
はじめに
こんにちは、ABEJAでプロジェクトマネージャーをしている服部と申します。これはABEJAアドベントカレンダー2024の24日目の記事です。昨年は入社したばかりでドローンについて書いたのですが、今年はHuman in the Loopを意識したRAGの運用について書かせていただきます。(ドローンもどこかで書きたい)
改めてLLM・RAGの運用や、人の働き方について考える機会にしていただければ幸いです。
Human in the Loop
なぜAI運用の中に人を組み込むことが必要なのかというと、現状、AIに100%の精度を求めるのが難しいケースが多いからです。 100%どころか、80~90%以上を求めようとするとそれなりの開発投資や期間が必要になります。 よくあるAI開発の失敗ケースとして「xx%以上の精度になったら実装しよう!」と意気込んだは良いものの、結局そこに達することなくPoCで終わってしまうことが挙げられます。 そうした事態を回避できるものとして、Human in the Loop(以下HITL)があります。一般にHITLは、人とAIが協調してオペレーションする環境を創出する仕組みです。
(ABEJAでは、ミスを起こせないミッションクリティカル業務においても、HITLを用いることで精度を担保し、かつ初期段階から実運用を可能にしています。)
という前提をおきつつ、今回はライトで汎用的な事例として問い合わせボットを題材に、RAGの精度が足りずにボットが満足の行く回答を出せなかった際に人がとるべき支援のプロセスを作っていきます。
システム概要
RAGを使うということで、界隈では一番メジャー(?)なDifyで仕組みを作ってみようと思います。Jinba-flowとかでも良いと思います。使用したDifyのバージョンは0.13.2です。
下記リンクにDSLファイルを添付するので、これを参考に後述の準備をいただければそのまま利用可能です。 URLからコピーしてご利用ください。(2ファイルのうち、下方にあるかもです。)
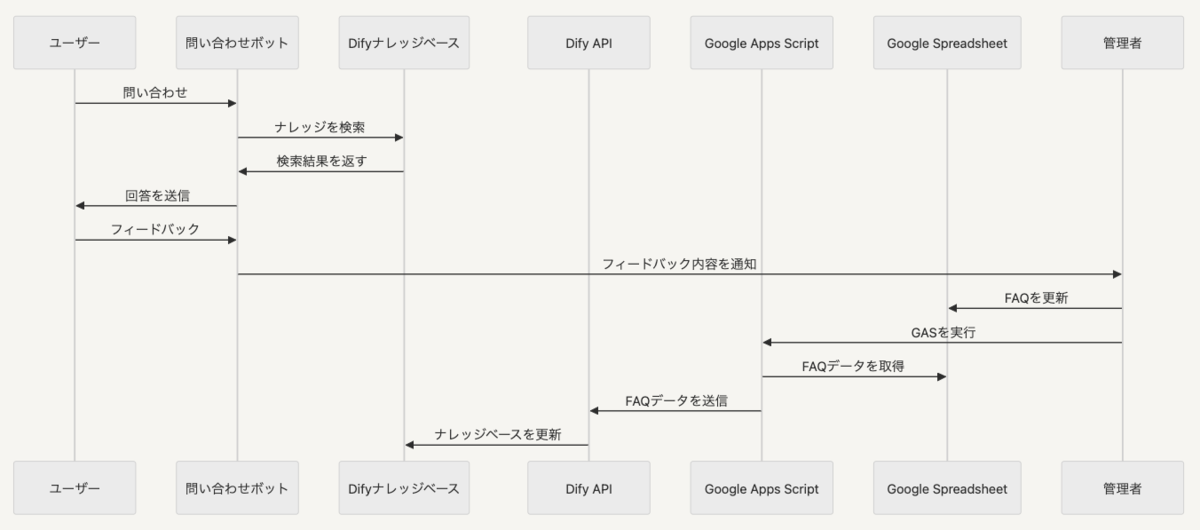
大まかな動きとしては、ユーザーからの問い合わせに対して、まず、LLMが登録されたドキュメントを参照して回答します(RAG)。 ここで回答できなかった内容に関してユーザーがフィードバックすると、担当者に連絡メールが行き、担当者は正しい回答をFAQに登録します。 以降同じ内容の質問が来たら、自動で回答できるようになっています。
ワークフローの解説

ワークフローの分岐
ワークフローの分岐順序は下記のようになっています。
- 質問対応
- 「FAQ」から回答
- 「公式ドキュメント」から回答
- フィードバック対応
静的・動的なナレッジベースの使い分け
このワークフローのポイントは、「公式ドキュメント」(公的な資料や社内規定などをイメージ)と「FAQ」とを静的・動的なナレッジベースとして使い分けていることです。以降この2つのナレッジを想定して話をします。
LLMによる回答が仮に質問者の期待に添えない内容だった場合には、問い合わせの担当者に質問内容と回答内容、希望によっては質問者のメールアドレスがメールされるようになっています。 これを見た担当者は、登録してある「公式ドキュメント」では回答できなかった(原因はそもそも該当情報がなかったかもしれないし、あってもRAGの精度問題で回答できてないかもしれないがそれは置いておいて)質問に対して模範的な回答を「FAQ」に明示的に追加します。 質問回答のフロー中、「FAQ」を優先して参照するようにしているので、少なくとも、以降同じような質問が来たらちゃんと回答できるようになっています。
本システムにおいてFAQは、人の介入ポイントになっており、HITLの要です。FAQを運用することで、下記のメリットがあると考えています。
- 高速な検索: よくある質問(FAQ)を先に検索することで、元の膨大なドキュメント群を検索する手間を省き、問い合わせに対する応答速度が向上します。
- 正確性の向上: QA形式の構造化されたナレッジを活用することで、曖昧な応答を減らし、信頼性の高い回答を提供できます。
- RAGの精度不足をリカバリーする改善サイクル: RAGは既存のナレッジベースに依存して回答を生成するため、ナレッジが不足している場合には適切な回答を提供できないことがあります。このような場合でも、即座に回答できなかった質問をFAQに追加することによって、次回以降は自動的に対応可能になります。ここは公式ドキュメントが即座に修正・補完しにくい性質とは対照的です。
実装手順
用意するもの
本システムを構築するのに必要な環境は下記です。
- メールサービス(gmail等)
- IMAP有効化
- Dify
- ナレッジベースのAPI発行
- Google Work Space
- spread sheet IDの取得
- GASの実行
メールサービスの準備(IMAP有効化)
Gmailを例に、IMAPを有効化します。Outlookなど他のメールサービスでも可能です。
- Gmailの設定にログイン
- Gmailにログインし、右上の歯車アイコンから「すべての設定を表示」を選択
- 「メール転送とPOP/IMAP」タブを開く
- 「IMAPアクセス」>「IMAPを有効にする」
- Googleアカウントでアプリパスワードを生成
- Googleセキュリティ設定にアクセス
- 「2段階認証プロセス」を有効にする
- 「Googleにログインする方法」>「2段階認証プロセス」>「アプリパスワード」
- アプリパスワードを設定する(アプリ名はgmail、とか適当に)
- パスワードが生成されるので、これをメモしておく
- Googleセキュリティ設定にアクセス
Difyの準備
ナレッジベースの操作を含めたDifyの基本的な利用方法はにゃんたさんの動画がおすすめです!
DifyでDSLファイルを読み込む:
- こちらからダウンロードする。(ファイル名「【雛形】RAGOps.yml」)
- Difyにインポートしてアプリを展開してください。
インポートしたアプリを開き、emailツールを設定する(Gmailの場合):
- Email Account: Gmailアドレス(例:
example@gmail.com) - Email Password: アプリパスワード(生成した16文字の文字列)
- SMTP Server:
smtp.gmail.com - SMTP Server Port:
587(TLS)または465(SSL) - Encrypt Method: TLS(またはSSL)
- Email Account: Gmailアドレス(例:
send emailノードに情報を入力する:
- Recipient email account: 送信先メールアドレス
email content: 送信したい内容(今回は担当者に更新してもらうFAQフォーム)

Difyで2つのナレッジベースを作成:
- 2つのナレッジベース(今回は「公式ドキュメント」と「FAQ」)を作成する。
- 「公式ドキュメント」には回答に参照したいドキュメント類をとりあえず全部入れてしまってください。(私は「公式ドキュメント」にABEJAの採用ページの情報や経産省のAI事業者ガイドラインなどを入れました。「FAQ」は空でも大丈夫です)
ナレッジベースのAPIを取得:
DifyにはナレッジベースのAPIがあり、これを通じて動的にデータを追加・更新できます。APIキーの取得方法はDify公式をご参照ください。
「FAQ」ナレッジベースIDを取得:
FAQの動的な管理をAPIで行うために、ナレッジベースごとのIDが必要になるのですが、GUIを探しても見つからなかったので、上述のAPIを用いて探しました。
curl --location --request GET 'https://api.dify.ai/v1/datasets' --header 'Authorization: Bearer {API_KEY}'注:
https://api.dify.aiは自身の環境のドメインに合わせてください。私はナレッジベースAPIページからコマンドをコピーしたら、httpsの”s”が抜けている罠にかかりました。{API_KEY}は一つ前の手順で取得したものを使用してください。
Google Work Spaceの準備
スプレッドシートの準備
GoogleスプレッドシートをFAQの管理ツールとして利用します。スプレッドシートの構造は以下のように設計します。
| 質問 (Question) | 回答 (Answer) |
|---|---|
| APFとはなんですか? | APFはABEJA Platformの略称です。 |
| HITLとはなんですか? | HITLとは、Human in the Loopの略称です。 |
- 列Aに「質問」、列Bに「回答」を記載。
- シートIDはスクリプトで利用するため控えておきます(URLのうち、
/spreadsheets/d/の次の部分)。
スクリプト概要
今回のGASは以下のような動作を実現します。
- スプレッドシートの内容を取得。
- DifyのFAQナレッジベースにあるデータを削除。
- スプレッドシートのデータをQA単位のチャンクで再登録。
GASの準備
- Google Apps Scriptエディタに下記リンクのスクリプトを貼り付けます。
- 必要な変数(APIキー、ナレッジベースID、スプレッドシートID)を代入します。
- 自身の環境に構築している際は、ドメイン部分
api.dify.aiを修正。 syncFaqsToDifyを実行し、Difyのナレッジベースで同期結果を確認します。下記URLからコピーしてください。
アレンジの余地:
既存FAQの修正も見越して、ナレッジベースの全データを削除後、スプレッドシートの内容を登録し直しています。「追加のみ行う」「チャンクの区切り方を変える」「Contextual Retrievalで最強のFAQを作ってやるぜ!」など夢が広がるところですが、今回は運用の話なのでまた別の機会に。
実運用
テスト
ここまでお疲れ様でした。実際に動作するかDifyで下記テストしてみましょう。
- 「公式ドキュメント」で回答できる内容の質問をして、回答を得る
- 「公式ドキュメント」で回答できない内容の質問をして、回答を得る
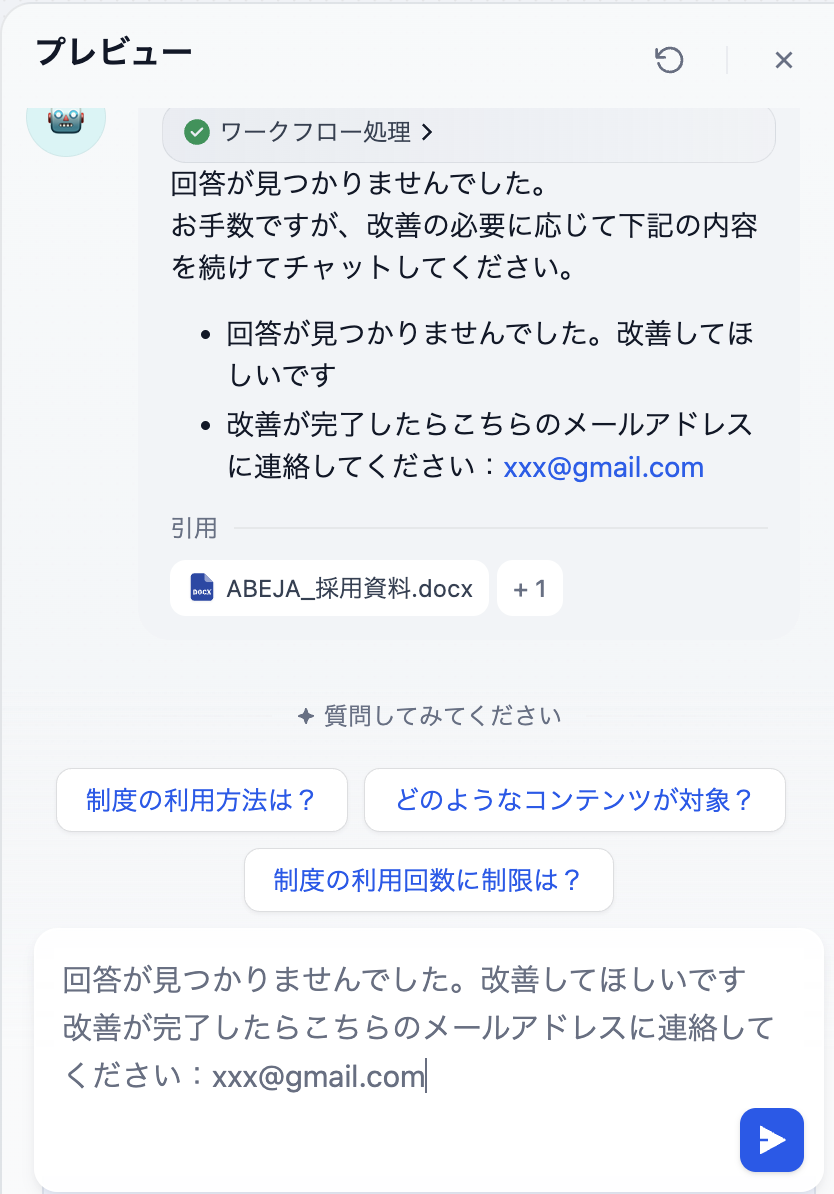
- 回答できない場合に、チャットで「回答が見つからなかった」や「回答が間違っていた」旨を伝える
- 担当者がメールを受信する
- 担当者がメールに記載のスプレッドシートのURLから、FAQの内容を更新する
- マクロ(
syncFaqsToDify)を実行する - (Difyの挙動のせいか、ナレッジベースのGUI上の反映がとても遅いことがあります。私が試したときはFAQの更新内容が表示されませんでしたが、実際には以降のフローで反映できていることを確認しました)
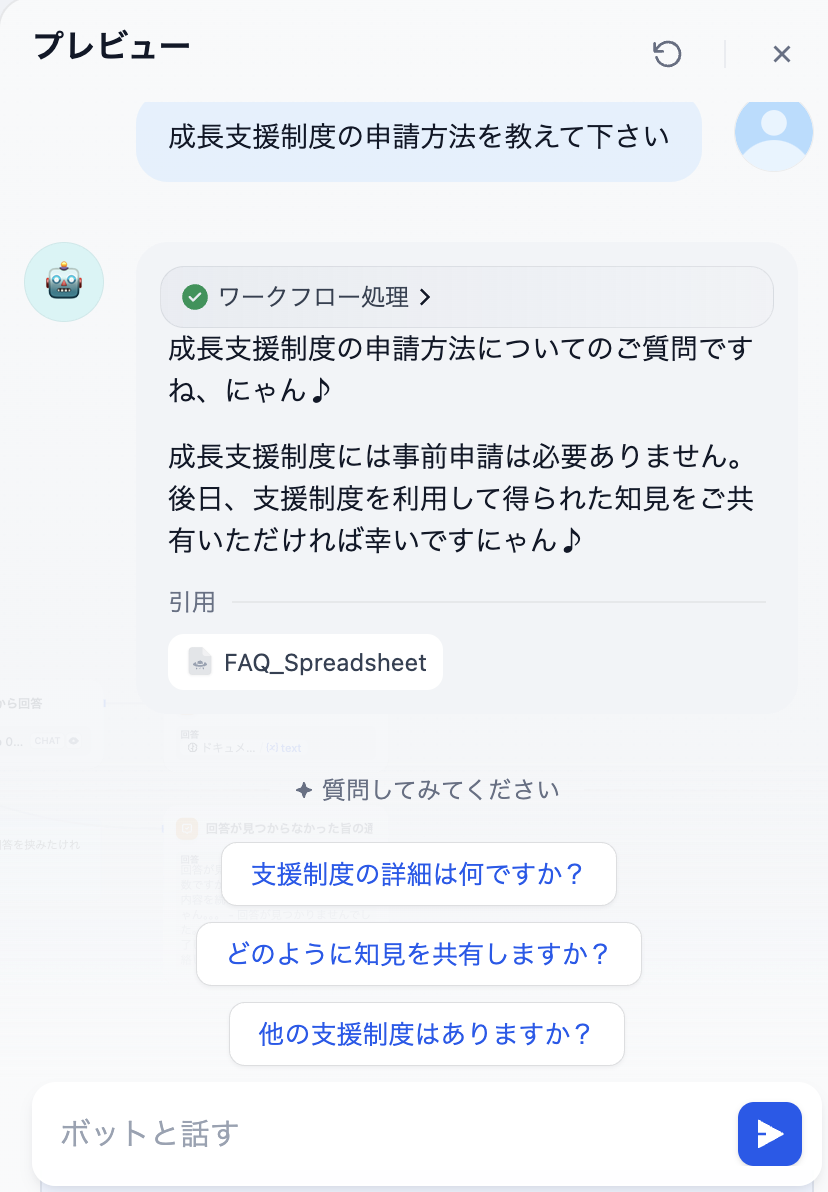
- 再び更新内容に関する質問をして、正しい回答が得られる
運用担当者に渡すマニュアルのイメージ
Difyボットの改善要望メールが担当者に届きます。(メールの文章が見にくいのはここではご容赦ください)

質問者の質問、ボットの回答内容を確認し、メールに添付されたURLのスプレッドシートに質問に対する正しい回答を追加・修正してください。

その後拡張機能タブからマクロを選択し、
syncFaqsToDifyを実行してください。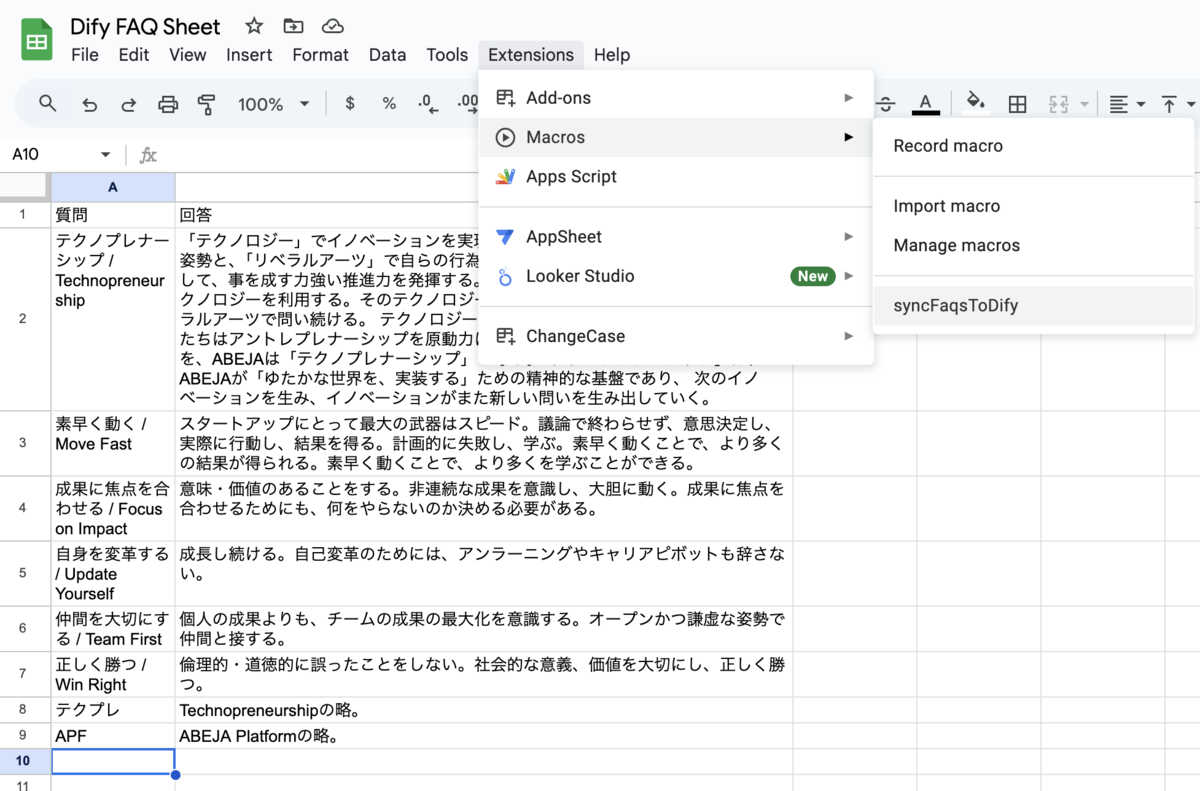
(マクロは画像のようにimportしておいてあげると親切だと思います)
さいごに
今回はLLMによる問い合わせボットのシステムを構築しました。 このシステムの重要性は、 「メールで問い合わせが来たけど、返信文どうしようかな・・・」 「前別の人に答えたけど、資料どこだっけ?」 といったような同じ作業を二度生じさせない点にあると考えます。
人にできることはまだあるかい
ChatGPT以降、自動化できるタスクの幅は大きく広がりましたね。 今回の問い合わせ対応以外にも、 「議事録生成を自動化したい」 「お店の接客対応を自動化したい」 「営業活動を自動化したい」 という話はよく聞きますが、これらは偉人たちのspeech to text・LLM Agent・text to speechなどを用いて、比較的容易に実現できます。 これ以外にも、面倒なことは全部ChatGPTにやらせるという発想は大事だと思っています。
では一方で、面倒なことから開放された人は何をすべきでしょうか?
究極的に言うと、LLMはまだ、一般にデジタル化された言語情報しか学習できていません。 まだデジタル化されていない情報をLLMに教えてあげることは、人の仕事になりえると考えています。
本記事のシステムによって今までの問い合わせ担当者の仕事は対人対応から、FAQ・ドキュメントの改善やメンテナンスに変わります。 「メンテナンス」と聞くとただ仕事が楽になったかのような印象があるかもしれませんが、ここには「理解の難しいドキュメントを質問者が理解できるワードに落とす」「熟練者にヒアリングして、彼らの頭の中の情報を文書化する」などが含まれます。 彼らの活躍によって、情報は会社のナレッジとして活用可能になるのです。
その他
上記テストを実行された方はおわかりかと思いますが、このボット、語尾に「にゃん♪」を付けてきます。
これも表現の良し悪しはさて置き、ユーザーからの不満を溜めづらくするための試みでした。
私のお世話になっているクライアントの方も作業場所としてご愛用の某レストランで走る猫型ロボットからも、それ自身が好まれる設計というのはユーザーとの接点においてとても大事なことがわかるかと思います。
このほか、ユーザーに対して「LLMは完全ではなく、誤った回答をすることがある」などのリテラシーを育成するなども運用と合わせて考慮すべきです。
以上、RAGの精度改善は当然として、本記事が皆様の運用の一助となりますと幸いです。
We Are Hiring!
ABEJAは、テクノロジーの社会実装に取り組んでいます。 技術はもちろん、技術をどのようにして社会やビジネスに組み込んでいくかを考えるのが好きな方は、下記採用ページからエントリーください! (新卒の方やインターンシップのエントリーもお待ちしております!)
特に下記ポジションの募集を強化しています!ぜひ御覧ください!
