
ABEJAでデータサイエンティストをしている岩城です。
NVIDIA H200 GPUはハイパフォーマンスコンピューティング (HPC) ワークロード向けに設計されたもので、LLMの推論を高速に行うことができます。 現在では様々なクラウドコンピューティングサービスがH200を提供しています。 今回は、NVIDIA H200を搭載したGPUサーバでどれくらいの規模のLLMの事前学習を行うことができるのか検証しました。
概要
NVIDIA H200 × 8が1ノードというGPU環境でどれくらいの規模の事前学習が行えるか試してみました。 検証に用いたモデルはQwen3シリーズで、0.6B ~ 32Bまでのサイズのモデルについて、それぞれどれくらいのシーケンス長まで学習を回せるか検証を行いしました。
環境
今回は、株式会社ハイレゾ様のGPUクラウドサービス「GPUSOROBAN」のGPUサーバを利用させていただきました。
弊社はハイレゾ様とパートナーシップを締結しています。
今回の検証では、NVIDIA H200 × 8基を搭載したシングルノードのサーバを使用しました。 ハイレゾ様からいただいた手順書の通りに進めることで簡単にサーバへ接続でき、迅速に作業を開始できました。
サーバ環境については以下の通りです。
| GPUサーバ | H200 × 8基 × 1ノード |
| OS | Ubuntu 24.04 |
| Driver | NVIDIA Driver 570.133.20 |
| CUDA | 12.8 |
弊社では以前の記事でも、ハイレゾ様のサーバ環境で大規模モデルを使用した検証を行っています。
実験
今回は主に以下の2つについて検証しました。
- どれくらいの規模のLLMの事前学習が可能か
- どれくらいのトークン長まで事前学習が可能か
検証に用いたモデル、トークン長は以下の通りです。
モデル
- Qwen3-0.6B
- Qwen3-1.7B
- Qwen3-8B
- Qwen3-14B
- Qwen3-32B
トークン長
- 1024
- 4096
- 8192
- 16k
- 32k
- 128k
学習には NVIDIAのNeMo Framework (NeMo 2.0) を用いました。NeMo 2.0ではバージョン2.4.0以降でQwen3シリーズの学習のためのrecipe(パラメータ設定済みの学習スクリプト)がサポートされています。
学習データはそれぞれのトークン長ごとに、そのトークン長のドキュメント100件で構成されたデータセットを作成し使用しました。
また、GPU効率を向上させるための並列化機能は、Tensor parallelismとPipeline parallelismについて以下の複数の設定で実験を実施しました。
| tensor model parallel size | pipeline model parallel size | |
|---|---|---|
| 1 | 8 | 1 |
| 2 | 4 | 2 |
| 3 | 2 | 4 |
Sequence parallelismは常に有効としました。 検証を行った並列化設定は上の3つです。Pipeline parallel sizeが8のときは入れていませんが、これはPipeline parallel sizeがモデルのレイヤ数を割り切れる数値にする必要があり、今回使用したモデルは8で割り切れないためです。
その他、GPU効率に影響のある実験設定は以下の通りです。
| precision | bf16-mixed |
| global batch size | 32 |
| micro batch size | 1 |
| num gpus | 8 |
| num nodes | 1 |
| max steps | 50 |
これらの設定から、実際に学習されるトークン数はデータのトークン長に依存して以下のようになります。
| トークン長 | 学習トークン数 |
|---|---|
| 1024 | 1,638,400 |
| 4096 | 6,553,600 |
| 8192 | 13,107,200 |
| 16k | 25,600,000 |
| 32k | 51,200,000 |
| 128k | 204,800,000 |
結果
学習可能性
それぞれの設定で学習が回ったか否かの結果は以下です。Parallelismsについては、 T{s}がサイズ s のTensor parallelismを指し、 P{s} がサイズ s のPipeline parallelismを指します。
| Model size | Parallelisms | 1024 | 4096 | 8192 | 16k | 32k | 128k |
|---|---|---|---|---|---|---|---|
| 0.6B | T8, P1 | ✔︎ | ✔︎ | ✔︎ | ✔︎ | ✔︎ | ✔︎ |
| 0.6B | T4, P2 | ✔︎ | ✔︎ | ✔︎ | ✔︎ | ✔︎ | ✔︎ |
| 0.6B | T2, P4 | ✔︎ | ✔︎ | ✔︎ | ✔︎ | ✔︎ | ✖️ |
| 1.7B | T8, P1 | ✔︎ | ✔︎ | ✔︎ | ✔︎ | ✔︎ | ✔︎ |
| 1.7B | T4, P2 | ✔︎ | ✔︎ | ✔︎ | ✔︎ | ✔︎ | ✔︎ |
| 1.7B | T2, P4 | ✔︎ | ✔︎ | ✔︎ | ✔︎ | ✔︎ | ✖️ |
| 8B | T8, P1 | ✔︎ | ✔︎ | ✔︎ | ✔︎ | ✔︎ | ✖️ |
| 8B | T4, P2 | ✔︎ | ✔︎ | ✔︎ | ✔︎ | ✔︎ | ✖️ |
| 8B | T2, P4 | ✔︎ | ✔︎ | ✔︎ | ✔︎ | ✔︎ | ✖️ |
| 14B | T8, P1 | ✔︎ | ✔︎ | ✔︎ | ✔︎ | ✔︎ | ✖️ |
| 14B | T4, P2 | ✔︎ | ✔︎ | ✔︎ | ✔︎ | ✔︎ | ✖️ |
| 14B | T2, P4 | ✔︎ | ✔︎ | ✔︎ | ✔︎ | ✖️ | ✖️ |
| 32B | T8, P1 | ✔︎ | ✔︎ | ✔︎ | ✔︎ | ✖️ | ✖️ |
| 32B | T4, P2 | ✔︎ | ✔︎ | ✔︎ | ✖️ | ✖️ | ✖️ |
| 32B | T2, P4 | ✔︎ | ✔︎ | ✖️ | ✖️ | ✖️ | ✖️ |
結果を見て、思っていたより大きめの規模の学習まで回せたなという所感でした。 32Bクラスのモデルでもけっこう長めのトークン長まで学習できました。
実行時間
実行時間については、NeMo loggerの開始時刻と終了時刻の差で観測しました。
比較結果は以下です。

x軸がトークン長、y軸が実行時間(分)となっており、OOMになった箇所は描画していません。x軸は対数をとっています。
以下は、この結果をもとに実行時間をトークン長で回帰した結果です。
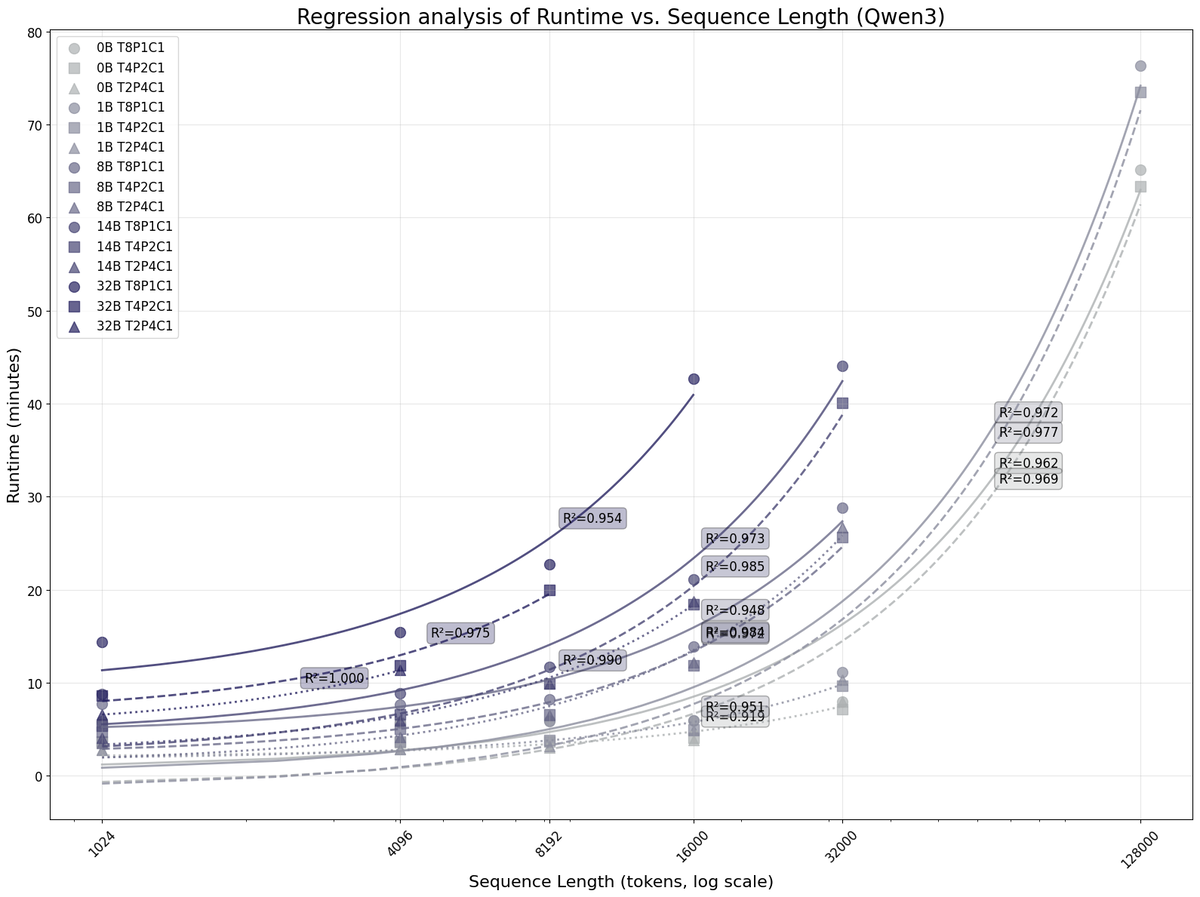
サンプル数が少ないので何とも言えませんが、これを見ると学習トークン長が長くなるについてれ実行時間が線形に増えていることがわかります。32Bモデルはサンプルが少ないため有意な結果は得られませんでした。それ以外のモデルサイズと設定については、p < 0.005で有意な結果となりました。
GPUメモリ使用状況
GPUメモリ使用状況については、学習中に nvidia-smi コマンドを用いて10秒ごと集計ました。10秒ごとに8基のGPUメモリ使用量の平均を取り、学習中の最大値を比較しました。

y軸がGPUメモリ使用状況 (MiB)でx軸がトークン長です。OOMになった組み合わせは、GPUメモリの上限である143,771 MiBで描画しています。
今回の検証内容では、Tensor parallelismがよりGPUを効率的にできるという結果になりました。しかし、これは学習環境や設定に応じて変わってくると考えられます。あくまで、今回実施した実験設定での結果となります。
次に、上のGPUメモリ使用量が最も大きかった時点について、8基のGPUメモリ使用量の標準偏差をとり比較しました。

これを見ると、今回の検証内容ではTensor parallelismが満遍なくGPUリソースを使えているのに対し、Pipeline parallelismによってGPUごとの偏りが比較的発生していることがわかります。
Pipeline parallelismがうまく機能しなかった原因として、micro batchを1に固定していたことが挙げられます。特にPipeline parallelismのサイズを4としていたときは、4つのGPU中1つが稼働し、他3つがアイドル状態の時間が生じたことでGPU負荷が偏ったと考えられます。
最後に
今回はH200 × 8 × 1というGPU環境でどれくらいの規模の事前学習が回せるかを検証してみました。
正直、1ノードでここまでの規模の学習を回せるとは思っていなかったので、素直に驚いています。
謝辞
本検証において、GPUクラウドサービス「GPUSOROBAN」のGPUサーバをご提供いただきました株式会社ハイレゾ様に、心より御礼申し上げます。
We are hiring!
ABEJAは、テクノロジーの社会実装に取り組んでいます。 技術はもちろん、技術をどのようにして社会やビジネスに組み込んでいくかを考えるのが好きな方は、下記採用ページからエントリーください! (新卒の方やインターンシップのエントリーもお待ちしております!)
