こんにちは!ABEJA で ABEJA Platform 開発を行っている坂井(@Yagami360)です。
近年の ChatGPT 等の LLM の飛躍的な発展とマルチモーダル化の流れに伴い、ロボティクス領域においても LLM を活用して、テキストでロボット制御できるようになってきているようです。
LLM に対して画像を入力もできるようにして{画像・テキスト}でのマルチモーダル化したモデルを VLM [Vision-Language Model] といいますが、ロボティクス制御等で LLM を活用できるように更にこれを拡張して、ロボットのアーム制御などの行動ベクトルも入力できるようにして{行動・画像・テキスト}でのマルチモーダル化したモデルを VLA [Vision-Language-Action] モデルといいます。
本記事では、そんな VLA モデルの中でもロボティクス領域におけるツヨツヨモデルである「π0」内部の仕組みを、以下で公開されている論文をベースに自身の解釈を交えながら解説します。
尚、本記事は、π0 内部の原理や仕組みの説明に終始しており、π0 の使用方法等の話は一切記載していません。
近年の LLM のように内部の仕組みはブラックボックスでもモデルを利用したり表面的な改善を行なうには十分ではありますが、 中身の仕組みから理解することで、どのような{学習用データセットの作成・事前学習済みモデルの利用・データオーギュメント・モデルのファインチューニング(特に入出力層)・損失関数の改善}等を行えば、ツヨツヨなロボティクス基盤モデルを開発できるのかのヒントを得ることができるメリットはあるかと思ってます。
またロボティクス領域は、機械学習やソフトウェアで完結している世界ではなく、ハードウェア(機械工学・電子回路等)や組み込みソフトウェアが強く関わってくる領域であり、実際にモデルを実世界で動かそうとまた別の技術領域が必要になりますが、その部分には言及していないです。
π0 とは?
π0 は Physical Intelligence 社が開発した VLA モデルで、テキストで様々なロボット制御が可能なモデルです。
工場の組み立てライン等における従来の産業用ロボットでは、ある決められたタスクを精密に制御することはできても、それ以外のタスクは全くできないという特化型ロボットになっているかと思います。
π0 では、ある決められたタスクだけではく、{洗濯物をたたむ・洗濯器から洗濯物を取り出す・ゴミをゴミ箱に入れる}などの多種多様なタスクをテキストで指示しながら行えるモデルになっており、より汎用的で柔軟な制御を行えるようになっています。
その様子は、以下の公式ブログの動画を見てもらえればと思います。
www.physicalintelligence.company
π0 の優れた点や新規性を簡単にまとめると以下のようになるかと思っています。(詳細は後ほど順次解説していきます)
事前学習済みの VLM モデル PaliGemma に対して、ロボットアームの回転量などの行動ベクトル値を出力する出力層(action expert)を追加して VLA モデルにし、テキスト&画像でロボット制御指示の入力ができるようにしたよ
ロボット制御においては、時系列に連続なデータ(ロボットアームの回転角など)を出力する必要があるので、出力層(action expert)には拡散モデルを発展させた FlowMatching モデルのアーキテクチャを採用して、連続値を出力できるようにしたよ
損失関数に関しては、VLM層をクロスエントロピー損失関数で学習して、出力層(action expert)部分は flow matching loss を使用して学習を行うことで、単一の Transfomer ベースのモデルで学習を行なうことを可能にしたよ
ロボットの状態や行動もトークンとして扱い、PaliGemma 内部の Transformer モデルでも処理可能にしたよ
OXE [Open X-Embodiment] データセットと自前で作成したデータセットを使用して大量の学習用データセットで、この事前学習済み PaliGemma + 出力層(action expert)から構成されるモデルを教師あり学習で事前学習して、画像や言語理解能力及びロボット制御能力を大幅に向上させたよ
自前で作成したデータセットで事後学習して、特定のロボット制御タスクに特化させて精度向上させたよ
こらら工夫により、高周波数(50Hz)での様々なタスクのロボット制御を可能にしたよ
では π0 内部の仕組みの詳細を解説していきます。わかりやすいように π0 の学習フェイズと推論フェイズで分けて解説します。
学習フェイズ
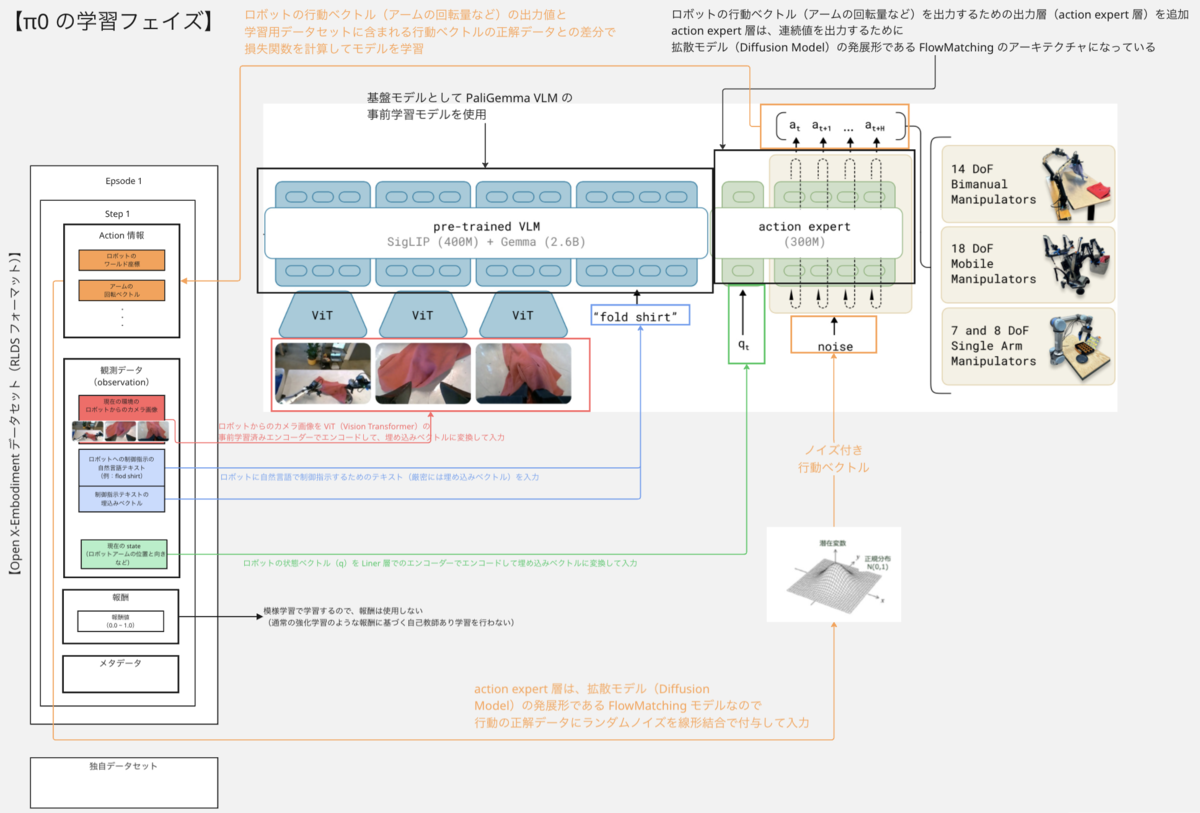
π0 の学習フェイズにおけるアーキテクチャ(モデル・データセット・損失関数等)を1つの図で記載すると上図のようになります。
模倣学習のフレームワークで学習
まず事前として π0 は、ロボティクス用のモデルであるため、他の一般的な「機械学習 x ロボティクス」のモデルと同じく強化学習のフレームワークで学習を行います。
より厳密には、強化学習の1つである模倣学習という手法で学習を行います。(報酬に基づく強化学習ではなく教師あり学習での模倣学習を行います)
*1
ロボティクスモデルでは、強化学習のフレームワークで学習を行なうことが多々ありますが、 π0 は、報酬に基づく強化学習ではなく、模倣学習のフレームワークで学習を行います。
この際に強化学習と同じく{エピソード・状態・行動・行動方策}等の概念がでてきます。これら概念については、以下の記事を参考にしてください。
π0 等の VLA モデルの話では、LLM の側面が見立ちがちですが、{エピソード・環境・報酬・行動・行動方策・エージェント}等の強化学習ででてくる概念の理解が前提になります。
PaliGemma VLM を改良したモデルを基盤モデルとして使用
π0 では、Google 開発の OSS の VLM モデルである PaliGemma の事前学習モデルを基盤モデルとして使用することで、まずは{画像・テキスト}でのマルチモーダルを行えるようにしています。 事前学習済みモデルを使用しているので、この時点で幅広い画像と言語の理解能力を有していることになります。
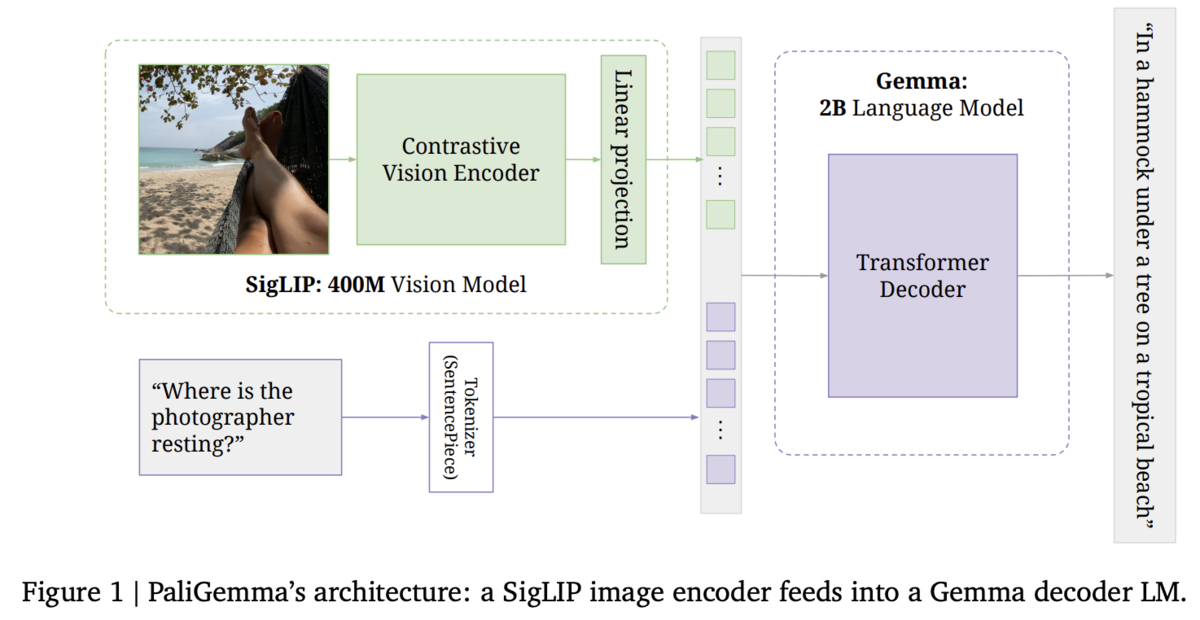
PaliGemma は、上図のようなアーキテクチャのモデルになり、軽量 LLM モデルの Gemma に画像入力の Encoder 入力層を追加して、{画像・テキスト}でのマルチモーダル化したモデルになっています。
画像入力部分は、Vision Transformer(ViT)の Encoder でエンコードすることで、画像データも LLM で扱えるようにしています。 Vision Transformer(ViT)というのは、LLM の基本構造である Transformer(*2)に画像入力できるようにしたモデルです。 Transorformer は、テキストのトークンという離散的なデータを入出力できるモデルになっていますが、画像データは連続値であるのでそのままでは画像データを扱えないです。
ViT では、入力画像を 16x16 などのより小さなバッチ画像に分解して、それぞれのバッチ画像を画像トークンとして離散的に分解してエンコーダーに入力することで、Transformer で画像データを処理できるようにしています。
ViT の詳細は、以下リンク先の記事がわかりやすいです。 qiita.com
π0 モデルの PaliGemma 部分にも、この ViT での事前学習済みエンコーダーが存在し、この部分に学習用データセットに含まれるロボットからのカメラ画像を入力し、ロボットが見ている環境情報をモデルに学習させます。
拡散モデルをベースにした出力層(action expert)を追加
π0 モデルでは、上記事前学習済み PaliGemma に対して、action expert という行動ベクトルを出力する出力層を追加し、VLA モデルにしてロボット制御のための行動(アームの回転量など)を出力できるようにしています。
この際に、LLM などではテキストなどの離散的なデータを出力すればよかったのですが、ロボット制御においては、時系列に連続な行動(アームの回転角など)を出力する必要があるのが大きな問題になります。
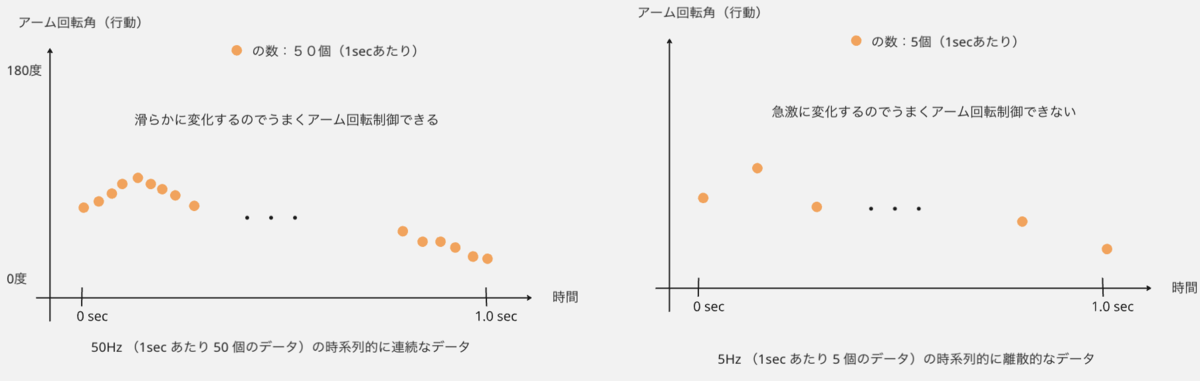
時系列に連続というのはどういう意味かといいますと、強化学習の文脈では、LLM のテキストとは異なりエピソードや時間ステップという概念があるため、各時間ステップ毎に異なる行動や状態や存在します(時間 t におけるアーム回転角、時間 t+1 におけるアーム回転角など)
そのため、ロボット制御するためには上図のような各時間ステップ毎の時系列データが必要になるのですが、この際の時系列データの間隔がまばらで滑らかでない場合、ロボットのアーム回転角など急激な変化になってしまいうまく制御できない事態になってしまいます。
そのため π0 では、出力層(action expert)のネットワーク構造として、拡散モデルの発展形である Flow Matching モデルという画像生成モデルを採用し、50Hz という高周波での時系列的に連続な行動ベクトル(アーム回転量など)出力できるようにしています。
※ 単に Liner 層などの単純な出力層を追加してモデルをファインチューニングするだけではそんなに大した話ではないのですが、時系列に連続な出力を行なえるようにするために Flow Matching モデルという画像生成モデルをカスタマイズして組み込んでいるのがすごいポイントになります
Flow Matching モデルというのは、画像生成モデルの1つで Stable Diffusion 内部で使用されている拡散モデル(Diffusion Model)を発展させたモデルになっています。
拡散モデルの詳細は、以下の記事を確認していただければと思います。 tech-blog.abeja.asia
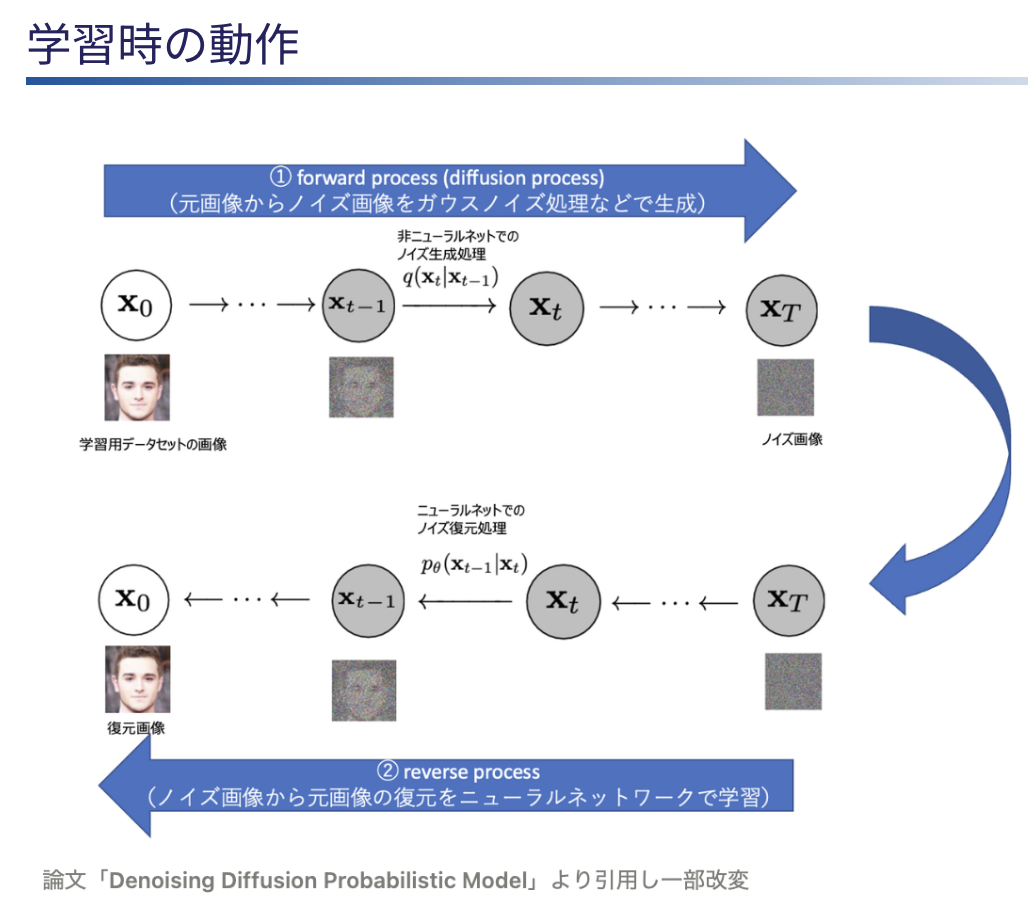
拡散モデルでは、学習時の「画像入力 → ノイズ画像生成 → ノイズ復元画像生成」のプロセスにおいて、いわばノイズ除去関数のようなものを学習しています。 一方で、Flow Matching モデルでは、ノイズ画像(の確率分布)から正解データの画像(の確率分布)に遷移させるためのベクトル場を学習しているのが大きな相違点になります。 但し π0 の文脈においては、画像ではなく行動を扱うので、行動ノイズ(の確率分布)から正解データの行動ベクトル(の確率分布)を復元するベクトル場を学習する形になります。
例えば、ロボット行動として「グリッパー開閉量とアーム高さ」という例をとると、学習しているベクトル場は以下のようなイメージ図になります。
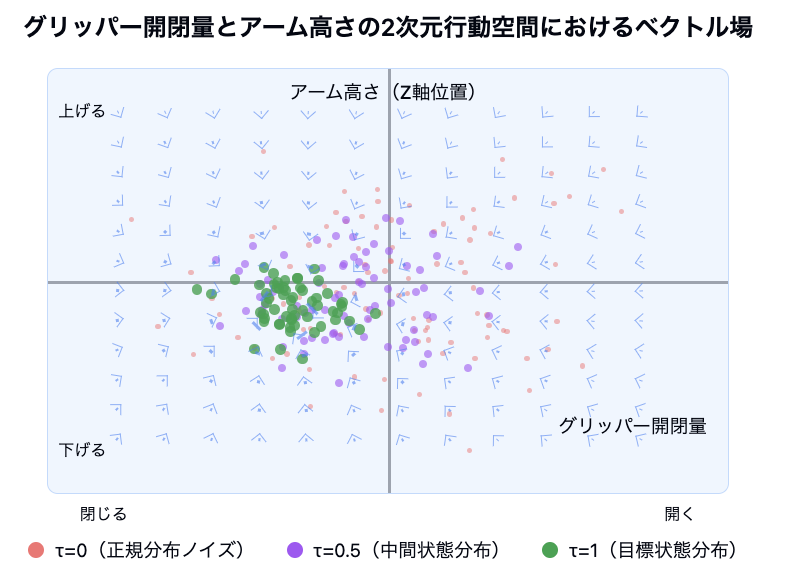
青色の矢印がベクトル場です。このベクトル場は、初期の完全にランダムな正規分布での確率分布から、「グリッパーを閉じながら適切な高さでアームを位置させる」という正解行動を生成する確率分布に遷移させるためのベクトル場になっており、Flow Matching モデルではこのベクトル場を学習しています。
Flow Matching モデルでは、拡散モデルと比較して推論時の計算効率やサンプリング効率に優れているというメリットが存在します。 これ故に π0 では、50Hz という高周波での時系列的に連続な行動ベクトルを出力しても十分な処理速度で推論することを実現しているようです。
OXE [Open X-Embodiment] データセット + 自前データセットで事前学習
LLM の基本構造である Tranformer は、内部の Attention 構造の性質上、大量のデータセットを必要とするデータハングリーなモデルになっています。
そのため、LLM 系統のモデルの事前学習の際には、大量のデータセットを如何にして作成するのかが大きな課題になってきます。
π0 では、OXE [Open X-Embodiment] データセットという OSS で公開されているデータセットに自前で作成したデータセットを加えて、上記の PaliGemma VLM + action expert で構成される π0 モデルを、大量のデータセットで教師あり学習での事前学習(模倣学習)を行っています。
OXE [Open X-Embodiment] データセットは、ロボティクス用途で利用可能な OSS(Apache-2.0 license)のデータセットで、以下で公開されています。 github.com
中身のデータは、以下のような22種類の様々なロボットから収集したデータになっており、物を掴んで置く・移動などの 527種類のアクション操作スキルデータを含んでいます。

また RLDS [Reinforcement Learning Datasets] という強化学習のフレームワーク(エピソード・ステップ・行動・報酬など)に準じたフォーマットで保存されています
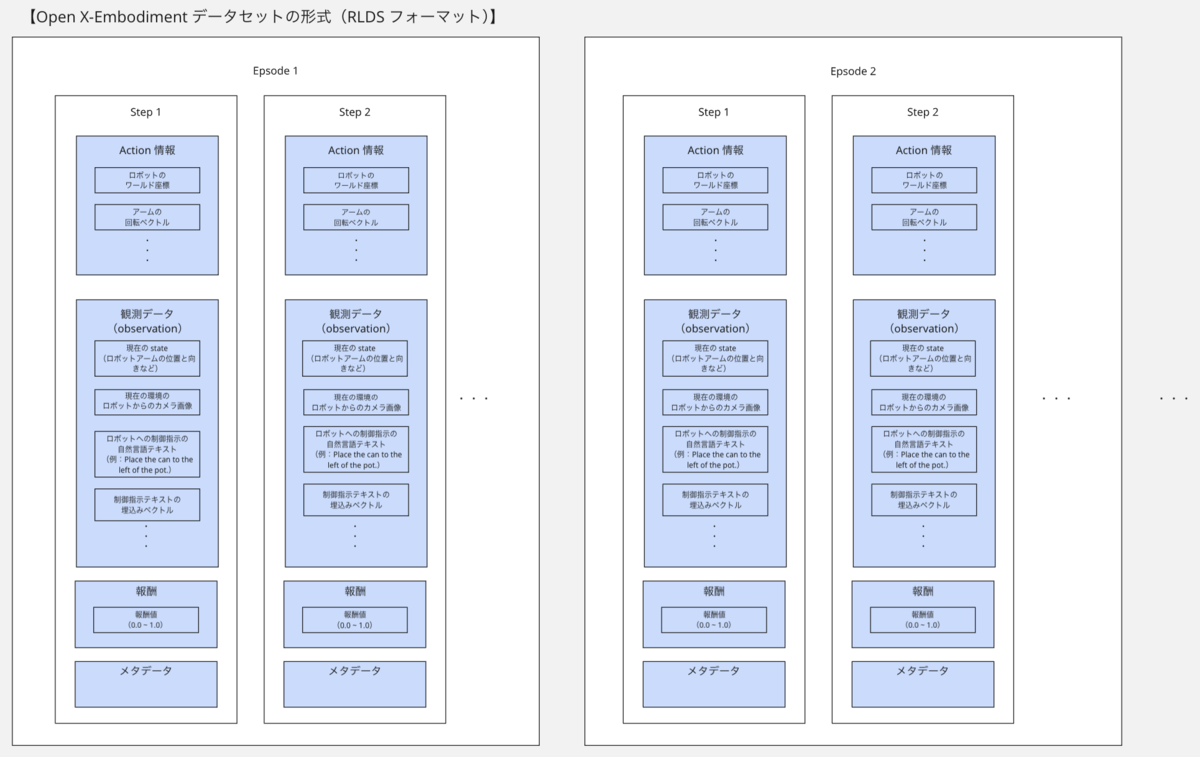
例えば22種類のロボットの1つである「bridge」における、1つの Epsode の中の 1 Step のデータは、以下のようになっています。このようなデータは複数の Epsode と Step 毎に存在します。
# 観測データ(observation) ('observation', # ロボットからのカメラ画像データ {'image': <tf.Tensor: shape=(480, 640, 3), dtype=uint8, numpy=array([[[ 83, 88, 91], [ 92, 97, 100], [ 95, 100, 103], ..., [ 12, 16, 19], [ 11, 15, 18], ... # ロボットへの制御指示の自然言語テキストの埋込みベクトル 'natural_language_embedding': <tf.Tensor: shape=(512,), dtype=float32, numpy= array([ 2.30294447e-02, 6.05173744e-02, -5.20481169e-02, -2.47768629e-02, 1.08427750e-02, 9.11148265e-03, -5.82255470e-03, -5.61384659e-04, # ロボットへの制御指示の自然言語テキスト 'natural_language_instruction': <tf.Tensor: shape=(), dtype=string, numpy=b'Place the can to the left of the pot.'>, # 現在の状態(state):グリッパーの状態 + ロボットアームの位置と向き 'state': <tf.Tensor: shape=(7,), dtype=float32, numpy=array([ 0.29806843, -0.11465699, 0.10782038, 0.04275148, -0.14888743, -0.31455365, 1.0001532 ], dtype=float32)>} ) # 行動(action)データ ('action', { 'open_gripper': <tf.Tensor: shape=(), dtype=bool, numpy=True>, 'rotation_delta': <tf.Tensor: shape=(3,), dtype=float32, numpy=array([ 6.077167e-07, -1.193009e-07, 1.308389e-07], dtype=float32)>, 'terminate_episode': <tf.Tensor: shape=(), dtype=float32, numpy=0.0>, 'world_vector': <tf.Tensor: shape=(3,), dtype=float32, numpy=array([1.9514002e-10, 8.0674190e-11, 2.9859176e-10], dtype=float32)> } ) # 報酬 ('reward', <tf.Tensor: shape=(), dtype=float32, numpy=0.0>) # メタデータ:状態(state)フラグ ('is_first', <tf.Tensor: shape=(), dtype=bool, numpy=True>) ('is_last', <tf.Tensor: shape=(), dtype=bool, numpy=False>) ('is_terminal', <tf.Tensor: shape=(), dtype=bool, numpy=False>)
π0 においては、このデータセットにおける各データを最初のアーキテクチャ図のようにモデルに入力しています。
- 行動データ
- 正解データとして使用しています。具体的には、π0 モデルの出力値(行動ベクトル)との値で損失関数を取る際の正解データとして利用し、π0 モデルがこの正解データの出力に近づくようにモデルのネットワークが学習されます
- また、π0 出力層(action expert)は、拡散モデルをベースにした noize 入力を行なうモデルになっているので、出力層へのノイズ入力側にも入力します
- 観測データ
- ロボットからのカメラ画像
- π0 モデルの PaliGemma の ViT Encoder 部分に入力し、ロボットが見ている環境情報をモデルに学習させるのに使用しています
- ロボットへの制御指示テキスト、及びその埋め込みベクトル
- π0 モデルの PaliGemma のテキスト入力層に入力し、テキストとロボットの行動を関連付けを学習するのに使用しています
- ロボットの状態(グリッパーの状態 + ロボットアームの位置と向きなど)
- π0 モデルの出力層(action expert)に入力し、現在のロボットの状態から適切な行動をモデルに学習されるのに使用しています
- ロボットからのカメラ画像
- 報酬データ
- π0 では、報酬に基づく強化学習ではなく教師あり学習での模倣学習を行なうので、報酬データは使用していないようです
画像や状態・行動などもトークン化
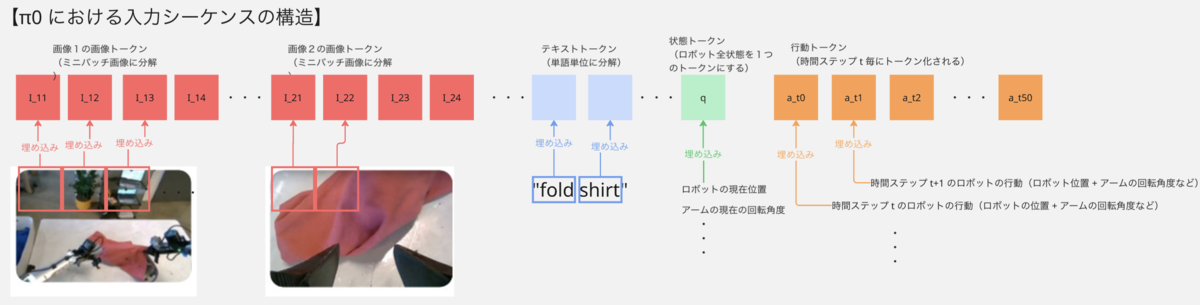
π0 は LLM のモデル(PaliGemma)を基盤モデルとしていますが、LLM 内部の Transformer 構造(より具体的には Attention 構造)ではテキストのトークン(の埋め込みベクトル)という離散的なデータを扱うことはできても時系列的に連続なデータをそのまま扱うことができない問題があります。
従来の強化学習では、状態(state)と行動(action)は実数値のベクトルとして扱いますが、π0モデルではこれらを LLM 内の Transformer のアーキテクチャで処理できるように、状態(state)と行動(action)もトークンとして扱い、上図のようなシーケンスとして配置にすることで各トークン位置情報も付与し、Transformer で処理できるようにしています
画像トークン
1枚の画像を 16x16 などの小さなバッチに分割して、PaliGemma 内部の事前学習済み Vision Transformer(ViT)のエンコーダーでエンコードして埋め込みベクトルに変換します。 このバッチ単位で分割された画像の埋め込みベクトルを画像トークンといいます。バッチ単位で分割された画像なので、各画像トークンは全体画像における位置情報も含んでいます。状態(State)トークン
ロボットの現在位置やアームの回転量などの全状態のベクトルを Liner 層で埋め込みベクトルに変換します。この埋め込みベクトルを状態(State)トークンといいます。 状態トークンは(全状態を管理するので)1つのみ存在し、上図のようにテキストトークンと行動トークンの間に配置します。 これにより、状態トークンにもトークン位置の情報も持たせることができ、Transformer 内部の Positional Encoding の構造で位置情報を認識させています。行動(Action)トークン
ロボットの目標位置や目標アーム回転量などの全行動のベクトルを Liner 層で埋め込みベクトルに変換します。この埋め込みベクトルを行動(Action)トークンといいます。行動トークンは、a_t, a_t+1, a_t+50 といった時間ステップ幅 50 個のトークンを入出力します。 これにより、高周波数(50Hz)でのロボット制御を可能にしています。
また、行動トークンは状態トークンのあとに配置することで、トークン位置の情報も持たせることができ、Transformer 内部の Positional Encoding の構造で位置情報を認識させています。
VLM 層と出力層を異なる損失関数で学習
π0モデルでは、VLM 層(事前学習済み PaliGemma)と出力層(action expert)部分で、それぞれ異なる損失関数をとって学習を行います。 これにより、1つのモデルで離散値(テキストトークン)と連続値(ロボットの行動の時系列データ)の両方を学習&出力できるようにしています
クロスエントロピー損失関数
π0 モデルの VLM 層(PaliGemma)は、従来通りクロスエントロピー損失関数で学習し、離散的なデータ(テキストトークン)を学習&出力できるようにしています。 クロスエントロピー損失関数は、VLM 層から出力される次のテキストトークンの予想値と学習用データセットに含まれる制御指示テキストの正解データの値をもとに計算され、両者の差分が小さくように VLM 層のネットワーク重みが学習されますflow matching loss
π0 モデルの出力層(action expert)部分は、Flow Matching モデルの損失関数である flow matching loss で学習し、以下のような時系列的に連続である必要のある情報を学習&出力できるようにしています。- ロボットアームの回転角
- ロボットのワールド座標(位置情報)
- グリッバーの開閉状態(true/false)
flow matching loss は、出力層(action expert)からの行動出力ベクトルと学習用データセットに含まれる行動ベクトルの正解データとの値を元に計算され、両者の差分が小さくようにモデルのネットワーク重みが学習されます
独自作成したデータセットで事後学習
上記事前学習したモデルを更に特定タスクに特化した独自作成したデータセットで事後学習して、特定タスクのスキル(物を掴んで置くなど)に特化させています。
推論フェイズ
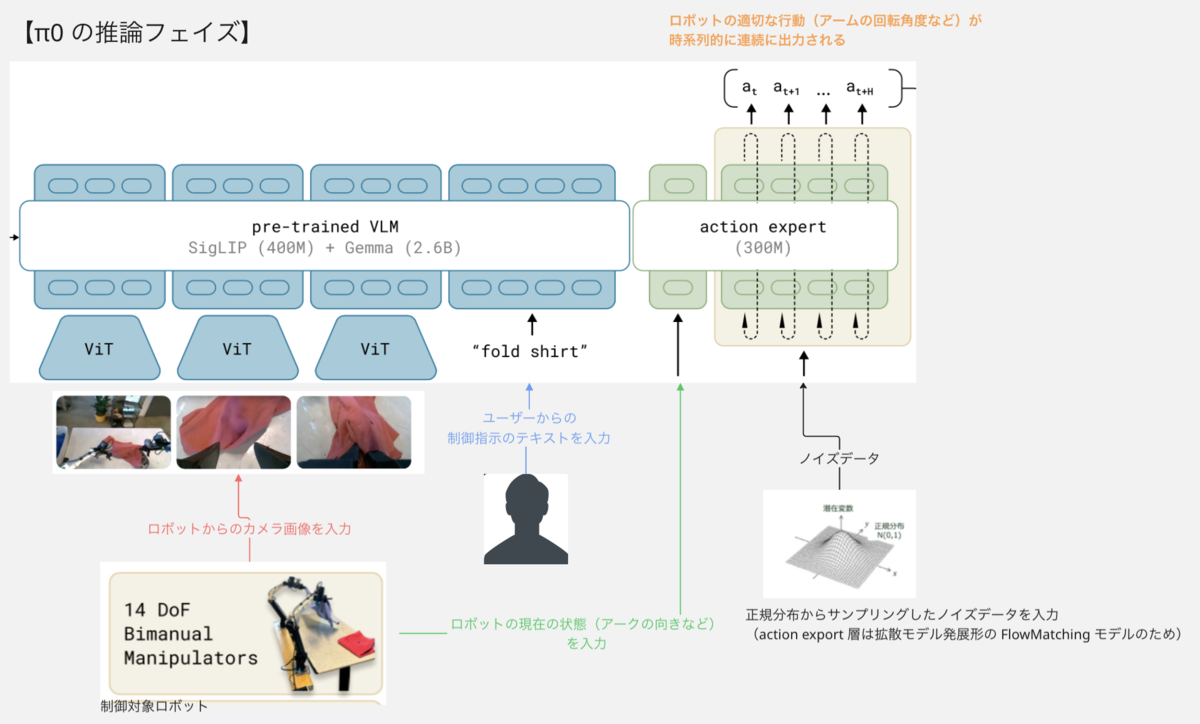
これにより公式ブログの動画にあるように、{洗濯物をたたむ・洗濯器から洗濯物を取り出す・ゴミをゴミ箱に入れる}などの多種多様なタスクをテキストで指示しながら制御できるようになっています!
実験結果
最後に、この π0 モデルの性能評価の実験結果を軽くのせておきます
事前学習モデルでの性能評価
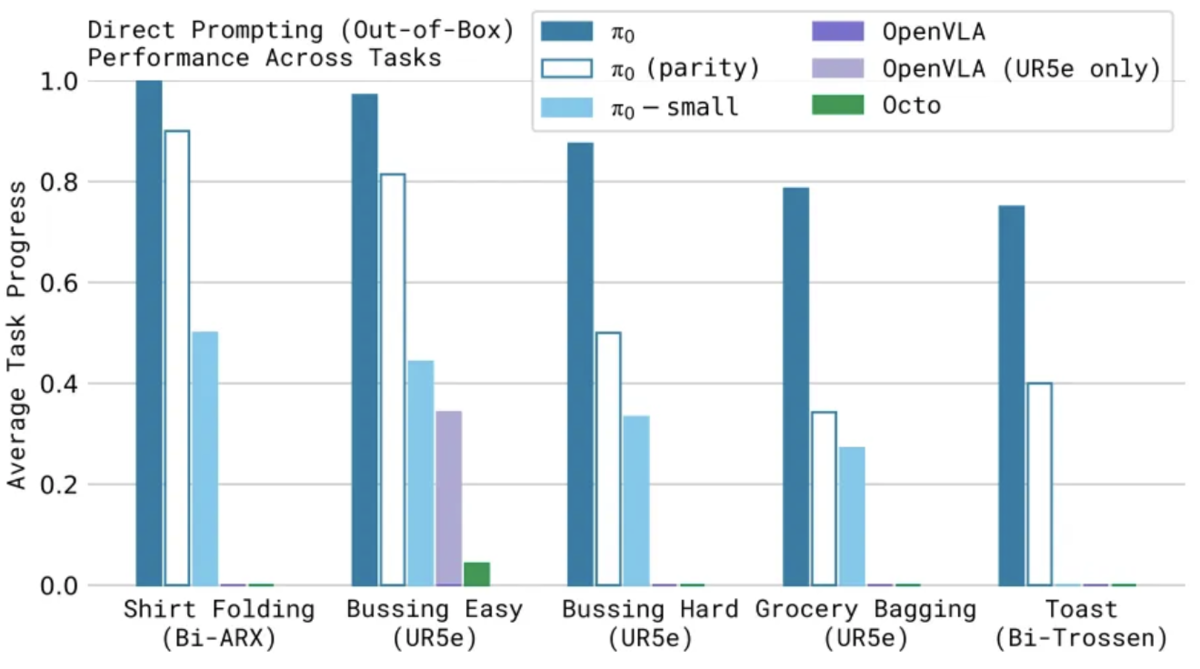
事後学習なしでの学習済みモデルを使用して、以下のような Out-of-Box というロボット制御タスクにおいて、どの程度の基本的な制御能力を獲得できているのかを他のモデルと比較し、全ての他モデルより飛躍的に高い性能を実現していることを確認 (縦軸は、ロボット制御のタスクごとに10エピソード分で平均化したスコア。エピソードが完全に成功した場合は1.0のスコアになる)
Out-of-Box の制御タスク例

論文「π0: A Vision-Language-Action Flow Model for General Robot Control」より引用 比較モデル
- OpenVLA: π0と同じくOXE [Open X-Embodiment] データセットで学習した VLA モデル
事前学習での言語能力向上の性能評価
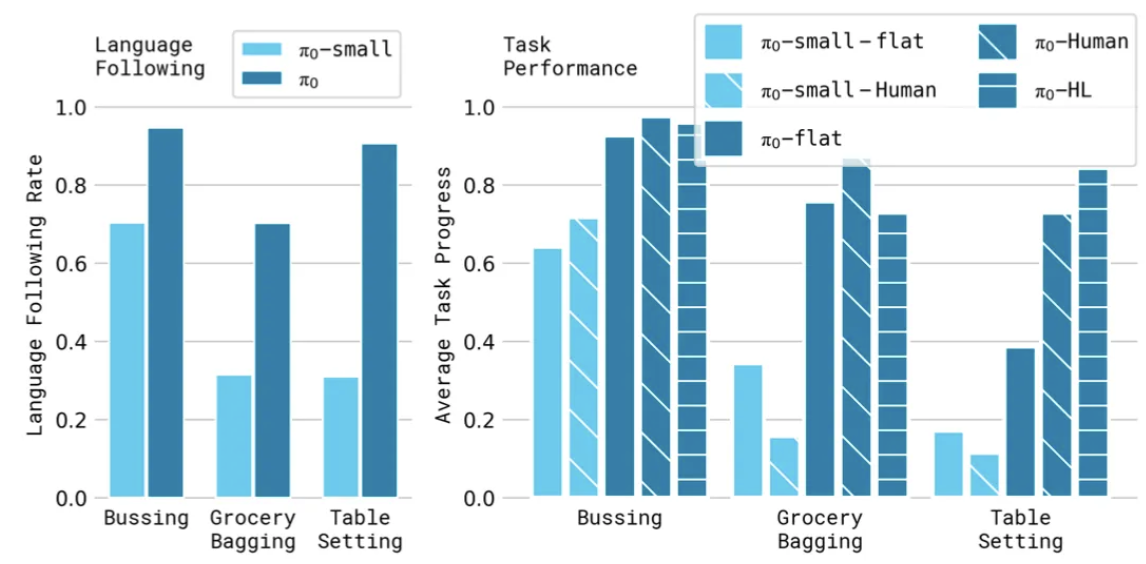
OXE [Open X-Embodiment] データセット + 独自データセットでの事前学習によって、π0モデルの言語能力がどの程度向上したのか確認
事前学習を行っていない π0-small モデルと比較して、各ロボット制御タスク(Bussing, Grocery Bagging, Table Setting)で言語理解能力が向上している(縦軸は10回の試行の平均)
- ロボット制御タスク(Bussing, Grocery Bagging, Table Setting)の画像例

論文「π0: A Vision-Language-Action Flow Model for General Robot Control」より引用
複数のタスク制御能力の性能評価
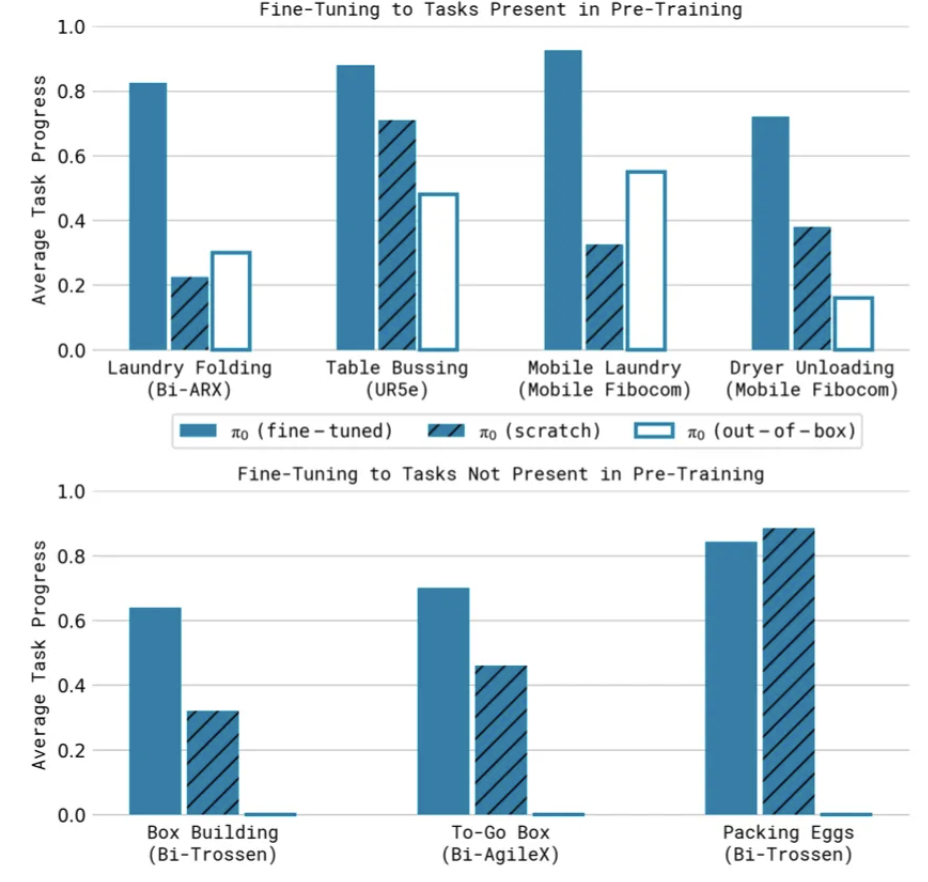
一連の複数タスクを連続して行った場合の性能の事前学習ありなし、事後学習(ファインチューニング)ありなしでそれぞれ評価 (縦軸は、全てのタスクを実行できた場合は 1.0 にして、部分的にできていた場合は 0.x になる)
事前学習 + 事後学習(ファインチューニング)を行ったモデルで最も高い性能が実現できている。
- π0(fine-tuned): 事前学習あり + 事後学習あり(ファインチューニング)
- π0(scratch): 事前学習なし
- π0(out-of-box):out-of-box タスク特化での事後学習あり
まとめ
本記事では、ロボティクス領域の VLA モデルであるπ0 を論文を元に解説しましたが、自分としてもロボティクス領域のモデルは全然知らなくて今回初めて見てみました。
論文の詳細見てみる前は、単に独自の学習用データセットを集めて出力層をロボット制御用の出力層にファインチューニングしただけかと思ってましたが、 出力層に画像生成モデルで使われる拡散モデルの系統モデルをカスタマイズしたモデルを組み込んだり、Transfomer で処理できるようにロボットの行動や状態のトークン化などしていて、相当技術高くないと開発できないモデルだなあと思いました。
モデルを改善する際には、どのような学習用データセットを作成すればいいのか?データオーギュメントの改善余地はあるのか?どのような系統の事前学習済みモデルを採用すればいいのかなど?どのような入出力層のファインチューニングすればいいのか?などいろいろ知見が得られたので良かったと思います。
あとロボティクス領域は、機械学習やソフトウェアだけで完結するような世界ではなく、機械工学、電子回路等のハードウェアや組み込みソフトウェアの世界になるので、 そもそもマイコンのCPUスペック弱くて機械学習モデル動かない。センサー等からの入力値がノイズだらけなのにフィルタリング処理が弱くチャタリングする。モーター動かすとDC-DCコンバーターが弱く電圧低下で動かせない。などなどよくありがちだと思うので、そこらへんのハードウェア技術領域を含めた総合格闘技の世界だなあと思ってます。
We Are Hiring!
株式会社ABEJAでは共に働く仲間を募集しています!
ロボティクスやLLMに興味ある方々!機械学習プロダクトに関わるフロントエンド開発バックエンド開発に興味ある方々! こちらの採用ページから是非ご応募くださいませ!
*1:π0 では、強化学習で出てくる{エピソード・行動・状態}のいう概念とともに学習を行なうので強化学習の1種類と書きましたが、正確には模倣学習は強化学習とは別ものなので訂正します。
*2:Transformer の詳細は、以下の記事を参考にしてもらえればtech-blog.abeja.asia
