
ABEJAでデータサイエンス部の部長をしながら色々やっている大谷です。
今回は2024年12月19日に公開された待望のQwen2.5 Technical Reportについて日本語に翻訳しつつ、適宜コメントを入れていく記事を書いていこうと思います。コメントはですます口調で記述しています。
先にネタバレですが、Qwen2.5は特別新しい技術を導入しているわけではなく、これまで積み重ねてきた知見を着実に活かして精度を向上させています。この記事では、新しい観点の発見というよりも、これまでの有効な知見を再確認するきっかけにしていただければ嬉しいです。
ちなみにこちらの記事はABEJAアドベントカレンダー2024年の12/23分です。
裏話ですが、12月の頭にラスベガスで開催された「AWS re:Invent 2024」(re:Invent)にABEJAも参加していたので、本記事はそちらをテーマにするつもりでした。ただ、re:Invent周りの内容は結構世に出回っているので、また別の機会でもっと深掘りするような記事にできればなと思っています。re:Invent自体は現地ならではの熱気を肌で感じることができて本当に有意義な時間を過ごすことができました。
目次
- 時間がない人のために要約
- 論文構成
- Abstract
- 2. Architecture & Tokenizer
- 3. Pre-training
- 4. Post-training
- 5. Evaluation
- 6. Conclusion
- さいごに
時間がない人のために要約
Qwen2.5は、従来バージョンをはるかに上回る18Tトークン(前回は7Tトークン)の学習データを活用した事前学習と、数百万件の高品質サンプルを用いた多段階の事後学習によって開発された大規模言語モデル。数学やコーディングをはじめとする専門領域のデータや長文生成への対応に力点を置くことで、推論・生成の性能が飛躍的に向上し、人間の指示や好みに忠実に応答できるよう設計されている。
オープンウェイトモデルは0.5Bから72Bのパラメータ規模まで取りそろえられ、量子化モデルも用意されているため、リソースが限られた環境でも利用しやすいのが特徴。さらに、Alibaba Cloudから提供されるAPI(Qwen2.5-TurboやQwen2.5-Plus)には、精度・速度・コストを高い水準で両立させるMoE技術が採用されている。
幅広いベンチマークでQwen2.5の性能を評価した結果、OSSのフラッグシップモデルであるQwen2.5-72B-Instructは、はるかにサイズが大きいLlama-3-405B-Instructと同等のパフォーマンスを示した。一方、Qwen2.5-TurboとQwen2.5-Plusはコストを大幅に削減しながらも、高い性能を維持することに成功。長文コンテキストの処理能力も大幅に強化され、入力128Kトークン/出力8Kトークンに対応。スパースアテンションの活用などにより、推論速度も向上し、大規模テキストの解析・生成がスムーズに行えるようになった。
今後は、より多様かつ高品質のデータを取り込み、ベースモデルや指示調整済みモデルの性能をいっそう高めるとともに、テキスト以外のモダリティを統合したマルチモーダルモデルの開発や推論能力のさらなる強化を図る計画となっている。
論文構成
論文の章立ては以下のようになっています。基本的にそこまで尖った項目はなく、シンプルな構成かなと思います。
Abstract
1. Introduction
2. Architecture & Tokenizer
3. Pre-training
3.1 Pre-training Data
3.2 Scaling Law for Hyper-parameters
3.3 Long-context Pre-training
4. Post-training
4.1 Supervised Fine-tuning
4.2 Offline Reinforcement Learning
4.3 Online Reinforcement Learning
4.4 Long Context Fine-tuning
5. Evaluation
5.1 Base Models
5.2 Instruction-tuned Model
6. Conclusion
7. Authors
References
6章まで順に内容を見ていきましょう。
Abstract
時間がない人の要約とほぼ同じではありますが、ポイントは以下です。
事前学習データセットを7兆トークンから18兆トークンへ拡大。
事後学習で100万件以上のデータを用いた教師あり微調整やマルチステージ強化学習を実施。
長文生成、構造化データ分析、指示追従能力を大幅に改善。人間の嗜好への適応性も向上。
ベンチマークでは言語理解、推論、数学、コーディングなどの分野でトップクラスの性能を実証。
Qwen2.5-72B-InstructはLlama-3-405B-Instructに匹敵する性能を発揮。
Qwen1.5→Qwen2→Qwen2.5で学習トークン数を増やしていくにつれてモデル性能も拡張。(Figure1参照)
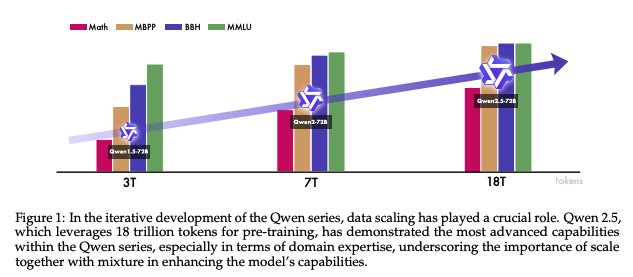
2. Architecture & Tokenizer
おそらくこの記事を読まれている方はAPIではなくOSSモデルの方に興味があると思うので、以降は基本的にOSSモデルの話に絞って記載していきます。
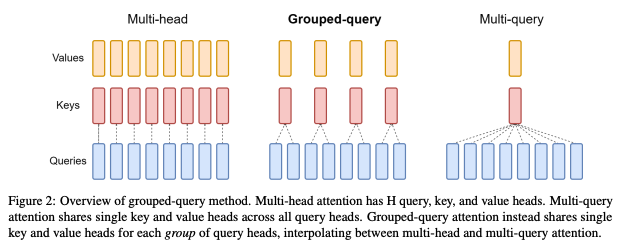
OSS向けモデルはDenseモデル(MoEではない)を採用しています。通常のTransformerベースのデコーダーアーキテクチャを採用し、Grouped Query Attention、SwiGLU活性化関数、Rotary Positional Embeddings、QKV bias、RMSNormを組み込むことで、速度や安定した学習を実現しているとのことです。
Grouped Query Attention、SwiGLU活性化関数、Rotary Positional Embeddings、RMSNormはQwen特有のものではなく、Llamaなど他のモデルでも広く活用されているのでサクッと紹介までに留めます。
Grouped Query Attentionは従来のMulti Head Attentionの品質を維持しつつ、Multi Query Attentionの速度を実現する中間的なアプローチです。
SwiGLU活性化関数はReLUより滑らかな活性化関数で、収束性が早いとのことです。こちらのブログがわかりやすいです。(藤井さんのブログはいつもお世話になっています!)
Rotary Positional Embeddingsも今となっては位置埋め込みの王道になっていると思います。トークンの埋め込みに対して回転行列を適用して位置情報を埋め込む手法で、埋め込み空間内での位相の回転によって相対的な位置関係を表現しています。個人的に感じる一番の利点は任意のシーケンス長への適用が可能な点で、コンテキスト長が伸びている昨今では、この任意の長さというのは非常に重要な観点です。
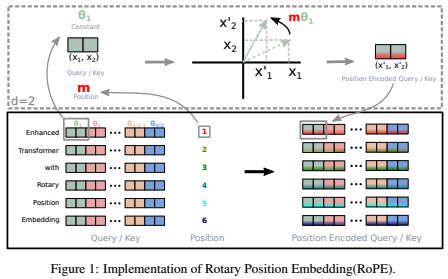
RMSNormも特段新しいものではないです。こちらのブログがコードの記述もありわかりやすかったです。基本的にはLayerNormと同じで、計算量が少なくなるとのことです。
唯一Qwenくらいでしかみないなと思うのがQKV biasです。モデルの外挿能力が上がるとのことですが、正直効果は不透明です。
たしかにqwen2のtransformersのコードでもqkvのnn.Linearはbias=Trueになっています。
TokernizerはbyteレベルのBPE tokenizerでvacab数は152064となっています。special tokenが以前の3個から22個に拡張されており、今後の互換性の問題の低減が期待できます。 ちなみにQwen2とQwen2.5のspecial tokenの対比は以下の通りです。画像や動画などモダリティを増やせるような準備を事前にしている感じがわかります。(not specialと書いているのはtokenizer_config.jsonとしてはspecial tokenではないものになります)
| Token | Qwen2 | Qwen2.5 |
|---|---|---|
endoftext |
✅ | ✅ |
im_start |
✅ | ✅ |
im_end |
✅ | ✅ |
object_ref_start |
❌ | ✅ |
object_ref_end |
❌ | ✅ |
box_start |
❌ | ✅ |
box_end |
❌ | ✅ |
quad_start |
❌ | ✅ |
quad_end |
❌ | ✅ |
vision_start |
❌ | ✅ |
vision_end |
❌ | ✅ |
vision_pad |
❌ | ✅ |
image_pad |
❌ | ✅ |
video_pad |
❌ | ✅ |
tool_call |
❌ | ✅ (not special) |
/tool_call |
❌ | ✅ (not special) |
fim_prefix |
❌ | ✅ (not special) |
fim_middle |
❌ | ✅ (not special) |
fim_suffix |
❌ | ✅ (not special) |
fim_pad |
❌ | ✅ (not special) |
repo_name |
❌ | ✅ (not special) |
file_sep |
❌ | ✅ (not special) |
3. Pre-training
3章では、3.1 Pre-training Data、3.2 Scaling Law for Hyper-parameters、3.3 Long-context Pre-trainingの三つに分けて事前学習について述べられています。
3.1 Pre-training Data
ざっくり言うと今までのQwenモデル(Qwen2-Instruct/Qwen2.5 Math/Qwen2.5 Coder/Qwen2-Math-72B-Instruct/Qwen2-Math-RM-72B)で合成データの合成およびデータフィルタリングをすることで、高品質データを追加して7Tトークンから18Tトークンまで拡張することができたとのことです。大事そうなところだけ元論文からピックアップします。
より優れたデータフィルタリング
高品質な事前学習データはモデル性能の向上に不可欠であり、データの品質評価とフィルタリングはパイプラインの重要な要素。Qwen2-Instructモデルをデータ品質フィルターとして活用し、トレーニングサンプルを評価およびスコア付けするための包括的で多次元的な分析を実施。
より優れた数学およびコードデータ
Qwen2.5の事前学習フェーズでは、Qwen2.5-MathおよびQwen2.5-Coderからのトレーニングデータを統合。高品質な専門領域のデータセットを事前学習中に活用することで、Qwen2.5は数学的推論およびコード生成の強力な能力を継承。
より優れた合成データ
特に数学、コード、知識の分野における高品質な合成データを生成するために、Qwen2-72B-InstructおよびQwen2-Math-72B-Instructを活用。この合成データの品質は、独自の汎用報酬モデルおよび専門特化したQwen2-Math-RM-72Bモデルを用いた厳密なフィルタリングによってさらに向上。
より優れたデータ混合 事前学習データの分布を最適化するために、Qwen2-Instructモデルを用いて、異なる分野間のコンテンツを分類しバランスを取っている。ウェブ規模のデータでは、eコマース、ソーシャルメディア、エンターテイメントといった分野が過剰に含まれている傾向があり、それらには繰り返しやテンプレートベース、あるいは機械生成されたコンテンツが多く含まれることが分かった。一方で、技術、科学、学術研究といった分野は、質の高い情報を含んでいるにもかかわらず、データセットとして十分な量が確保されていない。これに対応するため、過剰に含まれている分野を戦略的にダウンサンプリングし、質の高い分野をアップサンプリングすることで、よりバランスが取れ、情報量が豊富なトレーニングデータセットを確保した。
3.2 Scaling Law for Hyper-parameters
OSSモデル(Denseモデル)では、44M~14Bパラメータのモデルでハイパラチューニングを実施したとのことですが、具体的な数字は記載がなく謎の多い部分でした・・・
3.3 Long-context Pre-training
2段階の事前学習アプローチを採用して、ロングコンテキスト処理能力を強化。最初は最大4,096トークンのコンテキスト長で学習を行い、後半の拡張フェーズで32,768トークンへ対応範囲を広げた。また、RoPEの基本周波数を10,000から1,000,000に増加させるABF技術を採用。 (ABFはまだキャッチアップできておらず、ここら辺の論文1, 2が対象なはずです) ちなみにQwen2.5-Turboでは、トレーニング中に段階的なコンテキスト長拡張戦略を実施。32,768トークン、65,536トークン、131,072トークン、最終的には262,144トークンという4段階で拡張し、RoPEの基本周波数を10,000,000に設定。各段階で、トレーニングデータは現在の最大長のシーケンスを40%、それより短いシーケンスを60%の割合で含むよう慎重に選定したとのことです。
4. Post-training
Qwen2/5でも事後学習としては王道のSFT + 強化学習を実施しています。
SFTデータのカバレッジ拡大
SFTプロセスでは、長シーケンスの生成、数学的問題解決、コーディング、指示のフォロー、構造化データの理解、論理的推論、異言語間の転移、そして堅牢なシステム指示の処理を含む数百万の高品質な例を含む膨大なデータセットを活用。
2段階の強化学習
オフラインRL この段階では、reasoning、事実性、指示のフォローといった報酬モデルで評価が難しい能力の開発に重点を置いている。学習データを綿密に構築・検証することで、オフライン強化学習の信号が学習可能で信頼性のあるものとなるようにしているとのこと。詳細はこちらの論文にありますが、かなりボリュームあるので別の機会で紹介できればなと思います。
オンラインRL オンライン強化学習の段階では、真実性、有用性、簡潔さ、関連性、安全性、偏りの排除といった出力品質の微妙なニュアンスを検出する報酬モデルの能力を活用。
4.1 Supervised Fine-tuning
SFTフェーズでは、以下の重要な領域に焦点を当てた大幅な改善を実施。
長文生成
Qwen2.5は、8,192トークンまでの高品質な長文を生成できる能力を備えており、従来の事後学習済みモデルで一般的な2,000トークン未満の応答長を大きく超えている。事前学習コーパスから長文データ用のクエリを生成し、出力長制約を課すことで、長文応答用データセットを作成。
引用論文の仕組み自体はシンプルで、生成したデータを拡張してさらに長くする→長い出力の一部を削除して、削除した部分を再生成させるといった形で徐々に拡張していくような手法みたいです。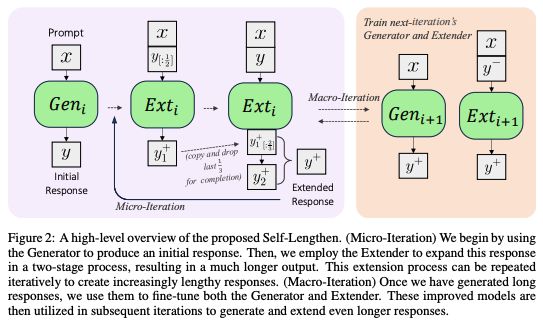

数学
Qwen2.5-MathのCoTデータを導入し、公開データセット、K-12の問題集、合成問題など、多様なクエリソースを使用。高品質な推論を確保するために、リワードモデリングや注釈付き回答を用いた拒絶サンプリングを採用し、ステップごとの推論プロセスを生成。コーディング
Qwen2.5-Coderの指示調整データを取り入れ、約40のプログラミング言語にわたる多様で高品質な指示ペアを生成するため、複数の言語専用エージェントを協力的なフレームワークに統合。コード関連のQ&Aサイトから新しい例を合成し、GitHubからアルゴリズムコードスニペットを収集。多言語対応の包括的なサンドボックスを使用して静的コードチェックや自動単体テストを実施し、コードの品質と正確性を保証した。指示のフォロー
高品質な指示フォローデータを確保するために、コードベースの検証フレームワークを導入。このアプローチでは、LLMが指示と対応する検証コード、さらに包括的な単体テストを生成。実行フィードバックを活用した拒絶サンプリングを通じて、SFTで使用するトレーニングデータを慎重に選定し、モデルが意図した指示に忠実に従うことを保証した。構造化データの理解
構造化データの包括的な理解を目的としたデータセットを開発。従来のタスク(例: 表形式の質問応答、事実検証、エラー修正、構造の理解)だけでなく、構造化データや半構造化データを含む複雑なタスクも網羅。モデルの応答に推論の連鎖を組み込むことで、構造化データから情報を推測する能力を大幅に向上させ、これら多様なタスクにおけるパフォーマンスを改善した。このアプローチにより、データセットの範囲が広がるだけでなく、複雑なデータ構造から意味のある洞察を引き出すモデルの推論能力も深まるとのこと。
データセット内容に触れている具体的な箇所が見当たらず、詳細ご存知の方がいたら教えていただきたいです・・・!論理的推論
論理的推論能力を強化するため、複数の分野にわたる70,000の新しいクエリ(多肢選択式、真偽式、自由回答式の質問を含む)を導入。モデルは、演繹的推論、帰納的一般化、類推的推論、因果推論、統計的推論など、さまざまな推論方法を用いて問題に体系的に取り組むよう訓練されている。反復的な改良を通じて、誤った回答や推論プロセスを含むデータをフィルタリングし、モデルの論理的かつ正確な推論能力を強化した。
こちらも具体的な内容を見つけることができず・・・異言語間転移
モデルの汎用的な能力を言語間で移転するために、翻訳モデルを活用して高リソース言語(おそらくデータセットに多く含まれる言語)の指示をさまざまな低リソース言語に変換し、それに対応する応答候補を生成。これらの応答の正確性と一貫性を確保するため、各多言語応答と元の応答との間の意味的整合性を評価。このプロセスにより、元の応答の論理構造や文体のニュアンスが保持され、異なる言語間でも一貫性と整合性を維持している。
定性的ではあるものの、Qwenの日本語性能は他モデルと比較してもかなり高いです。ただ生成時に中国語が混ざることが見られるので、ここら辺の中国語混じりの部分は転移の影響を受けているのかなと思ったりしています。(純粋に中国語と日本語が漢字という共通部分を持っているだけかもしれないですが・・・)堅牢なシステム指示
ポストトレーニングでのシステム指示の多様性を向上させるために、数百種類の一般的なシステムプロンプトを構築。評価の結果、異なるシステムプロンプト間でもモデルが高い性能を維持し、分散が減少していることが確認されており、堅牢性が向上した。応答フィルタリング
応答の品質を評価するため、専用の批評モデルや多エージェント協力型スコアリングシステムを含む複数の自動アノテーション手法を採用。厳密な評価を通じて、すべてのスコアリングシステムで完璧とみなされた応答のみを保持することで、最高品質の出力を保証した。
最終的に、100万件以上のSFTデータセットを構築。モデルは、32,768トークンのシーケンス長で2エポックにわたり微調整。学習効率を最適化するために、学習率を7×10⁻⁶から7×10⁻⁷へ徐々に減少させる。過学習への対策として、weight decayを0.1に設定し、勾配ノルムを最大1.0にクリップしている。
4.2 Offline Reinforcement Learning
オンライン強化学習と比較して、オフライン強化学習は学習データを事前に準備できる点で特に有利。これは標準的な答えが存在するものの、報酬モデルを用いて評価するのが困難なタスクにおいて特に有効。Qwenのオフライン強化学習では、数学、コーディング、指示の遵守、論理的推論といった、正確な評価の取得が難しい客観的なクエリ領域に焦点を当てている。前段では、実行結果のフィードバックや回答の一致確認といった戦略を広範に用いて、応答の品質を確保。後段では、前段で作ったパイプラインを再利用し、SFTモデルを用いて新たなクエリセットに対する応答を再サンプリングしている。学習はDPO(Direct Preference Optimization)を採用しており、品質チェックを通過した応答はポジティブ例として使用され、基準を満たさなかった応答はネガティブ例として扱う。
さらに、トレーニング信号の信頼性と精度を向上させるため、人間と自動化されたレビューの両方を活用する。(こちらの調査論文が引用されていますが、まだ中身を調査しきれていないです・・・)
この二重のアプローチにより、トレーニングデータが学習可能であるだけでなく、人間の期待に沿ったものとなることを保証している。
最終的に、約15万ペアからなるデータセットを構築。モデルはOnline Merging Optimizerを用いて1エポック学習され、学習率は7×10⁻⁷に設定されている。
Online Merging Optimizerは、RLHFの各最適化ステップでRLポリシーモデルとSFTモデルを統合し、トレーニング方向を継続的に調整する手法です。RLHFモデルとSFTモデルのパラメータを補間することで、人間の好みに対する整合性と基本的な能力とのトレードオフを調整し、整合性報酬のコストを抑えながら整合性税を軽減できるとのことです。
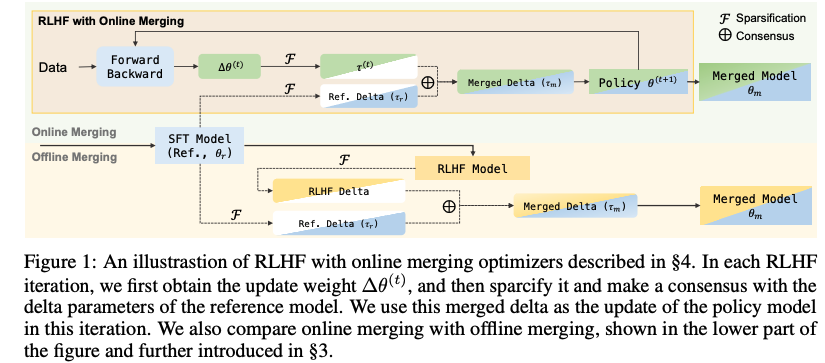
4.3 Online Reinforcement Learning
オンライン強化学習用の堅牢な報酬モデルを開発するために、慎重に定義されたラベリング基準に従う。これらの基準は、モデルが生成する応答が高品質であるだけでなく、倫理的かつユーザー中心の基準にも適合していることを保証する。データラベリングの具体的なガイドラインは以下の通り。
真実性(Truthfulness): 応答は事実に基づいているかどうか
有用性(Helpfulness): モデルの出力はユーザーの問い合わせに効果的に答え、前向きで興味深く、教育的で関連性のある内容を提供できているか
簡潔さ(Conciseness): 応答は簡潔で要点を押さえたものであるべきであり、不必要な冗長性を避けるべきです。情報を明確かつ効率的に伝えることができているか
関連性(Relevance): 応答の全ての部分が、ユーザーの問い合わせ、対話履歴、およびアシスタントのコンテキストに直接関連しているか
無害性(Harmlessness): モデルはユーザーの安全を最優先に考え、違法、不道徳、有害な行動につながる可能性のあるコンテンツを避けられているか
偏りの排除(Debiasing): モデルの応答は、性別、人種、国籍、政治などにおける偏見がないものである必要がある。全てのトピックを公平かつ平等に扱い、広く受け入れられた道徳的および倫理的基準に従うことができているか
報酬モデルの訓練に使用される問い合わせデータセットは、公開されているオープンソースデータと、より高い複雑性を持つ独自のクエリセットの2つの異なるデータセットから抽出されている。応答はQwenモデルのチェックポイントから生成され、SFT、DPO、RL(強化学習)の異なる方法でファインチューニングされている。多様性を確保するために、これらの応答は異なる温度設定でサンプリングされる。Preferenceデータのペアは、手動および自動のラベリングプロセスを通じて作成され、DPO用のトレーニングデータもこのデータセットに統合されている。
オンライン強化学習のフレームワークでは、Group Relative Policy Optimizationを使用。報酬モデルの訓練に使用されるクエリセットは、強化学習の訓練段階でも同じセットを使用している。訓練中にクエリを処理する順序は、報酬モデルによって評価された応答スコアの分散によって決定される。特に、応答スコアの分散が大きいクエリが優先され、より効果的な学習が実現できる。各クエリに対して8つの応答をサンプリングし、全てのモデルはグローバルバッチサイズ2048と、各エピソードに2048サンプル(クエリと応答のペアを1サンプルとしてカウント)を用いて訓練される。
GRPOに関してはこちらの記事でも解説されていますが、PPOで必要だった価値観数の代わりに出力郡の平均報酬を使用することでメモリと計算リソースを削減できる手法です。
また、報酬モデルの6つの観点に関して、NVIDIAのHelpSteer2では、helpfulness(有用性)/correctness(正確さ)/coherence(一貫性)/complexity(複雑さ)/verbosity(冗長さ)という5つ観点を使用しており違いが生まれています。ただ後述の報酬モデルでのベンチマークでは概ね同等の結果となっており、指標の違いによる影響は大きいものではないのかなと思っています。(報酬モデルの評価方法が限られているという別の課題はありますが・・・)
4.4 Long Context Fine-tuning
(こちらの節はQwen2.5 Turboに関するものなのでさらっと紹介のみ。)
Qwen2.5-Turboのコンテキスト長をさらに拡張するために、ポストトレーニングの段階で長いSFTを導入。これにより長いクエリに対する応答がより人間の好みに一致するようになった。SFTフェーズでは2段階のアプローチを採用している。第1段階では、最大32,768トークンまでの短い指示を用いてモデルをファインチューニングする。この段階では、他のQwen2.5モデルと同様のデータとトレーニング手順を適用し、短いタスクでの高い性能を維持することを目的としている。第2段階では、短い指示(最大32,768トークン)と長い指示(最大262,144トークン)の両方を組み合わせたハイブリッドなファインチューニングを行う。
強化学習フェーズでは、他のQwen2.5モデルと同様のトレーニング戦略を採用しており、短い指示(最大32,768トークン)にのみ焦点を当てている。この設計を選択した理由は二つある。一つ目は、長い文脈タスクに対するRLトレーニングが計算コストの面で非常に高くなること。二つ目は、長い文脈タスクに適した報酬信号を提供する報酬モデルが現在のところ不足していることである。しかし、短い指示のみを用いたRLであっても、長い文脈タスクにおいてモデルが人間の好みに適合する能力を大幅に向上させることが可能であることが判明している。
5. Evaluation
(評価の章は細かく解説するとかなり長くなってしまうので、ここではOSSモデルに絞った内容の紹介と軽いコメントのみにとどめます)
事前学習で生成された基盤モデルおよび事後学習で生成された指示調整済みモデルは、広範なベンチマークを用いて評価される。ベンチマークは、一般的に使用される公開ベンチマークとスキル指向の社内データセットの両方が含まれている。評価プロセスは、できる限り自動化され人間による介入を最小限に抑えるよう設計されている。
テストデータの漏洩を防ぐために、事前学習および事後学習データセットの構築時には、n-gramマッチングを使用して潜在的にリークしているデータを除外している。具体的には、Qwen2で使用された基準に従い、次の条件を満たす場合は訓練データから対象の訓練シーケンス(st)を削除する。
1. トークン化された訓練シーケンス(st)とテストシーケンス(se)との間で、最長共通部分列(Longest Common Subsequence, LCS)の長さが13以上である。
2. LCSの長さが、訓練シーケンスとテストシーケンスの短い方の長さの60%以上に相当する。
この基準を言い換えると、訓練データ内のシーケンスがテストデータ内のシーケンスと十分に似ている場合、それらは訓練データから排除される。このプロセスにより、評価結果が正確で、公平かつ信頼性の高いものになるようにしている。
5.1 Base Models
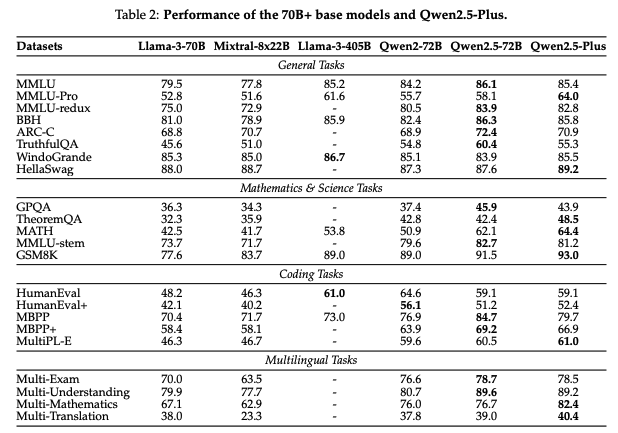
70Bオーバーで比較した場合、Qwen2.5-72Bのベースモデルは、同じカテゴリのモデルを大きく上回り、Llama3-405Bと同等の結果を達成
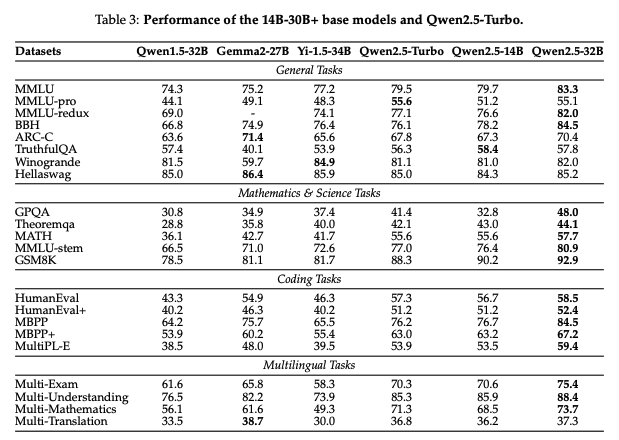
30B級での比較した場合もQwen2.5-32Bは他のモデルよりも優位な結果を示した。 特に数学/コーディングで強いのはQwen2.5 Math/Qwen2.5 Coderを活用できているためなのかなと感じさせる結果でした。
ここでは割愛しますが、7B級モデル/さらに小さいモデルでも同様に優位なベンチマーク結果となっています。
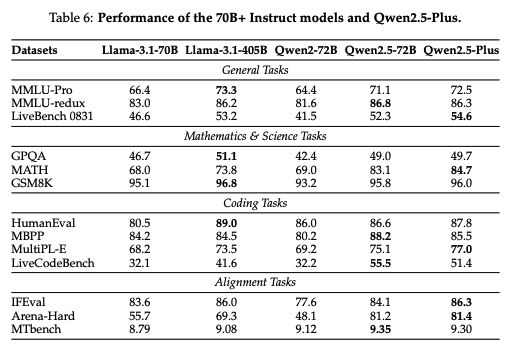
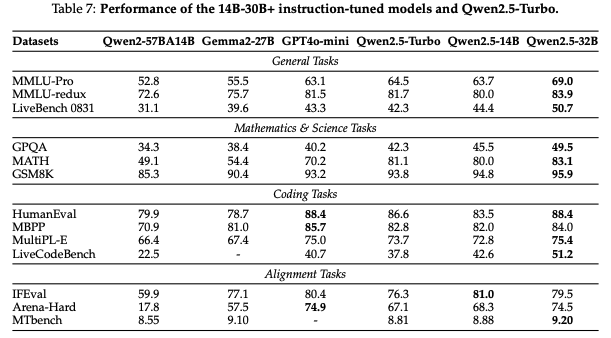
5.2 Instruction-tuned Model
5.1節のBase Modelsの結果と同様に優位な結果となっている。各項目を見ると数学をはじめとした理系の項目に特に強い印象を受けます。
In-house Automatic Evaluation
本節ではQwenチームが独自に作成したデータセットでの評価結果を基本的に和訳しつつ、大事そうなところに絞って掲載します。
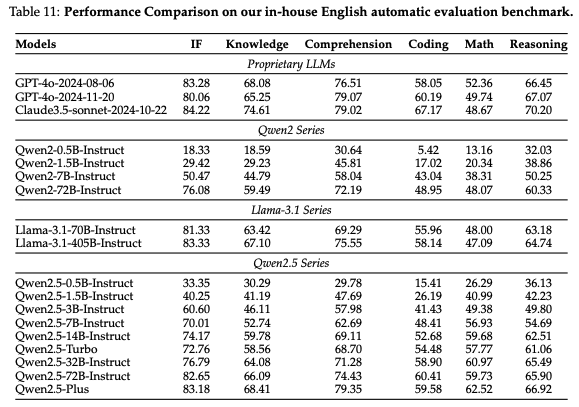
既存のオープンベンチマークデータセットは、LLMs(大規模言語モデル)の能力を完全に評価するには不十分であると考える。これに対処するため、知識理解、テキスト生成、コーディングなど、モデル性能の多様な側面を評価するための社内データセットを開発した。 Qwen2.5-Instrucモデルを、GPT-4、Claude3.5-sonnet、Qwen2、Llama-3.1などの主要言語モデルと比較。評価では、モデルサイズが性能に与える影響と、Qwen2.5シリーズが以前のバージョンや競合モデルに対してどのように改善されているかを分析。
- 小規模モデルでは、Qwen2.5-0.5BがQwen2-1.5Bに匹敵する、またはそれを上回る性能を示した。これは、Qwen2.5シリーズがパラメータの利用効率を最適化し、中規模モデルでも前世代の大規模モデルと同等の性能を達成できることを示している。
- Qwen2.5-3BはQwen2-7Bと同等の性能を発揮。
- Qwen2.5-32Bは、特に数学やコーディングタスクで、以前のQwen2-72Bモデルを大幅に上回った。
- フラッグシップモデルのQwen2.5-72Bは、GPT-4やClaude3.5-sonnetといった最先端モデルに迫る性能を示し、特にLlama-3.1-405Bと比較して、指示フォローを除くすべてのメトリクスで同等またはそれ以上の結果を達成。
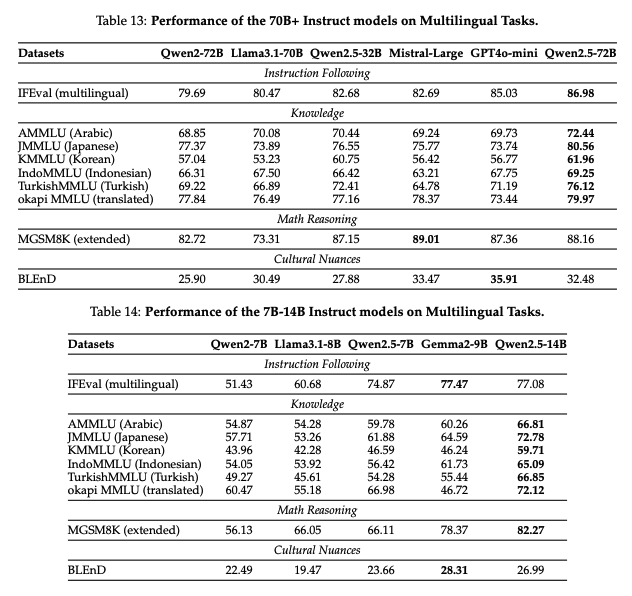
指示調整済みモデルの多言語対応能力を評価するために、P-MMEvalに従い、以下のようなベンチマークを拡張。
- IFEval(多言語対応)
- 英語ベースのIFEvalを多言語例に拡張し、特定の言語に依存するコンテンツ(例:「Aで始まる文字」)を排除。
(Aで始まる単語は英語圏では大事ですが、他の言語だと意味をなさないこともあるので公平性の観点で排除していると思われます)
- 英語ベースのIFEvalを多言語例に拡張し、特定の言語に依存するコンテンツ(例:「Aで始まる文字」)を排除。
- 知識活用
- 複数のMMLU形式のベンチマークを使用し、多言語での知識活用能力を評価。
- 使用したベンチマーク
- AMMLU(アラビア語)
- JMMLU(日本語)
- KMMLU(韓国語)
- IndoMMLU(インドネシア語)
- TurkishMMLU(トルコ語)
- 英語版MMLUを多言語に翻訳したokapi MMLUも評価に使用。
- MGSM8K(拡張版)
- 元のMGSM8Kベンチマークを基に、アラビア語、韓国語、ポルトガル語、ベトナム語に対応を拡張。
- 文化的ニュアンス
- BLEnDベンチマークを使用し、文化的な微妙さを理解する能力を評価。
指示フォロー、多言語知識、数学的推論において、Qwen2.5は同等サイズのモデルと遜色ない競争力を示した。前モデル(Qwen2)と比較して、文化的ニュアンスの理解においても顕著な改善が見られましたが、この分野ではさらなる改良の余地があるとのこと。
Reward Model
本節では、報酬モデルの評価結果について基本的に内容を翻訳して記載します。
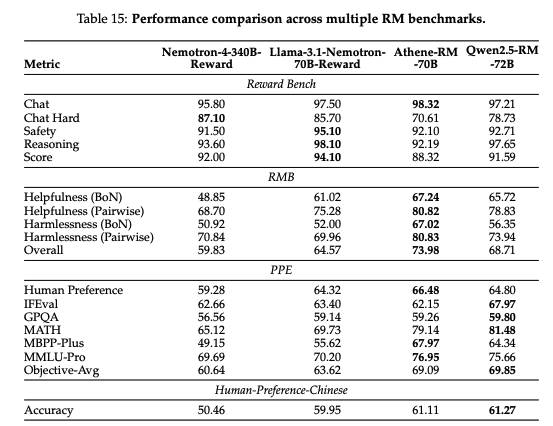
評価結果によれば、Reward BenchではLlama-3.1-Nemotron-70B-Rewardが最も高い性能を示し、RMBベンチマークではAthene-RM-70Bが最良の結果を記録している。一方で、Qwen2.5-RM-72Bは、PPEとHuman-Preference-Chinese評価においてトップの成績を収め、RMBではAthene-RM-70Bに次ぐ2位、Reward BenchではLlama-3.1-Nemotron-70B-Rewardには若干劣るものの、Nemotron-4-340B-Rewardと同等のパフォーマンスを達成している。
筆者の主張では、報酬モデルの評価方法に課題があり、Reward Benchに依存することはイマイチとのことですが、Nemotron-4-340B Rewardと遜色のない評価結果となっているので、悪い結果ではないと思います。
Long Context Capabilities
最後に本節ではコンテキスト長に関する評価結果を必要そうな部分だけ翻訳して掲載します。
Qwen2.5-72B-Instructはすべての文脈長において最も優れた性能を発揮し、既存のオープンウェイトの長文脈モデルや、GPT-4o-miniやGPT-4といったプロプライエタリモデルを大幅に上回る結果を示した。 さらに、図2に示されるように、Qwen2.5-Turboは1Mトークンのパスキー検索タスクにおいて100%の精度を達成しており、超長文脈から詳細な情報をキャプチャする卓越した能力を証明している。
6. Conclusion
Qwen2.5は、大規模言語モデルの分野で重要な進展を示しており、18兆トークンを使用した強化された事前学習と、教師付きファインチューニングや多段階強化学習を含む高度な事後学習技術を備えている。これにより、人間の嗜好への適合性、長文生成、構造化データの解析能力が向上し、指示フォロータスクにおいて非常に効果的なモデルとなった。Qwen2.5は0.5Bから72BパラメータまでのOSSモデルと、Qwen2.5-TurboやQwen2.5-Plusといったコスト効率の高いMoEバリアントを含むAPIモデルが利用可能。
実証的な評価では、Qwen2.5-72B-Instructは、最先端モデルであるLlama-3-405B-Instructと同等の性能を発揮しながら、そのパラメータ数は6分の1に抑えられています。また、Qwen2.5は、専門分野に特化したモデルの基盤としても機能し、その汎用性が示されている。
さいごに
最後まで長文にお付き合いいただきありがとうございました!
個人的に、Qwen2.5モデルはQwen1, Qwen2の内容や、世の中のさまざまな進歩を惜しみなく取り入れて、高精度を達成した素晴らしいモデルだと思います。
弊社でも最近はQwen2.5を活用するシーンが増えています。私自身もよく使用するのですが、1年前のOSSモデルと比較するとその性能の高さに驚かされるばかりです。
o1を筆頭に推論でのブレイクスルーもあり、OSSモデルもまだまだ発展途上なので、日本でも一緒にLLM界隈を盛り上げていければと思っています!!
採用募集中
ABEJAは、テクノロジーの社会実装に取り組んでいます。 技術が好きな方、技術を社会やビジネスに組み込んでいく方法を考えるのが好きな方は、下記採用ページからエントリーください。 新卒の方やインターンシップのエントリーもお待ちしております!
