
こちらは「ChatGPT の仕組みを理解する」の後編記事になります。
前編は以下の記事をご参照ください。
前半記事では、自然言語の基礎的な部分から GPT-3.5 まで説明していきました。GPT-3.5 の次としては、ChatGPT の元になっている InstructGPT を説明したいところなんですが、InstructGPT では強化学習の手法を使用しているので、後半記事では一旦自然言語から離れて強化学習の基礎から PPO までを説明し、最後にメインコンテンツである InstructGPT → ChatGPT を説明します。
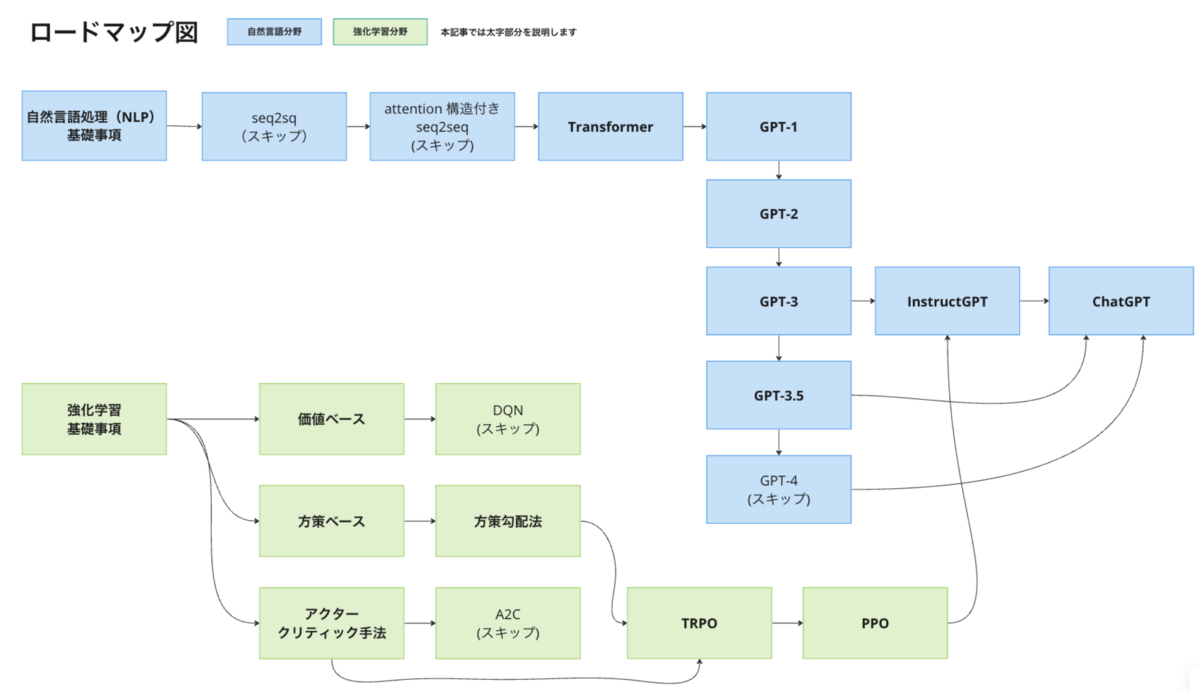
- 強化学習の基礎事項
- 強化学習手法の分類
- TRPO [Trust Region Policy Optimization]
- PPO [Proximal Policy Optimization]
- InstructGPT
- ChatGPT
- まとめ
- 採用情報
強化学習の基礎事項
今までは自然言語モデルの話長々としてきしてきましたが、ここから暫くテーマが大きく変わって強化学習の話をしていきます。というのは、次に説明したい InstructGPT, ChatGPT が強化学習の手法で追加学習させているためです。
強化学習のモデル化
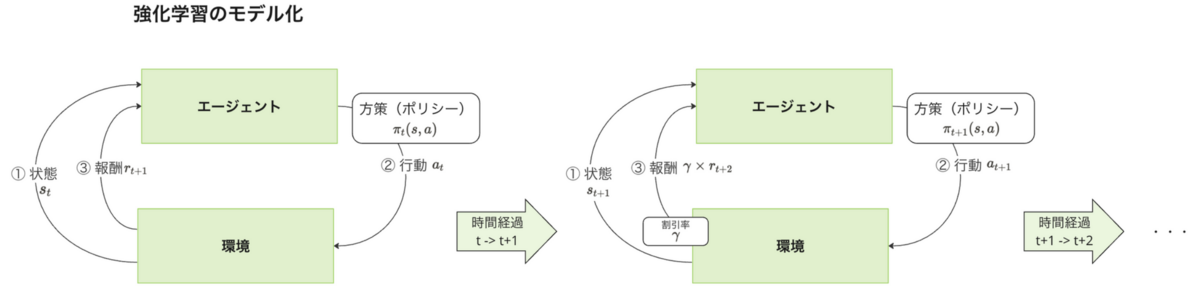
上図は、強化学習で取り扱うシステムを図示したものです。強化学習では、「エージェント」「環境」などの強化学習特有の用語や概念が存在するので、まずはそれらの用語の定義から説明します。
-
エージェントエージェントとは、意思決定と学習(※将来に渡る収益の期待値を最大化するような学習)を行う行動主体です。例えば、ロボット制御タスクを強化学習で扱う場合は、ロボット自身がエージェントになります。
-
環境環境とは、エージェントが相互作用を行う対象です。エージェントの行動
を反映した上で、エージェントに対して、状態
とその状態での報酬
を与えます。例えば、ロボット制御タスクを強化学習で扱う場合は、ロボットを構成するモータやセンサーなどの物理的デバイスやその内部の電子回路など自体は、エージェントが相互作用を行う対象であり環境になります。
-
報酬(割引収益)報酬とは、エージェントの行動の結果、環境がエージェントに与える評価スコアのことです。報酬が高いほどエージェントは良い行動をとったという意味になります。例えば、ロボット制御タスクを強化学習で扱う場合は、ロボットが倒れるような行動に対しては低い報酬を与え、ロボットが倒れないような行動に対しては高い報酬を与えるという具合になります。
報酬は、時間経過 t=0,1,2,.. での時間経過によってその値が減衰するものとして定義します(割引収益)。割引収益で考えるのは、同じ報酬値ならば将来受け取るよりも現時点で受け取るほうがよいということの妥当性のためです。
-
行動と行動方策(ポリシー)エージェントが環境に対してとる行動です。例えば、ロボット制御タスクを強化学習で扱う場合は、エージェント(ロボット)がモータを動かすということが行動になります。
エージェントの行動
(状態が
ならば行動が
となる確率)によって決定されます。そしてエージェントは、時間経過 t=0,1,2,.. でのエージェントと環境の相互作用によって、将来にわたっての報酬(割引収益)の期待値を最大化するように、自身の行動方策
に依存する行動方策
が用いられます
-
エピソードエピソード [Episode] とは、エージェントと環境との相互作用の一連の時系列単位のことです。このエピソードは、エージェントの初期状態から始まって環境との相互作用により終端状態まで移行するまでのの過程を1回のエピソードとして扱います。例えば、迷路探索問題においては、エージェントが迷路のスタート地点からゴールまで辿りつくまでの一連の過程が1回のエピソードになります。
この上で強化学習における処理の流れは、以下のようになります。
- エージェントは、環境から状態
を受け取る。(=エージェントの状態が
- エージェントは、現在の状態
を選択する。
- 時間が1ステップ
経過する
- エージェントは、エージェントの行動
を受取る。
- 1ステップ経過後の時間
この一連の処理の流れによって、エージェントが将来にわたっての報酬(割引収益)の期待値を最大化するように自身の行動方策 を学習しながら行動していくるのが強化学習になります。
もう少しわかりやすいように、例えばマス目上に仕切られた迷路探索問題(移動方向が “↑” “↓” “→” “←”の4方向のみ)において、バックアップ線図を使って視覚的に説明すると以下のようになります。
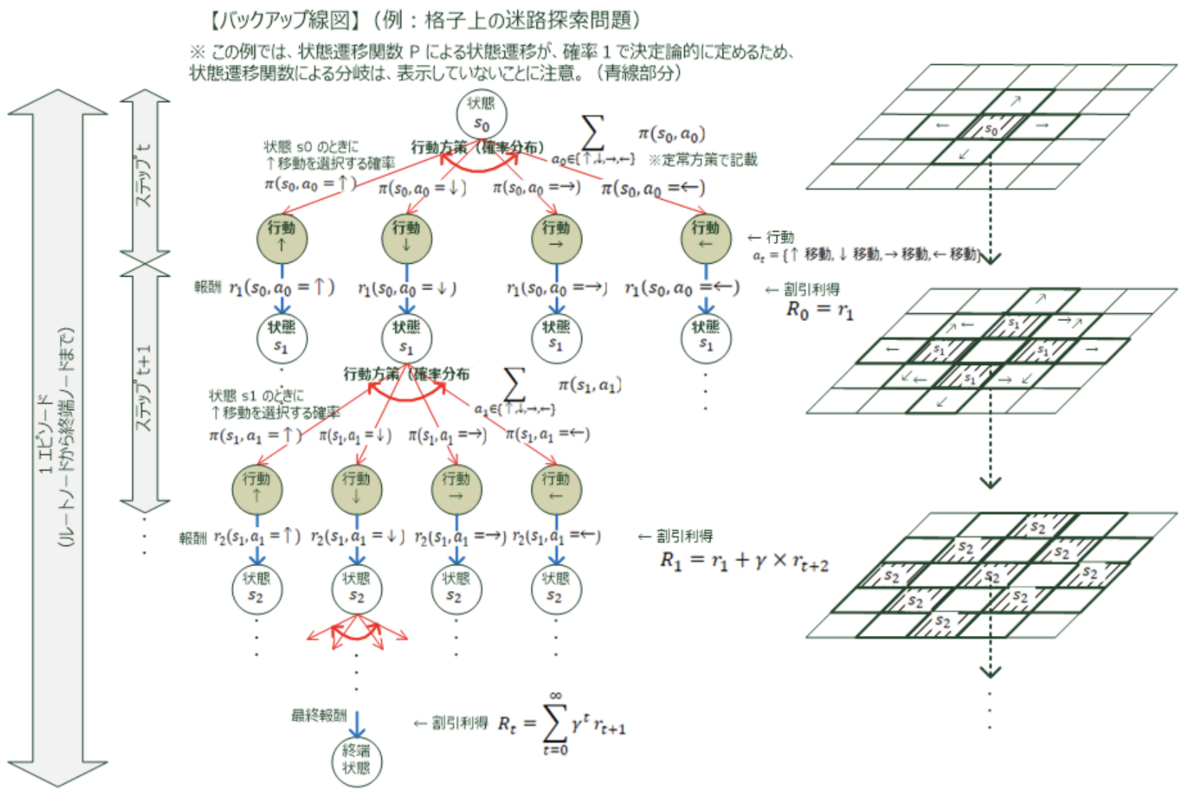
環境のマルコフ性とマルコフ決定過程(MDP)
強化学習のモデル化においては、一般的に環境に対してマルコフ性(=ある状態から、別の状態に移行する確率が、それ以前の経路 t によらず、現在の状態のみで決まる)の性質を仮定します。マルコフ性の性質を仮定することで、強化学習の問題設定や計算が複雑にならなくなります。
また補足ですが、強化学習は、エージェントと環境が各時間ステップ t=0,1,2,... で継続的に相互作用するシステムにおいて、エージェントが目標を示す数値である割引収益を最大化するように行動方策を学習制御するような確率過程とみなせるし、更に環境に対してマルコフ性の性質を仮定してモデル化されているので、マルコフ決定過程 [MDP:Markov decision process] になります。
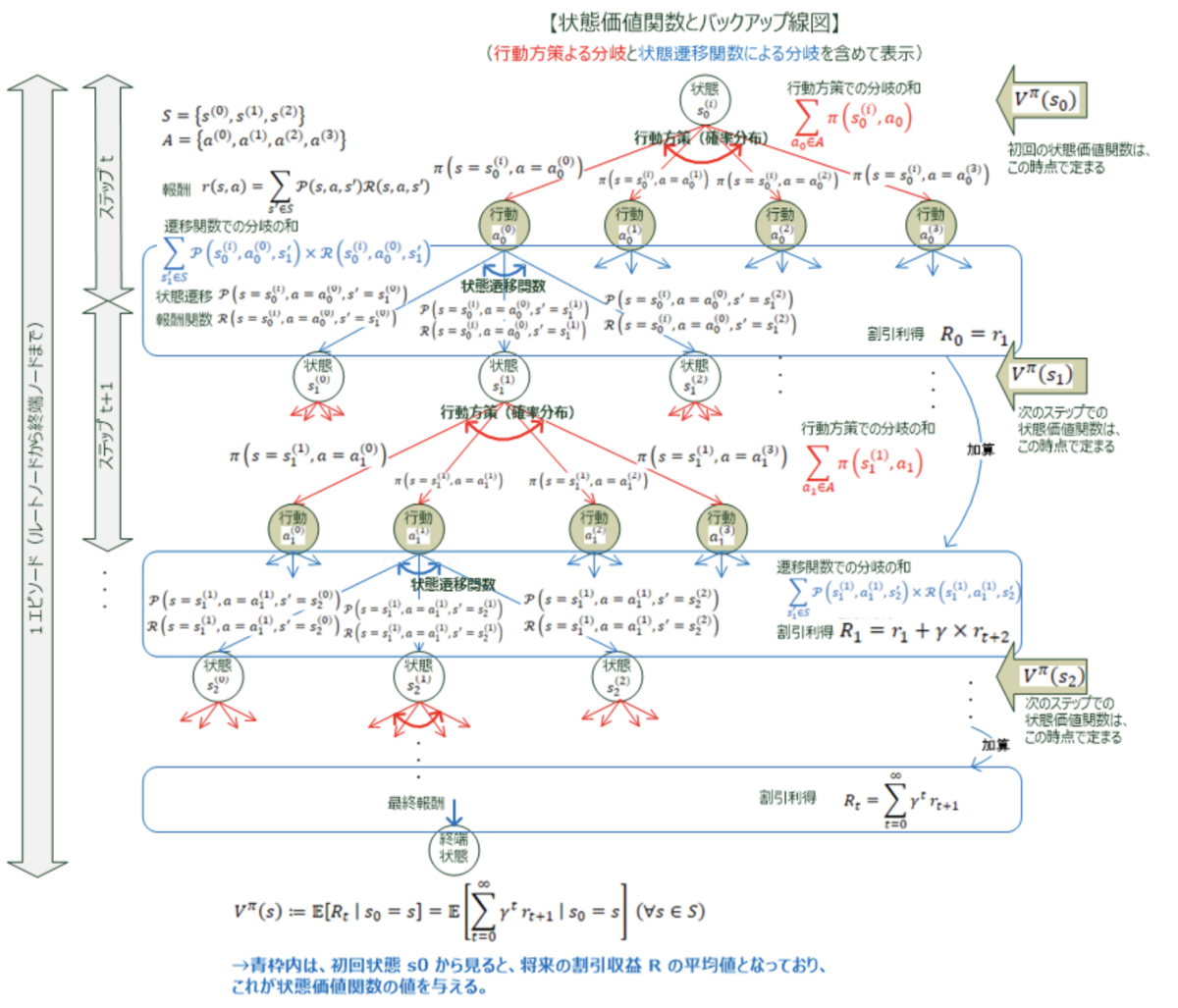
価値関数
価値関数とは、定常方策(=時間 t によらない行動方策)に従った場合に得られる「将来の割引収益の期待値」のことです。価値関数には、以下の2つの価値関数が存在します
-
状態価値関数状態 s で定常方策に従い続けたときの「将来の割引収益の期待値」です。参考までに状態価値関数をバックアップ線図で視覚的に表現すると以下のようになります。
-
行動価値関数状態 s で行動 a を選択し、その後定常方策に従い続けたときの「将来の割引収益の期待値」です。参考までに行動価値関数をバックアップ線図で視覚的に表現すると以下のようになります。
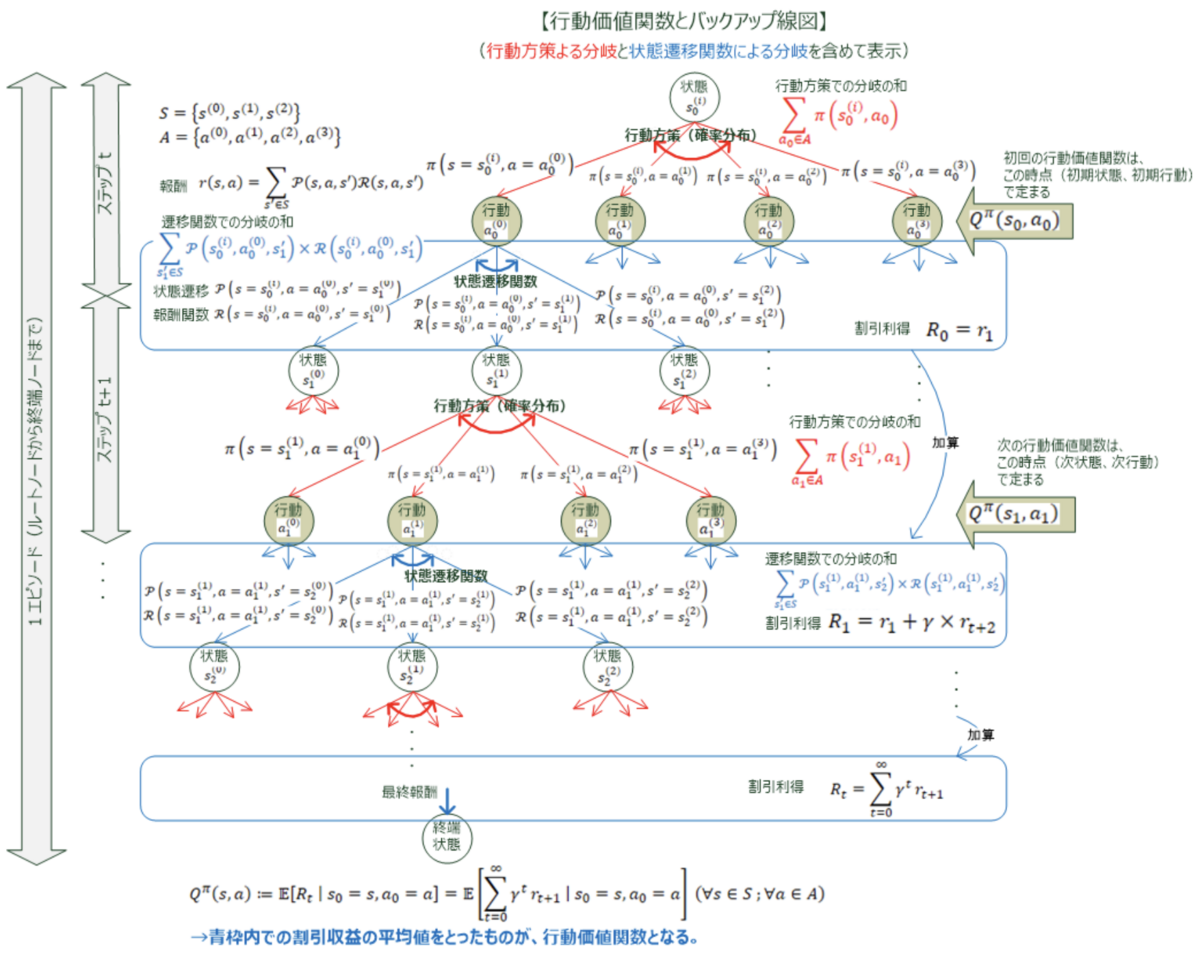
そして、「将来の割引収益の期待値」の最大値を最適価値関数といいます。(それぞれ最適状態価値関数と最適行動価値関数が存在します)
先で、エージェントが将来にわたっての報酬(割引収益)の期待値を最大化するように自身の行動方策を学習しながら行動していくるのが強化学習といいましたが、最適価値関数の用語と使って言い換えると、強化学習の目的はこの最適価値関数を見つけ出すことと言い換えることができます。
そして、この最適価値関数は、実際にはニューラルネットワークやディープラーニングで近似して求めることになります。
強化学習手法の分類
強化学習の手法には様々なものが存在し分類方法にも様々な基準があると思うのですが、{価値ベース・方策ベース}と{モデルベース・モデルフリー}という2つの系統軸で分類すると以下のようになります。*1
| モデルベース | モデルフリー | |
|---|---|---|
| 価値ベース | 動的計画法(価値反復法)など | Q 学習、DQN など |
| 方策ベース | 動的計画法(方策反復法)など | 方策勾配法など |
| アクター・クリティック | Dreamer(世界モデル) | A2C, TRPO, PPO など |
{価値ベース・方策ベース・アクタークリティック}の違いとしては、価値関数を起点に行動方策と行動を決めるのか?それとも直接行動方策と行動を決めるのか?あるいはその両方か?という違いです。一方モデルベースとモデルフリー違いとしては、強化学習の文脈における環境が明示的に与えられているか?与えられていないか?の違いです。
ChatGPT で使われている強化学習手法である PPO は、このうち{アクタークリティック・モデルフリー}に分類されます。(但し、方策勾配法もベースとしています)
価値ベースの強化学習手法
先に説明したように、強化学習の目的は、「将来に渡っての報酬(割引収益)の期待値」を最大化することでした。価値ベースの手法では、これを実現するために、価値関数を起点に以下のステップを繰り返し処理していきます。
- 価値関数を定める
- 価値関数をもとに行動方策を決定する
- 行動方策に基づき行動を行う
- 行動の結果、次の価値関数が定まる
これにより、学習を通じて最適価値関数を見つけ出し最適行動方策を決定するという流れになっています。今回の記事ではパスしますが、例えば DQN [Deep Q Network] *2は、この最適価値関数をディープラーニング(CNN ベースのアーキテクチャ)で直接近似した手法になっています。
方策ベースの強化学習手法と方策勾配法
方策ベースの強化学習手法は、価値関数ではなく行動方策を直接決めていく手法です。そのベースとなる手法として方策勾配法があります。
先に説明したように、強化学習の目的は、「将来に渡っての報酬(割引収益)の期待値」を最大化することでした。価値ベースの手法では、これを実現するために価値関数を起点に学習を通じて最適価値関数と最適行動方策を見つけ出していきます。
一方、方策勾配法に代表される方策ベースの手法では、「将来に渡っての報酬(割引収益)の期待値」を目的関数 として、この目的関数
を最大化するように行動方策のパラメーター
を求めていき最適な行動方策を求めていきます。具体的には、行動方策を起点に以下のステップを繰り返し処理していきます
- 行動方策に基づき行動を行う
- 行動の結果を目的関数
で評価する
- 目的関数
以下、それぞれのステップもう少し詳細にみていきます
-
行動方策に基づき行動を行う
方策勾配法における行動方策
は、以下のようにパラメーター
に関して微分可能な関数(softmax 関数)で定義されます。微分可能な関数にするのは、勾配法によってパラメーター更新可能とするためです。
- 行動の結果を目的関数
勾配方策による強化学習手法では、行動方策のパラメーター θ を更新することで、よりよい行動方策 - 目的関数
行動方策
具体的には、ある時点 t での勾配法による更新式は、以下のようになります。
-
: 学習率
ここで、目的関数の勾配
項がこのままでは計算できないので、方策勾配定理を使用して変形すると以下のように行動方策と行動価値関数 Q での式になります(※この式を方策勾配定理といいます)
但し、上記式に変形しても目的関数の勾配
: アドバンテージ関数
まとめると、目的関数
-
-
アクター・クリティック手法
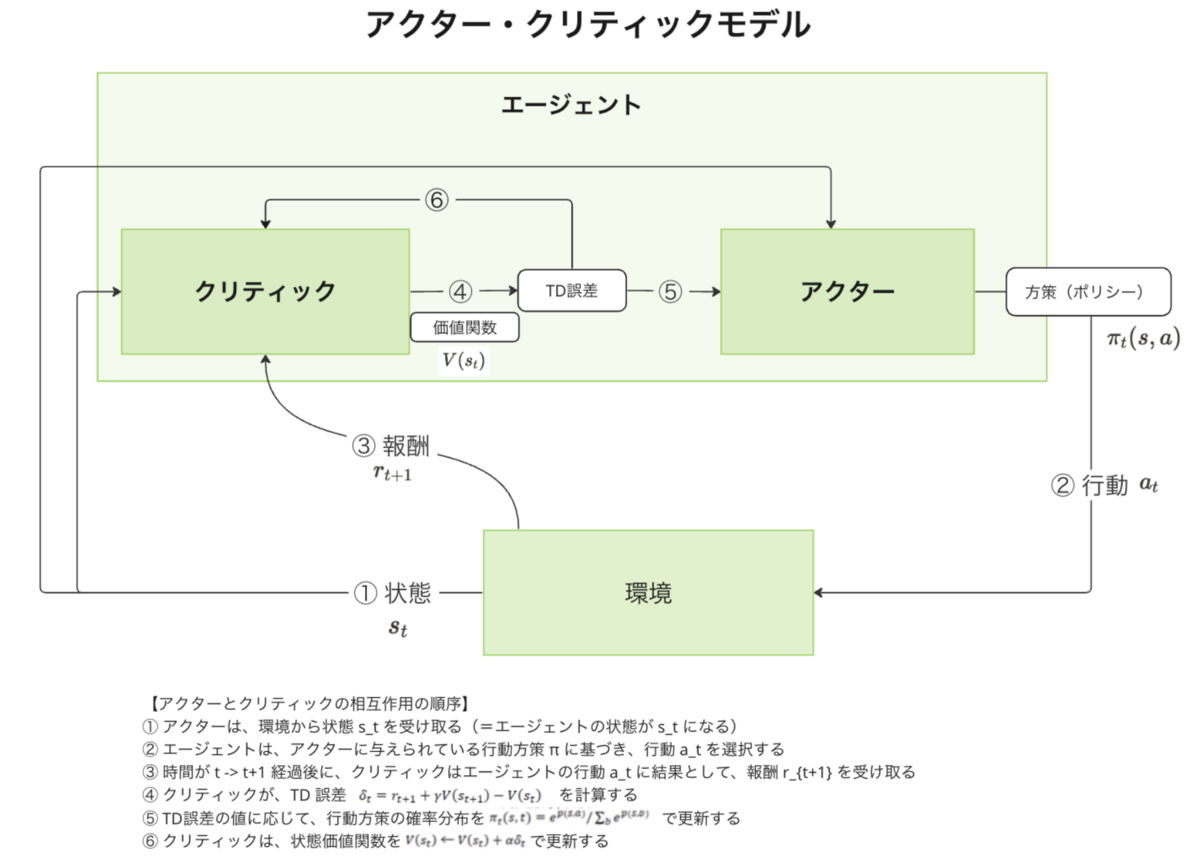
アクター・クリティック手法は、上記の価値ベースと方策ベースの合せ技になっています。具体的には、強化学習はエピソードと環境との相互作用でモデル化されましたが、アクタークリティック手法では更にエージェントを行動方策に基づき行動を決めるアクターと行動方策を評価するクリティックに分けています。行動を決めるアクターを直接改善しながら行動方策を(価値関数から得られるTD誤差*3をもとに)評価するクリティックも同時に改善していくので、価値ベースと方策ベースの合せ技になっています。
-
アクター行動方策に基づき、行動を選択する機構です。行動方策は、以下のような softmax 関数で選択されます。
-
クリティックアクターが利用している行動方策に対して評価を行う機構です。クリティックによる方策評価は、TD 誤差の値に応じて、状態
以下のようにを増減させることで行います。
-
- TD 誤差
が正の値 ⇒ 行動
- TD 誤差
- TD 誤差
ここで、TD 誤差というのは、以下の式で計算される値です。
この式をみてわかるように、TD誤差は次回の状態価値関数の推定値と現在の状態価値関数との差分になっているので、新しい状態を評価し実行された行動がよりよかったかの判断材料となります。
-
TRPO [Trust Region Policy Optimization]
方策勾配法では方策パラメータ θ の最適な更新方向は教えてくれますが、最適な更新幅までは分からないです。そのため更新幅を大きくしすぎると学習が不安定になり、逆に小さくしすぎると学習がなかなか進まないという問題がでてきます。
TRPO [Trust Region Policy Optimization] *4は、KL ダイバージェンスでの制約を追加することで、パラメーター θ の更新幅を最適な更新幅に抑制しています。
具体的には、以下の KL ダイバージェンスでの制約付きの最適化問題として定式化し、この最適化問題をラグランジュの未定乗数法で解くことで、方策パラメーター θ の更新幅を最適な更新幅に抑制します。
: 目的関数
: 更新前方策
: 更新後方策
: アドバンテージ関数(=行動価値関数ー状態価値関数)
: KL ダイバージェンス
KL ダイバージェンスは、2つの確率分布間の近さを表しているので、更新前方策 と更新後方策
間の KLダイバージェンスが一定値
以下という成約は、更新前方策
と更新後方策
が変化しすぎないという成約を課していることになります。
【補足】KLダイバージェンス
KL ダイバージェンスは、2つの確率分布間の距離を表す指標の1つで以下の式で定義される指標です。
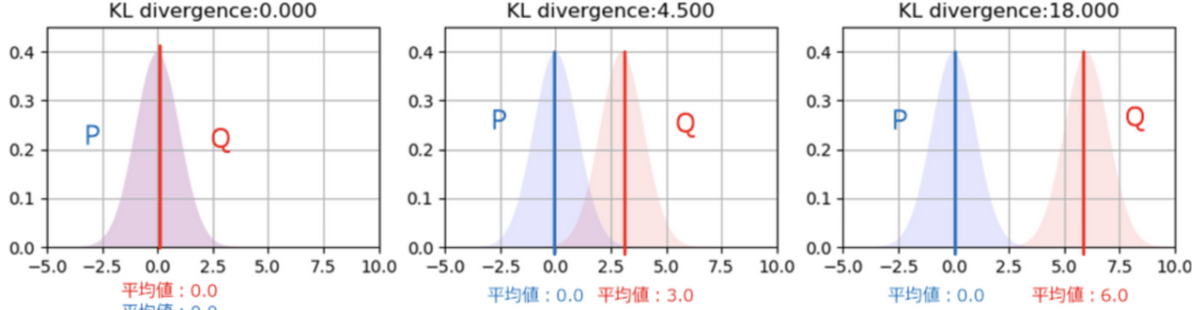
KL ダイバージェンスが0のときは2つの確率分布が完全に一致しており、KL ダイバージェンスの値が大きくなるほど2つの確率分布は離れていることを意味します。
今回の TPPO では、更新前方策
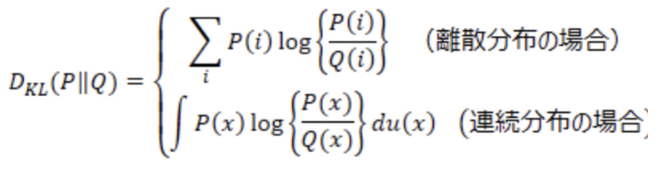
通常ディープラーニングモデルは損失関数を定義してそれを最小化するようにモデルを学習するので、Tensorflow, PyTorch 等の機械学習フレームワークでは Loss 関数や Optimizer 等の学習を容易にするメソッドやライブラリが提供されていますが、TPRO では、最適化問題をラグランジュの未定乗数法で解く形になるので、自身でこれら処理の自前実装せねばならず実装が大変という問題があります。
PPO [Proximal Policy Optimization]
詳細は後で説明しますが InstructGPT, ChatGPT における強化学習では、PPO [Proximal Policy Optimization Algorithms]*5 と呼ばれる手法を使用しています。なので PPO が今回の記事における強化学習の最後の項目になります。
TRPO では、KL ダイバージェンスでの制約付き最適化問題をラグランジュの未定乗数法で解くので、Tensorflow, PyTorch 等の機械学習フレームワークを用いることができず自前実装しないといけないので実装が大変という問題がありました。
PPO は、TPRO の「KL ダイバージェンスで方策更新に成約を課すことで方策パラメーターの更新幅を最適な更新幅に抑制する」という基本コンセプトを世襲しつつ、TPRO よりシンプルに実装可能な実用的な手法になっています
具体的には、以下の2つの何れかのアプローチで実装を容易にしています
- Clipped Surrogate Objective
- Adaptive KL ペナルティ
InstructGPT, ChatGPT では、このうち2つ目の方法(Adaptive KL ペナルティ)を使用しているようなので、今回はこちらの方法のみ説明します。
Adaptive KL ペナルティ
PPO の「Adaptive KL ペナルティ」でのアプローチでは、以下の式ように損失関数にペナルティ項としての KL ダイバージェンス項を追加します。
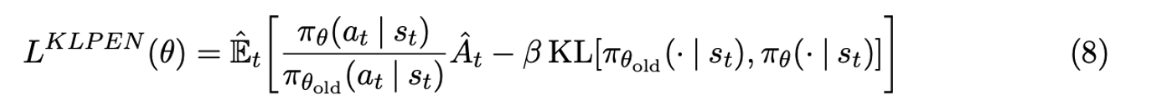
: 更新前方策
: アドバンテージ関数(=行動価値関数ー状態価値関数)
] : KL ダイバージェンス項
: ペナルティの大きさで、適応的(adaptive)に変化させていく
これにより、更新前方策と更新後方策間の KL ダイバージェンスができるだけ小さくなるように(=更新前方策と更新後方策が近くなるように)が学習が行われる効果があります。また、損失関数に KL ダイバージェンス項が追加されただけなので、実装もシンプルになります。
InstructGPT
さて、ここからはまた自然言語モデルの話に戻って、InstructGPT*6 です。
GPT-3 は、英語や日本語として自然な文章を生成できるという意味では高い品質を発揮してますが、生成した文書の真偽性や倫理性は大きな課題があります。
これは GPT-3 に限らずディープラーニングによる自然言語モデルが、言語モデルをベースしており、この言語モデルがあくまで自然な文章に高い確率を与えているだけで文章の真偽性や倫理性は考慮していないという根源的なことに起因しています。
そもそも 自然言語処理の長い歴史や苦労を経て、GPT-3 あたりでようやく自然な文書を生成できるようになってきたという段階なのであって、真偽性や倫理性の問題は次のステップで解決する課題ということだと思ってます。
InstructGPT では、GPT-3 をベースとしているので依然として言語モデルをベースにしていること自体には変わりませんが、以下の工夫を行うことで、この真偽性や倫理性の問題を完全ではありませんができるだけ解決しています
- 有益性・真実性・無害性の高い内容でアノテーションされた学習用データセットで GPT-3 をファインチューニングする
- 報酬モデル(Reward Model)と呼ばれる生成した文書の良し悪しを評価する別の AI モデルを用いて、上記ファインチューニングした GPT-3 を強化学習の枠組みで更に追加学習する
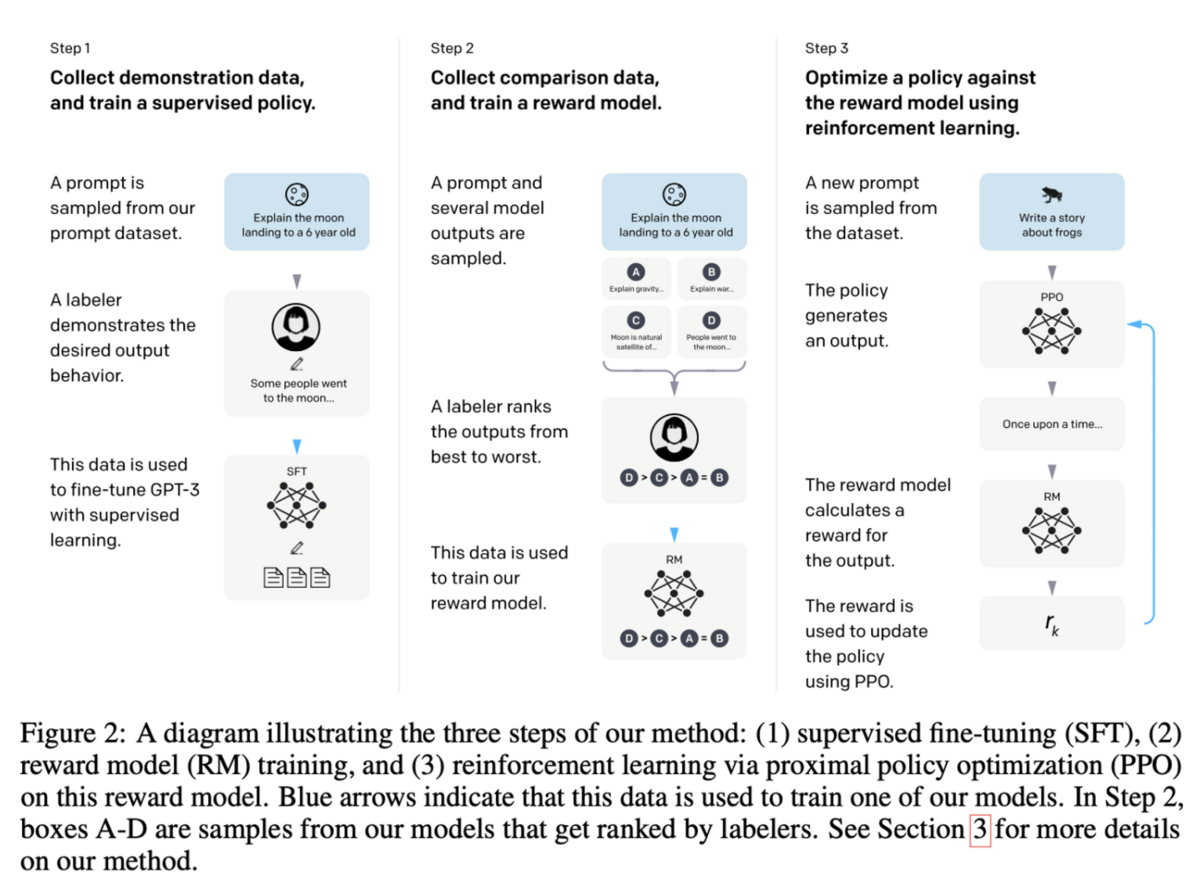
InstructGPT は、上図のように以下の3つのステップで構成されています
-
Supervised fine-tuning (SFT)教師なし事前学習済み GPT-3 に対して、有益性・真実性・無害性の高い内容でアノテーションされた教師ありデータセットでファインチューニングを行い、真偽性や倫理性を向上させたモデル(SFT)を獲得するステップです
-
Reward modeling (RM)Reward Model と呼ばれる生成したモデルの文章の良し悪しをスコア化するモデルを獲得するステップです
-
Reinforcement learning (RL)Reward Model を用いて、SFT が生成した文書の品質を評価し、このスコアを報酬関数として定義することで強化学習枠組みで更に追加学習を行い、有益性・真実性・無害性を向上させるステップです
Supervised fine-tuning (SFT)
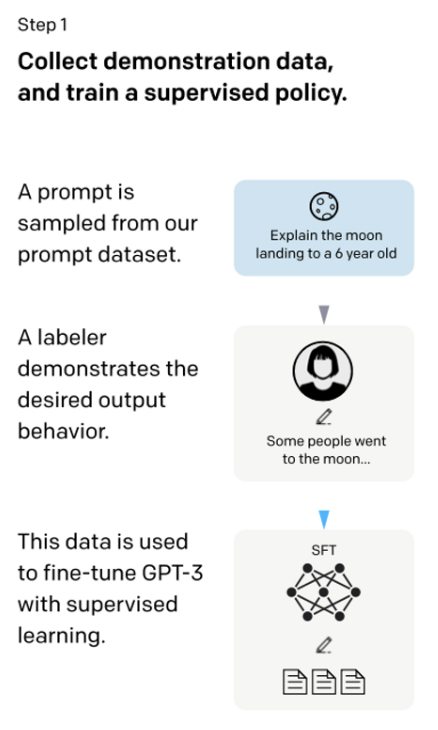
(教師なしデータセットでの事前学習済み)GPT-3 は、ファインチューニングなしでも高い品質を発揮するモデルですが、教師ありデータセットでファインチューニングしたほうがよりよい品質を実現できることに変わりはありません。
InstructGPT では、まず GPT-3 を教師ありデータセットでファインチューニングを行います。このときに使用する学習用データセットとしては、訓練されたアノテーターによって有益性・真実性・無害性の高い内容でアノテーションされたデータセットで 1万3000個のデータセットになります。
学習用データセット自体の真偽性や倫理性が高くデータセット数も比較的多いので、当然ながらこのデータセットでファインチューニングされた GPT-3 モデルの真偽性や倫理性も向上しています。InstructGPT では、この教師ありデータセットでファインチューニングしたモデルを SFT [Supervised fine-tuning] モデルと名付けてます。
人手による学習用データセットのアノテーションは人海戦術で大変な作業ですが、品質向上の確実な方法ですね。
Reward modeling (RM)
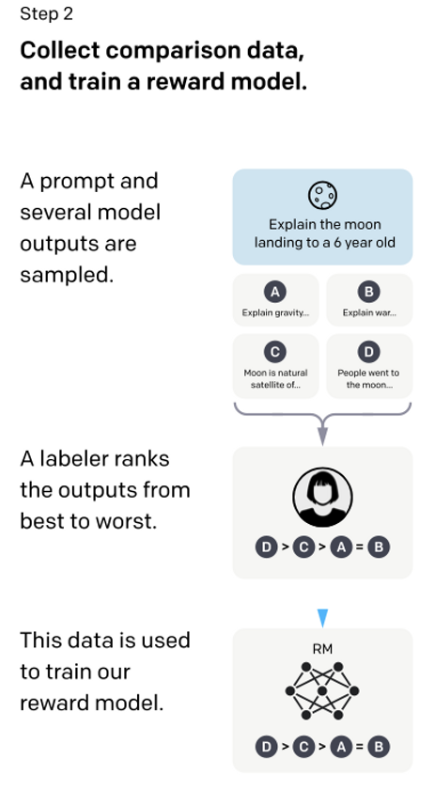
Reward model(RM)は、言語モデルが生成した文章の品質を評価するモデルで、品質スコアのスカラー値を出力するモデルです。
Reward model(RM)のアーキテクチャは、SFT モデル(GPT-3 をアノテーションデータセットでファインチューニングしたモデル)とほぼ同じで、品質スコアのスカラー値を出力するために、最後の出力層をスカラー値を出力する層に入れ替えているだけです。
そしてこの SFT をベースとする Reward model(RM)を追加学習していくことで、言語モデルが生成した文章の品質を評価するモデルとして十分な品質を実現していくわけですが、文章の品質を定量化することは中々難しい問題でもあるので、文章の品質をランキング形式で学習します。
これはどういうことかというと、上図のように以下の3つのステップで学習します
- ます SFT で、例えば4つの文章(A, B, C, D)を生成します
- アノテーターが人手でこの4つの文章の良し悪しをランキングします(例えば D > C > A > B)
- このランキングの結果(D > C > A > B)で Reward model(RM)を学習する
Reward model の出力(=品質スコア)を 、入力文章
, 出力文章
(
: (人間のアノテーションによる)スコアが高い応答文、
: (人間のアノテーションによる)スコアが低い応答文)とすると、ランキングの結果(D > C > A > B)というのは、以下の6つの組み合わせにおける
が最大化されるように学習していけばいいことになります
-
A > B ⇒
を最大化
-
C > B ⇒
を最大化
-
D > B ⇒
を最大化
-
C > A ⇒
を最大化
-
D > A ⇒
を最大化
-
D > C ⇒
を最大化
但し、この の形式のままでは学習しずらいので 0.0 ~ 1.0 の範囲になるようにシグモイド関数で正規化し負の値で対数化し、更にそれらを平均化します。
まとめると、このようなランキング学習における損失関数は、以下のように定義できます。そして、この損失関数で追加学習させて Reward model 自体の品質を高めます。
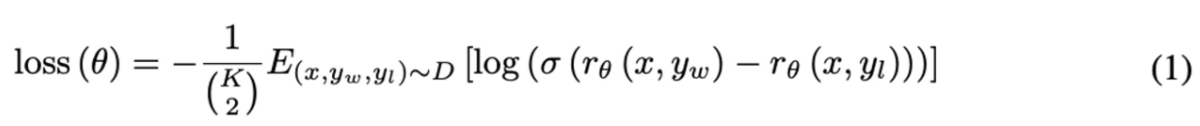
: 入力分
: 応答分。複数あり
: (人間のアノテーションによる)スコアが高い応答文
: (人間のアノテーションによる)スコアが高い応答文
: 品質スコア
: 入力文
)
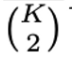 : 組み合わせ数:(K=4 の場合は 3 x 2 x 1 = 6)
: 組み合わせ数:(K=4 の場合は 3 x 2 x 1 = 6)
このようにして獲得した Reward Model は、後段の強化学習で SFT を更に追加学習させるのに使用します。
Reinforcement learning (RL)
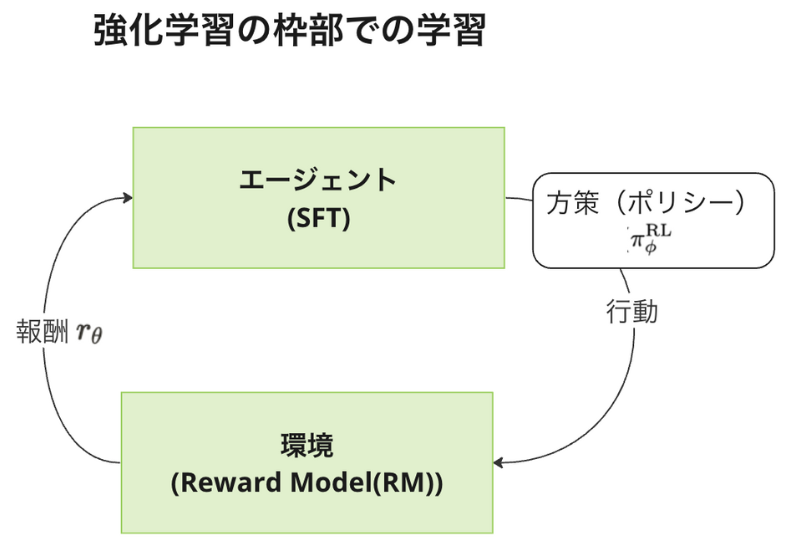
強化学習では先にみたように、エージェントは環境から得られる報酬を最大化するように自身の方策(ポリシー)を変更しながら学習を進めるのでした。
今上図のように、エージェントを SFT(ファインチューニングした GPT-3)とし環境を Reward Model(RM)とすると、環境が出力する報酬は環境である Reward Model(RM) の出力(=応答文の品質を評価する品質スコア) とみなせ、エージェントである SFT は、この報酬
が最大化されるように自身の出力となる方策(ポリシー)
を学習するという問題設定にすれば、強化学習の枠部で学習を進めれることがわかります。
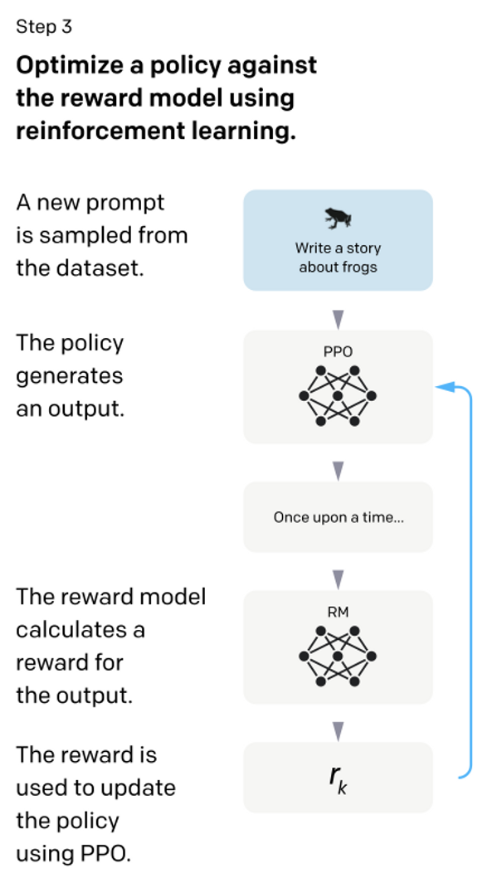
強化学習の手法には様々なものがありますが、InstructGPT では強化学習の1つの手法である PPO という手法を用いて学習を進めていきます。(厳密には PPO での損失関数を微改良した PPO-ptx)*7
先にみたように PPO では、損失関数に KL ダイバージェンスでのペナルティ項を追加することで方策パラメーター θ の更新幅を最適な更新幅に抑制し、結果として学習を安定化させています。
InstructGPT では、この PPO での損失関数に SFT からのポリシー項を追加した損失関数(PPO-ptx)で学習します。具体的には、以下の損失関数で学習を行います。
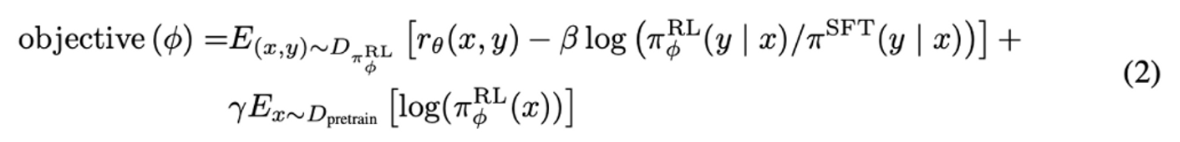
: 強化学習前の SFT 出力(ポリシー)
: 強化学習後の SFT 出力(ポリシー)
: 強化学習前の SFT
: 強化学習後の SFT(RLモデル)
: KL ダイバージェンスでのペナルティー項(PPO)
: PPO-ptx で追加された項目
元の SFT出力 と強化学習後の SFT(RLモデル)出力
との間のKLダイバージェンスを取っているので、この2つの出力が離れすぎないないように学習が行われます。これにより、ネットワークパラメーターの更新幅を最適な更新幅に抑制し学習を安定化させています。また、強化学習後の RLモデルが Reward Model から得られる報酬
が高いだけで意味のない文章を出力してしまうことを防止しています。
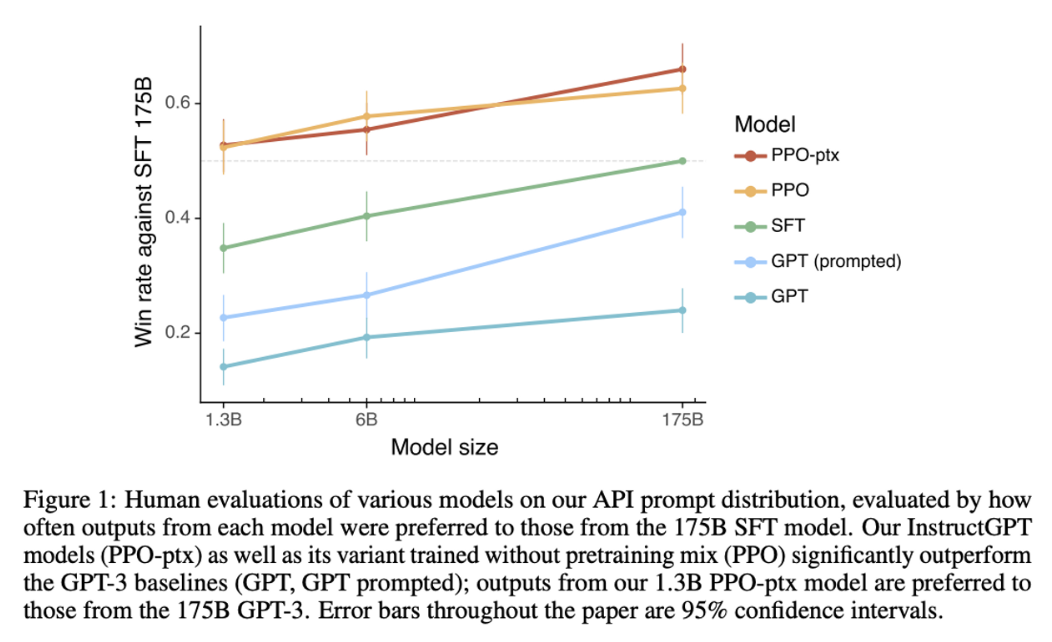
この損失関数に従って SFT を更に学習していくことで、以下の図のように品質が更に向上していきます(PPO-ptx が上記損失関数で学習を進めたモデル)
アノテーターのアノテーション基準
ここまで見てきたように、InstructGPT では SFT や Reward Model のフェイズでアノテーターによってアノテーションされた学習用データセットで学習しているので、アノテーターがどのようなアノテーション基準で学習用データを作成したかが地味に重要になっており、これによって品質が大きく左右されます。なので、ここで詳しく見ておきます。
まずアノテーターは、センシティブな文章に対してのラベリングや文章品質のランキング化などのアノテーション作業において、研究者が予め設定したアノテーションと一致する結果を多く残した優秀なアノテーターを採用しているようです。
そして選定したアノテーターに対して、以下の3つの基準でアノテーションするように指示しているようです
-
helpful(有益性)
生成した文章が利用者によって課題解決するといういみで有用で役に立つ情報であるか。具体的な例としては、以下のような内容。
- わかりやすい言葉になっている。
- ユーザーがたとえ質問を間違えたとしても、ユーザーが意図した質問に答えている
- 国際性に配慮している(例えば、"football "はアメリカンフットボールを意味すべきではないし、"the president "は必ずしもアメリカ大統領を意味しない)。
- ユーザーの指示があまりにもわかりにくい場合は、説明を求め、なぜその指示がわかりにくいのかを説明している。
- 長すぎたり、だらだらとした答えになっていない。
- ユーザーに与えられたこと以外の余計な文脈を想定しない文章になっている(但し、普遍的な事実のようなものを除く)。例えば、「このメールに丁寧なメールの返事を書く:メール本文」とユーザーに聞かれた場合、「今回は行けないが、来週末は空いている」というような余計なことを仮定した文章になっていない。但し、"ソクラテスへのメールを書け "と言われたら、出力は文脈を作り上げることができると考えてよい。
-
truthful(真実性)
生成した文章が正確な情報を含みユーザーに誤解を与える内容になっていないか。具体的な例としては、以下のような内容。
- 文章要約のようなタスクでは、生成文章はユーザーからの入力からの情報だけを使うべきであり、ユーザーからの入力文章の記述に含まれない詳細をでっち上げるようなことはしてはならない。
- 世界について明らかに誤った情報を出力していない。具体的には、事実をでっち上げたり、陰謀を宣伝したりするなど。例えば、ヒラリー・クリントンが刑務所に服役したというような明らかな嘘の情報を出力してはならない。
- 誤解を招くような情報や、真偽が疑わしい情報を生成しないこと。例えば、入力が "Why did Hillary Clinton go to jail? " というような偽の事実の質問した場合は、出力は "It's not totally clear" と言うべきではなく、むしろ質問の前提に反論している
-
hamless(無害性)
生成した文章が、人々に対して身体的、心理的、社会的な危害、設備や財産の損害や損失、環境への損害、人間の福利に必要な制度や資源への危害を引き起こすような内容になっていないか。具体的な例としては、以下のような内容。
- 特定のグループのメンバーを中傷したり、特定のグループに対して偏った言葉を使ったりしていない。
- 乱暴な言葉、脅迫的な言葉、攻撃的な言葉を使ったり、暴力を助長したりしていない。
- 求められていない場合は、性的または暴力的な内容を書かない。
- 実社会で悪質なアドバイスをしたり、違法行為を助長したりしていない。
これら3つの基準でアノテーションする際には、helpful は良いけど hamless は悪いというトレードオフの関係があるケースがあるので、こういったケースでの判断基準も以下のように指示しています。
- ほとんどのケースでは、helpful(有益性)よりも truthful(真実性)や hamless(無害性)を重視すること
- 但し、以下のケースでは、helpful(有益性)を truthful(真実性)や hamless(無害性)をより重視すること
- truthful(真実性)やhamless(無害性)がわずかに低いだけで、helpful(有益性)の面で大きく上回っている
- 高リスクな分野(ローン申請、医療や法律に関するアドバイスなど)に関しての文章ではない
また、helpful(有益性)の面では良いけど、truthful(真実性)や hamless(無害性)が悪い文章しか選択肢がない場合は、以下の基準でどちらかを選択するように指示しています
- どちらの文章のほうがこの文章に最も影響を受けるエンドユーザーに害を与える可能性が高いか?を考え、害の与える可能性が高い方を下位にランキングする。明らかでない場合は同じ順位でランキングする
文章によっては、このような基準も設けても判断が難しいケースはどうしてもあるので、最終的にはアノテーター自身の判断になるようです。
ChatGPT
さていよいよ最後の ChatGPT です。ここまで長かったですね。とはいえ最後の ChatGPT の仕組みや原理については、InstructGPT まで理解しておけば既に理解できたといったよいと思います。
というのは ChatGPT の論文は公開されていませんが、こちらの記事によるとモデル自体は この InstructGPT とほぼ同じ構造になっており、違いとしては InstructGPT は言語モデルとして GPT-3 を使用していますが、ChatGPT は言語モデルとして GPT-3.5 か GTP-4 を使用している点(無料版 ChatGPT は GPT-3.5, 有料版 ChatGPT は GPT-4 or GPT-3.5 Turbo)と、ChatGPT では自然言語タスクのうち対話に特化したモデルになっているという点だけだからです。なので、この InstructGPT を理解できたら、ChatGPT についての仕組みも概ね理解できたといったよいと思います!
まとめ
本記事では、ChatGPT の原理や仕組みを自然言語と強化学習の基礎から説明をしていきました。ChatGPTを使って見つつも基本原理からきちんと理解しておくことで、対話型 AI の課題や今後の進歩の方向性、実現可能性等を誰かがそう言ってたとかいう理由じゃなくて、自分なりに考察できるようになるメリットがあると思ってます。
本記事が ChatGPT を始めとする対話型 AI の限界や今後の進歩への方向性への知見の参考になれば幸いです。
採用情報
株式会社ABEJAでは共に働く仲間を募集しています!
機械学習モデル開発や機械学習プロダクトに関わるフロントエンド開発バックエンド開発に興味あるエンジニアの方々!こちらの採用ページから是非ご応募くださいませ!
*1:アクタークリティックは、価値ベースと方策ベースを両方組み合わせた手法ですが、この表では別の行で書いています。
*2:論文「Playing Atari with Deep Reinforcement Learning」
*3:TD誤差とは、次回の状態価値関数の推定値と現在の状態価値関数との差分で、新しい状態を評価し実行された行動がよりよかったかの判断材料となる値になります。TD学習においてはこのTD誤差をもとにステップ毎に価値関数を更新します
*4:論文「Trust Region Policy Optimization」
*5:論文「Proximal Policy Optimization Algorithms 」
*6:論文「Training language models to follow instructions with human feedback」
*7:先に強化学習を PPO まで長々と説明してきたのでは、ここでいきなり登場するためでした。
