均処理を行っていることと等価であり、この平均処理により入力文章の情報が欠落しやすい構造になっています。Single-Head Attention を複数並列に束ねて各出力を concat で接続することで、平均処理のときよりも情報が欠落しずらくなります。
encoder-decoder 連結部分での Multi-Head Attention

encoder と decoder のボトルネック部分での Multi-Head Attention で、上図の緑部分の箇所になります。キー行列(K)とバリュー行列(V)が encoder の中間層出力(source)から得られて、クエリ行列(Q)が decoder の中間層出力(target)から得られるので、Source-Target attention になります。
Multi-Head Attention の内部構造としては、encoder 内部の Multi-Head Attention と同じです。
decoder 内部での Masked Multi-Head Attention

decoder 内部の Multi-Head Attention で、上図の緑部分の箇所になります。
クエリ行列(Q)・キー行列(K)・バリュー行列(V)全てが自身の decoder の下位層から得られるので、Self Attention になります。
内部構造としては、encoder 内部の Multi-Head Attention とほぼ同じですが、Scaled Dot-Product Attention 内部にマスク処理の構造(上図 Mask (opt) の部分)が入っています。decoder は、学習時には翻訳後の文章全体の正解データを入力して学習し、推論時には翻訳後の単語を1つづつ生成していく形になっています。学習時に文章全体の正解データをそのまま入力すると、対象単語の次の単語の正解データをカンニングできてしまうので意味のない学習(=推論時に次の単語を予想できるようにならない)になってしまいます。なので、decoder に入力する翻訳後の正解データに対して対象単語より次の単語が使えないように、Scaled Dot-Product Attention 内部で次の単語の attention weight を0にするマスク処理をしています。その意味で、decoder 内部の Multi-Head Attention は Masked Multi-Head Attention といいます。
Position-wise Feed-Forward Networks

Multi-Head Attention の後段にあるネットワーク(上図の Feed Forward)で、Multi-Head Attention からの出力に対して、各単語(埋め込みベクトル)の位置度(Position-wise)にフィードフォワード型ネットワーク(MLPなど)での処理を行うネットワークで、以下の線形変換の式で定式化されます。

各単語ごとに別々のニューラルネットワークが存在しますが、各ネットワークで重みは共有しています。Multi-Head Attention での Self-Attention 構造によって、各単語ベクトルには他の単語の情報も間接的に含まれてしまうため、Position-wise Feed-Forward Networks でのフィードフォワード型ネットワークで各単語毎の変換を行うことで、各単語毎固有の情報に再変換しているのだと思います。
GPT-1
Transformer の説明が終わったところで、次に GPT-1 [Generative Pre-Trained Transformer-1]*8 について説明していきます。
GPT-1 は ChatGPT を開発した OpenAI が開発しており、大規模言語モデル(LLM)*9と呼ばれる種類のモデルになっています。
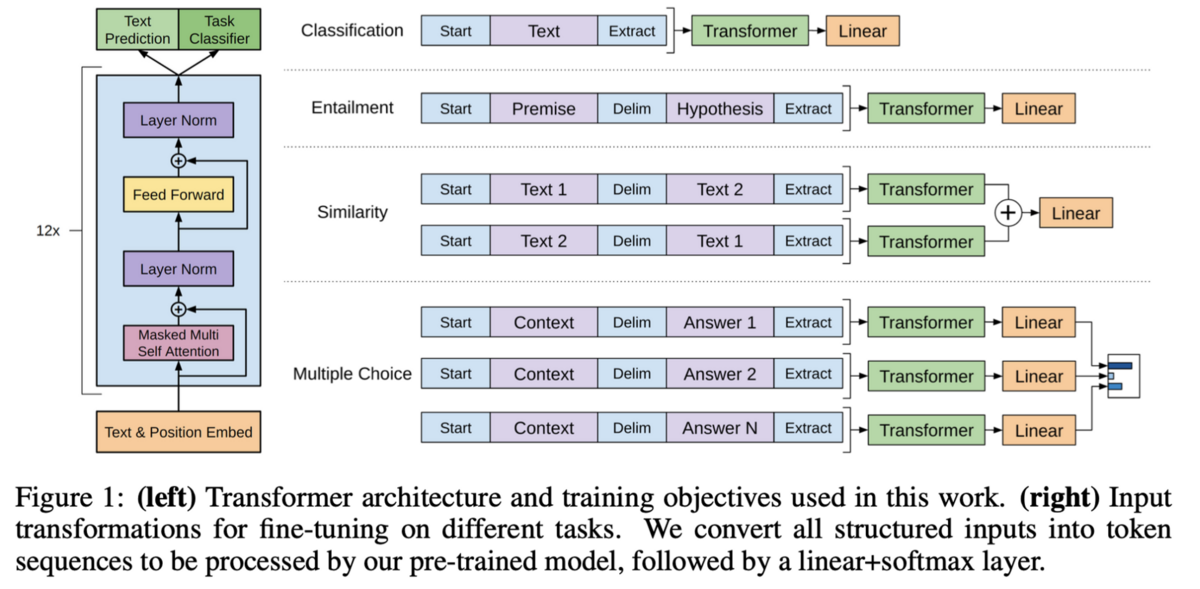
参考: Transformer のアーキテクチャとの比較
論文「Attention Is All You Need」より引用し一部改変

GPT-1 では、言語モデルとして Transformer のデコーダー層(上図青枠)とほぼ同じ構造のネットワークを採用しています。Encoder がないので Encoder-Decoder の連結部分における Multi-Head Attention(Source-Target attention)層も除外されて、Attention 構造としては、Self-Attention のみになります。
またオリジナルの Transformer では、上図青枠のデコーダー層における N の数が N=6 個でしたが、GPT-1 では N=12 個に層が増えています。(GPT-xxx のような LLMでは基本的にこの N の数がデカくなってます)
教師なしデータセットでの事前学習
Transformer ではその Encoder-Decoder 構造故に、入出力データペア(翻訳前データ、翻訳後データなどのペアデータ)形式のアノテーションされた学習用データセットを用意して学習する必要がありましたが、GPT-1 は Decoder 層のみなのでこの入出力データペアのアノテーションされた学習用データセットが必要なく、教師なしデータセットで学習することが可能になっています。
これはどういうこというと、例えば「今日は良い天気ですね」という教師なしデータのテキストがあった場合に、テキスト文章の切り取り箇所を変えていけばこの教師なしデータのみから以下の組み合わせのペアデータが作れます。このペアデータは入力文章に続く次の出力単語の正解データのペアデータになっているので、GPT-1 の学習に使えます。
| 入力データ | 出力データ(=正解データ) |
|---|---|
| 「今日」「は」 | 「良い」 |
| 「今日」「は」「良い」 | 「天気」 |
| 「今日」「は」「良い」「天気」 | 「です」 |
Transformer では CNN のような畳み込み構造で入力データを抽象化しない特性上、従来の CNN のようなネットワークと比較して、十分な品質を発揮するには非常に大量のアノテーションされた学習用データセットが必要になる(現実的にこの規模のデータセットを収集するのは困難)というデメリットがあるのですが、GPT-1 ではアノテーションした学習用データセットなくとも単に多量のテキストがあれば良いだけになるので、この教師なしデータセットで学習可能というのは非常にデカいメリットになります。
GPT-1 では、大規模な教師なしテキストデータ(具体的には BookCorpus と呼ばれる様々なジャンルの7000冊のテキストデータ)を用いて、GTP-1 の言語モデル(Transformer の Decoder 層)を事前学習しています。
教師ありファインチューニング
GPT-1 では教師なしデータセットで GPT-1 を事前学習しますが、 この事前学習 GPT-1 のままだと自然言語の様々なタスク(テキスト分類、翻訳など)全てで高い品質を発揮することはできません。そのため今度は各々の自然言語タスクに応じた教師ありの学習用データセットで入力データ形式・出力層などをファインチューニングすることで、自然言語タスクに応じた品質に特化させていきます。

GPT-2
次に GPT-2*10 です。GPT-2 はその名の通り GPT-1 の発展版モデルで、GPT-1 との大きな違いとしては以下の通りです
- 言語モデル(Transformer の Decoder 層)の層の数を増やした
- 学習用データセットも増やした
- ファインチューニング不要になった(ファインチューニングなしでも高い品質を実現)
以下、それぞれ見ていきます。
言語モデルのアーキテクチャ
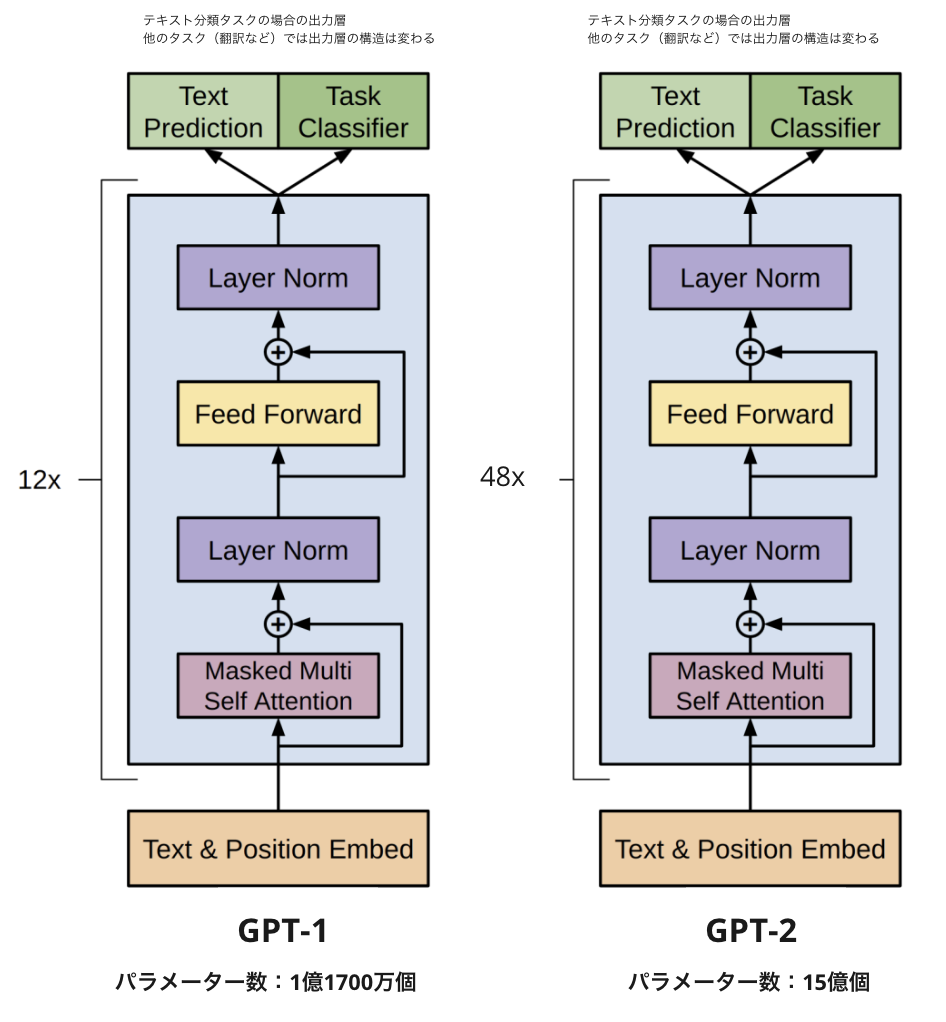
GPT-2 の基本的な構造は GPT-1 と同じですが、Transformer の Decoder 層における N の数が 12 → 48 個に増えてます。また上図では書いてないですが小さな変更点として Self Attention 層の前段にもlayer normalization 層が追加されています。結果として、GPT-2 の言語モデルのパラメーター数は、1億1700万個 → 15億個と大幅に増加しています。
単純に現状の段階では、Transformer のネットワーク層を深くして学習可能なパラメーター数を増やすほうが品質があがるので、GPT-1 から大幅に増やしています。但し当然ながら学習時間や GPU メモリ使用量も大幅に増加し、開発コストも大幅に増加します。
学習用データセット
以下のように GPT-2 では、よい多くの学習用データセットで学習しています
- GPT-1 : 4.5GBのテキスト
- 具体的には BookCorpus と呼ばれる様々なジャンルの7000冊のテキストデータ
- GPT-2 : 40GBのテキスト(大量のウェブページから構成)
- 具体的には海外の Reddit というウェブページからスクレイピングしたテキストデータで WebText データセットと名付けたデータセット
- ただし3 karma(Reddit におけるポイントのようなもの)以上獲得している投稿に絞ることで一定の重要性(他のユーザーがそのリンクを面白い、勉強になる、あるいは面白いと感じたかどうか)を考慮している
- 具体的には海外の Reddit というウェブページからスクレイピングしたテキストデータで WebText データセットと名付けたデータセット
ファインチューニングの不要化

上記 WebTextデータセットを使って、上記言語モデルを事前学習していますが、GPT-1 で行っていたその後のファインチューニングなしに、Zero-Shot でも十分の品質を実現しています。
GPT-1 ではファインチューニングが必要でしたが、GPT-2 ではそのファインチューニングさえも不要(=なしでも高い品質)になっているのが大きな違いになります
【補足】Zero-Shot, One-Shot, Few-Shot
-
Zero-Shot
論文「Language Models are Few-Shot Learners」より引用
-
モデルに task description(タスクを指示した文章)を入力するだけで、exsample(タスクの入出力データ例)は指定しない設定
-
上記例では、英語からフランス語への翻訳タスクを指示するば、英語(cheese)に対応したフランス語が与えない
-
-
exsample(タスクの入出力データ例)で追加学習が行えない
-
最も難しい問題設定になっている
-
-
One-Shot
論文「Language Models are Few-Shot Learners」より引用 - モデルに task description(タスクを指示した文章)を入力し、更に1つの example を与える設定
- 上記例では、英語からフランス語への翻訳タスクを指示した上で、英語(sea otter)に対応したフランス語(loutre de mer)を与える
- 1つの examples のみで追加学習が行えるが、学習(=重みの更新)は行わない
- Zero-Shot よりは簡単な問題設定になっている
- モデルに task description(タスクを指示した文章)を入力し、更に1つの example を与える設定
Few-Shot
論文「Language Models are Few-Shot Learners」より引用 - モデルに task description(タスクを指示した文章)を入力し、更に複数の examples を与える設定
- 上記例では、英語からフランス語への翻訳タスクを指示した上で、英語に対応したフランス語を複数与える
- examples が複数あるので、少量の複数 examples で追加学習が行えるが、学習(=重みの更新)は行わない
- 最も簡単な問題設定になっている
GPT-3
次に GPT-3*11 です。GPT-3 もその名の通り GPT-1, GPT-2 の発展版モデルで、GPT-1, GPT-2 との大きな違いとしては GPT-2 のときと同じく以下の通りです。これにより GPT-2 より更に品質が向上したモデルになっています。
- 言語モデル(Transformer の Decoder 層)の層の数を増やした
- 学習用データセットも増やした
- ファインチューニング不要(ファインチューニングなしでも高い品質を実現)
- GPT-2 でもファインチューニング不要だったが、GPT-3 では更に品質が向上
言語モデルのアーキテクチャ

GPT-3 も基本的な構造は GPT-1, GPT-2 と同じですが、Transformer の Decoder 層における N の数が GPT-1(12層)→ GPT-2(48 層)から更に GPT-3(96 層)までに大幅に増えてます。結果として、GPT-3 の言語モデルのパラメーター数は、GPT-1(1億1700万個)→ GPT-2(15億個)→GPT-3(1750億個)と大幅に増加しています。
GPT1 → GPT-2 にときと同様にして、単純に現状の段階では、Transformer のネットワーク層を深くして学習可能なパラメーター数を増やすほうが品質があがるので、GPT-1, GPT-2 から大幅に増やしています。但し当然ながら学習時間や GPU メモリ使用量も更に大幅に増加し、開発コストも更に大幅に増加します。
学習用データセット
GPT-3 では、以下のように GPT-1, GPT-2 より飛躍的に多くの学習用データセットで学習しています。
- GPT-1 : 4.5GBのテキスト
- 具体的には BookCorpus と呼ばれる様々なジャンルの7000冊のテキストデータ
- GPT-2 : 40GBのテキスト(大量のウェブページから構成)
- 具体的には海外の Reddit というウェブページからスクレイピングしたテキストデータで WebText データセットと名付けたデータセット
- ただし3 karma(Reddit におけるポイントのようなもの)以上獲得している投稿に絞ることで一定の重要性(他のユーザーがそのリンクを面白い、勉強になる、あるいは面白いと感じたかどうか)を考慮している
- 具体的には海外の Reddit というウェブページからスクレイピングしたテキストデータで WebText データセットと名付けたデータセット
- GPT-3 : 570GBのテキスト(様々なWeb上の情報源)
- 具体的には、以下の3つの Step で収集したデータセット
- Common Crawl というデータセットを複数の高品質なコーパスとの相関によってフィルタリング
- データセット内やデータセット間でのデータの重複を除去
- 既存の高品質なコーパス(WebTextデータセット、英語のWikipediaなど)を加えることでデータセットの多様性を向上
- 具体的には、以下の3つの Step で収集したデータセット
GPT-3.5
最後に GPT-3.5 です。
GPT3.5 は GPT-3 の発展モデルで 2022 年の初旬に学習が完了したモデルです。残念ながら論文は公開されていないです。とはいえ公開されている範囲の情報では、特段新たな手法やアーキテクチャが導入しているわけではくなさそうで、違いとしては以下の部分だけのようです。(編集部注:出典を確認できていないため、下線部分を訂正いたします。 / 23年9月)
- (Transformer のネットワーク層を深くして)モデルのパラメーター数を 1750億個(GPT-3)→ 3,550億個(GPT-3.5)に増やした。
- テキストデータ以外にもプログラミングコードのデータも追加。テキストとコードの学習用データセットは 2021年 Q4 以前のもの
無料版の ChatGPT では、言語モデルとしてこの GPT-3.5 を使用しています。
後編へ続く・・・
後編は以下の記事をご参照ください。
採用情報
株式会社ABEJAでは共に働く仲間を募集しています!
機械学習モデル開発や機械学習プロダクトに関わるフロントエンド開発バックエンド開発に興味あるエンジニアの方々!こちらの採用ページから是非ご応募くださいませ!
*1:one-hot encoding という手法自体は、NLP 以外の機械学習分野でも多用される手法ですが、NLP の文脈ではこのような意味合いになります
*2:論文「Attention Is All You Need」
*3:因みに Transformer は Google が発表しています。OpenAI の GPT-xxx や ChatGPT は Transformer をベースとしていますが、そのベースの Transformer 開発したのは Google なんですよね、、、当時はこういうことになるとは思ってなかったのでしょうね。コンピューターサイエンスの分野は OSS文化強いんで(特に海外は)使う方はとてもありがたい話です。
*4:論文「Sequence to Sequence Learning with Neural Networks」
*6:論文「Effective Approaches to Attention-based Neural Machine Translation」
*7:Transformer を提案した論文タイトルは、「Attention Is All You Need」なんですが、ここからもわかるように、Transformer ではこの attention 構造がポイントになってます。
*8:論文「Improving Language Understanding by Generative Pre-Training」
*9:大規模言語モデル(LLM)とはその名の通り、言語モデルを層の深くてパラメーター数も多いディープラーニングモデルでモデル化した言語モデルです。
