
こんにちは!株式会社 ABEJA で ABEJA Platform 開発を行っている坂井(GitHub : @Yagami360)です。LangChain 使えば、RAG [Retrieval Augment Generation] などを活用した LLM アプリケーションも簡単に作成できるので大変便利ですよね。そんな LangChain を開発している LangChain 社から LLMOps ツール(*1)である LangSmith が登場しているので調査してみました。昨今 ChatGPT 等の LLM 技術の発展に伴い、LLM を実際のアプリケーション開発や運用に適用する際に MLOps から派生した LLMOps という概念が有益になってきています。LangSmith はそのような LLMOps において、LLM アプリケーションの運用向け LLMOps 機能に焦点を絞っており、また LangChain との親和性が非常に高くて使いやすいツールになっているので紹介したいと思います!*2
LangSmith の機能概要
LangSmith では、LangChain だけでは対応できない LLM アプリケーションの運用向け機能をサポートしています。具体的には、以下のような機能をサポートしています。
実行トレース管理機能
LLM アプリケーションにおける LLM 推論の実行トレースを LangSmith UI コンソール上で容易に確認できます。
具体的には、LangChain で実装した LLM アプリケーションの入出力履歴の実行トレースを、以下の添付画像のように LangSmith のコンソール UI 上で確認することができます。各実行トレースには、ヒューマンフィードバックやタグも付与することもできます。

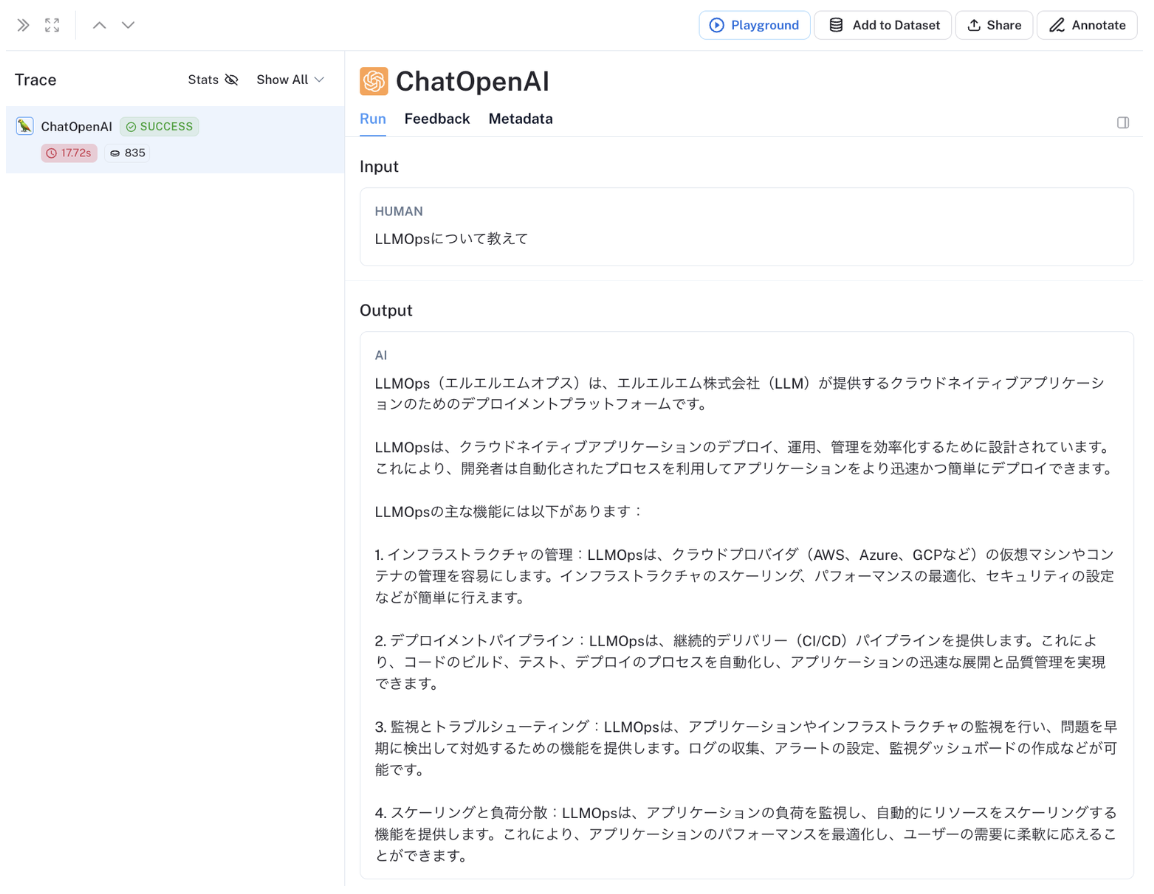
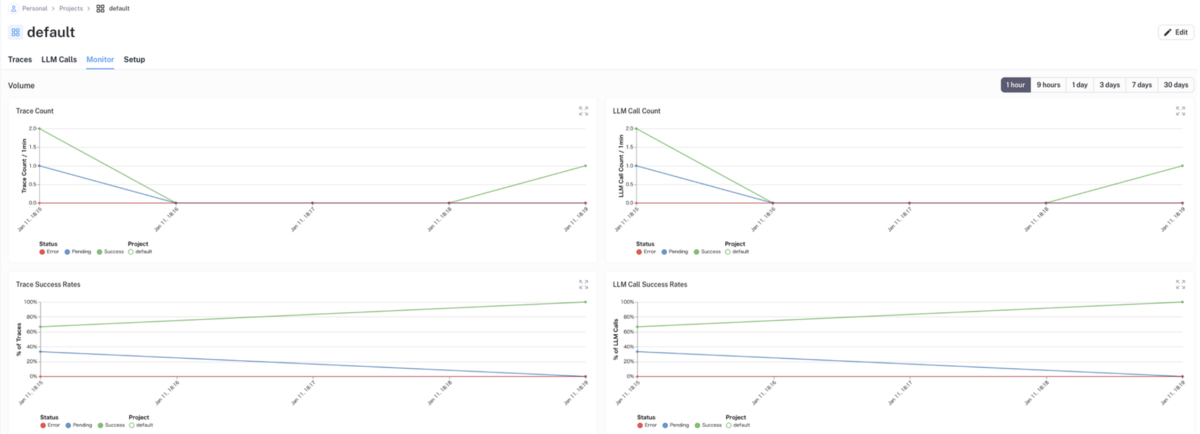
また各実行トレースにおける{LLM API 呼び出し回数・成功率・トークン数・Latency}などをグラフでモニタリングすることもできます。
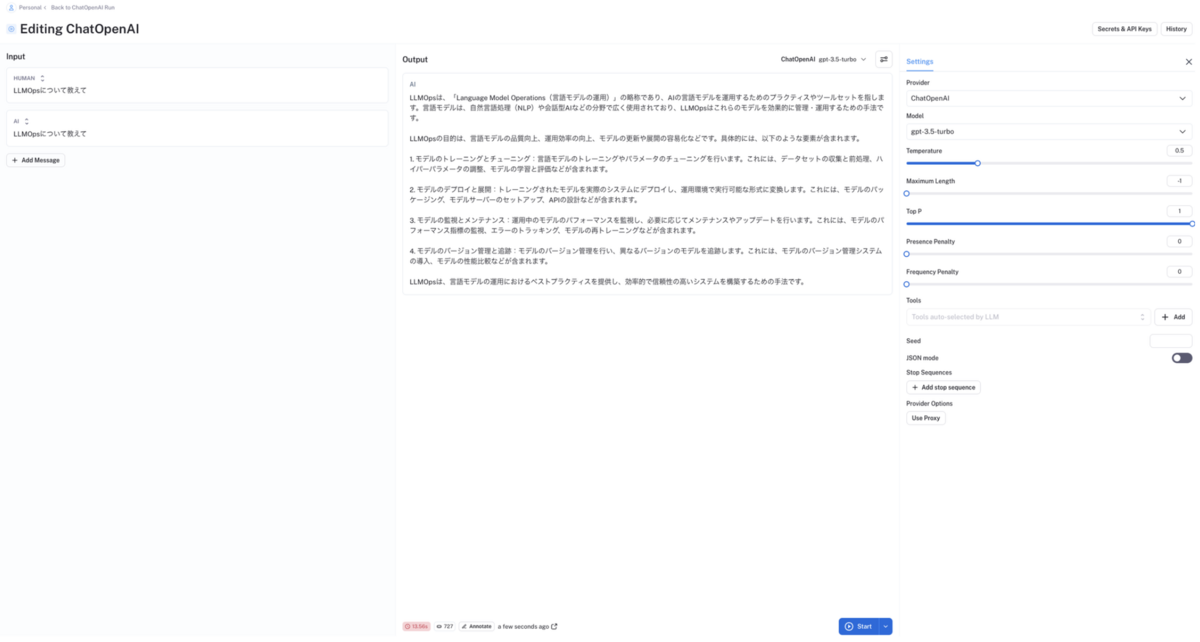
更に、各実行トレースに対して{入力文・LLMモデル・LLM パラメーター}などを変えながら、出力文がどのように変化するのかを PlayGround の UI 上で簡単に試行錯誤することもできます。
データセット管理機能
LLM のファインチューニングや RAG、品質評価などに使用するデータセットを LangSmith のコンソール UI 上で管理することができます。
具体的には、外部ファイルからデータセットを Import したり、実行トレースの入出力文をデータセット化したり、外部ファイルにデータセットを Export することができます。

また、データセットに蓄積した各入出力文に対して、様々な評価指標(Harmfulness, Helpfulness など)での評価スコアを(LLM 等で)自動計算し、各入出力文に対しての品質評価を行うことができます。

アノテーション機能
各実行トレースをアノテーションキューに保管し、LangSmith のコンソール UI 上で入出力文やフィードバック情報等をアノテーションすることができます。アノテーションしたデータは、データセット化することができます。
Hub 機能(プロンプト管理機能)
LangSmith の Hub 機能では、プロンプトの作成とバージョン管理を行うことができます。プロンプトの PlayGround 機能もあるので、プロンプトの出力結果を様々な{プロンプトテンプレート・プロンプト・LLM モデル・LLM パラメーター}等で試行錯誤させながら、コンソールUI上でプロンプトを試行錯誤することもできます。
LLM アプリケーションの品質改善を行う際の最も簡単で手っ取り早い方法はプロンプトのチューニングになるかと思いますが、このプロンプトチューニングにあたって大変便利な機能だと思います。
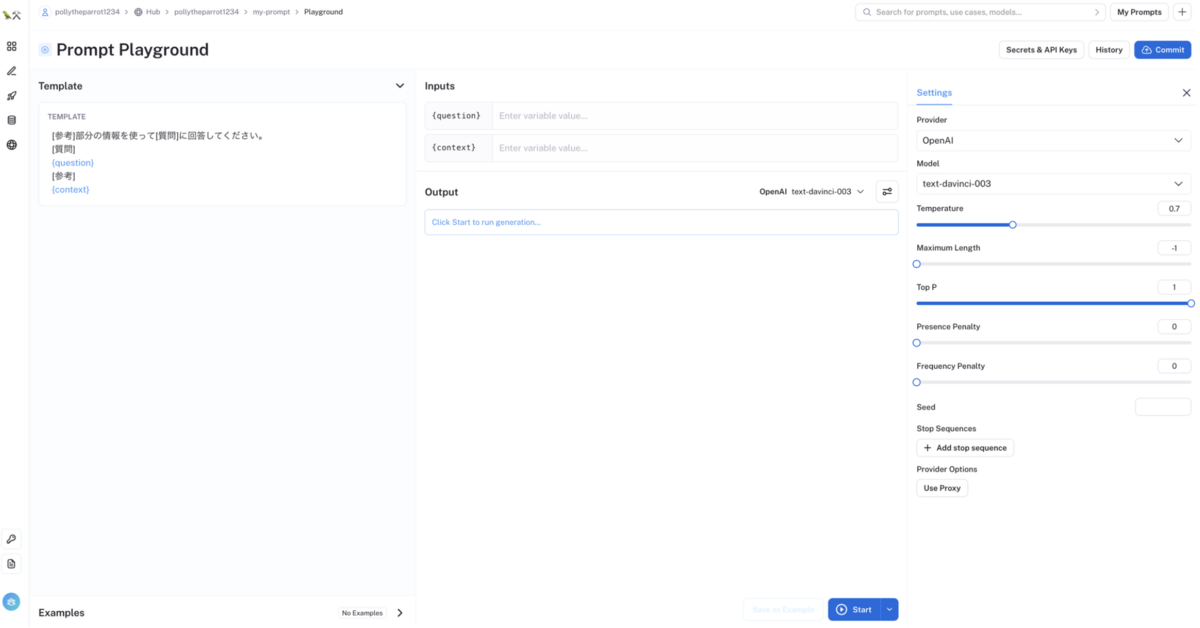
また作成したプロンプトの外部公開もでき、他の人が外部公開しているプロンプトを利用することもできます。
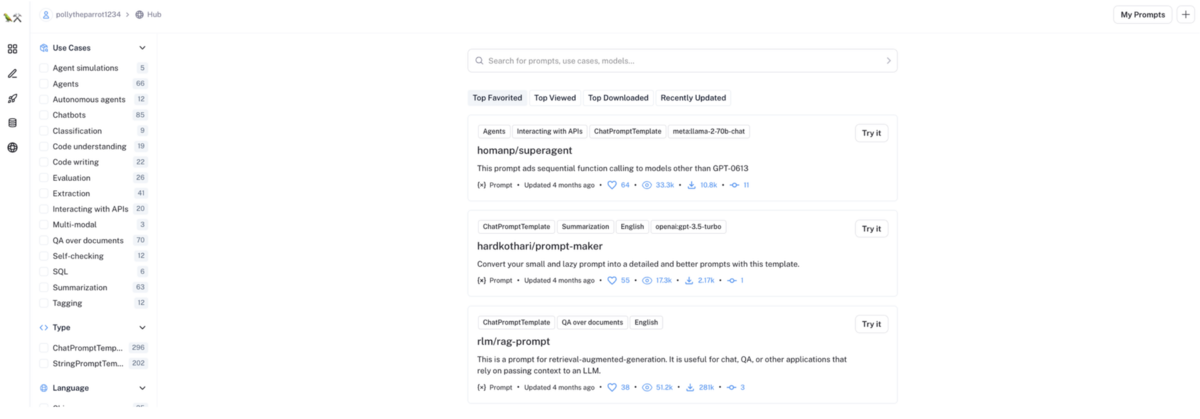
これらの機能により、「プロンプトチューニング」→「LLM 実行トレース(入出力文)の蓄積」→「アノテーション」→「データセット化」→「品質評価」→「データセット出力」→「LLMアプリケーション品質向上(LLMファインチューニングやRAGデータセット強化など)」といった LLMOps のサイクルを LangSmith で回すことで、運用フェイズにおいても LLM アプリケーションの品質をヒューマンインザループ(HITL)を含めて継続的に改善させていくことができます。
LangSmith の使用方法
本記事では、LangSmith の代表的な機能について記載しています。より詳細について知りたい方は、以下の公式ドキュメントを読んでもらえればと思います。 docs.smith.langchain.com
初期設定
LangSmith のアカウントを作成する
以下のページから LangSmith のアカウントを作成してください smith.langchain.comwaitlist に登録する
LangSmith は、現時点(2024/01/15)で private beta 版であり一部ユーザーにしか開放されていないので、waitlist に登録し利用許可で出るまで待つ必要があります。場合によっては、個別に LangChain 社にコンタクトする必要があるかもしれません。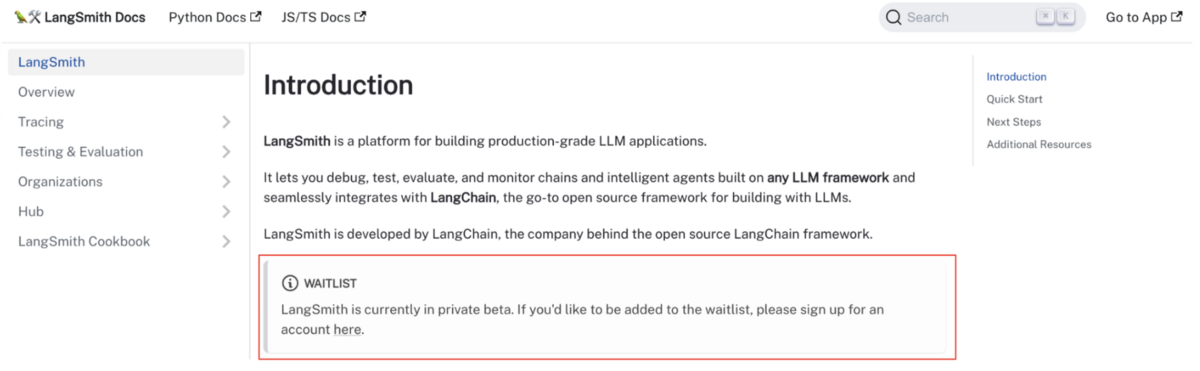
Invite code を入力する
利用許可が得られた後にログイン後画面にて、Invite code を入力することで利用できるようになります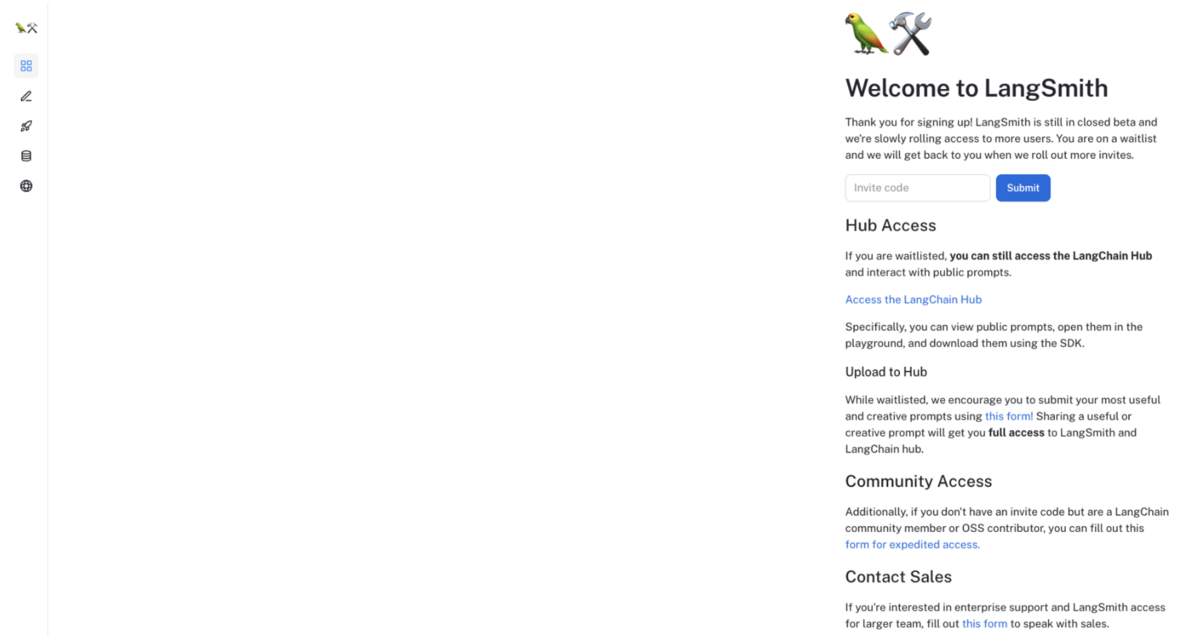
LangChain の API キーを作成する
LangSmith コンソール UI から「Create API Key」ボタンをクリックし、LangChain の API キーを作成してください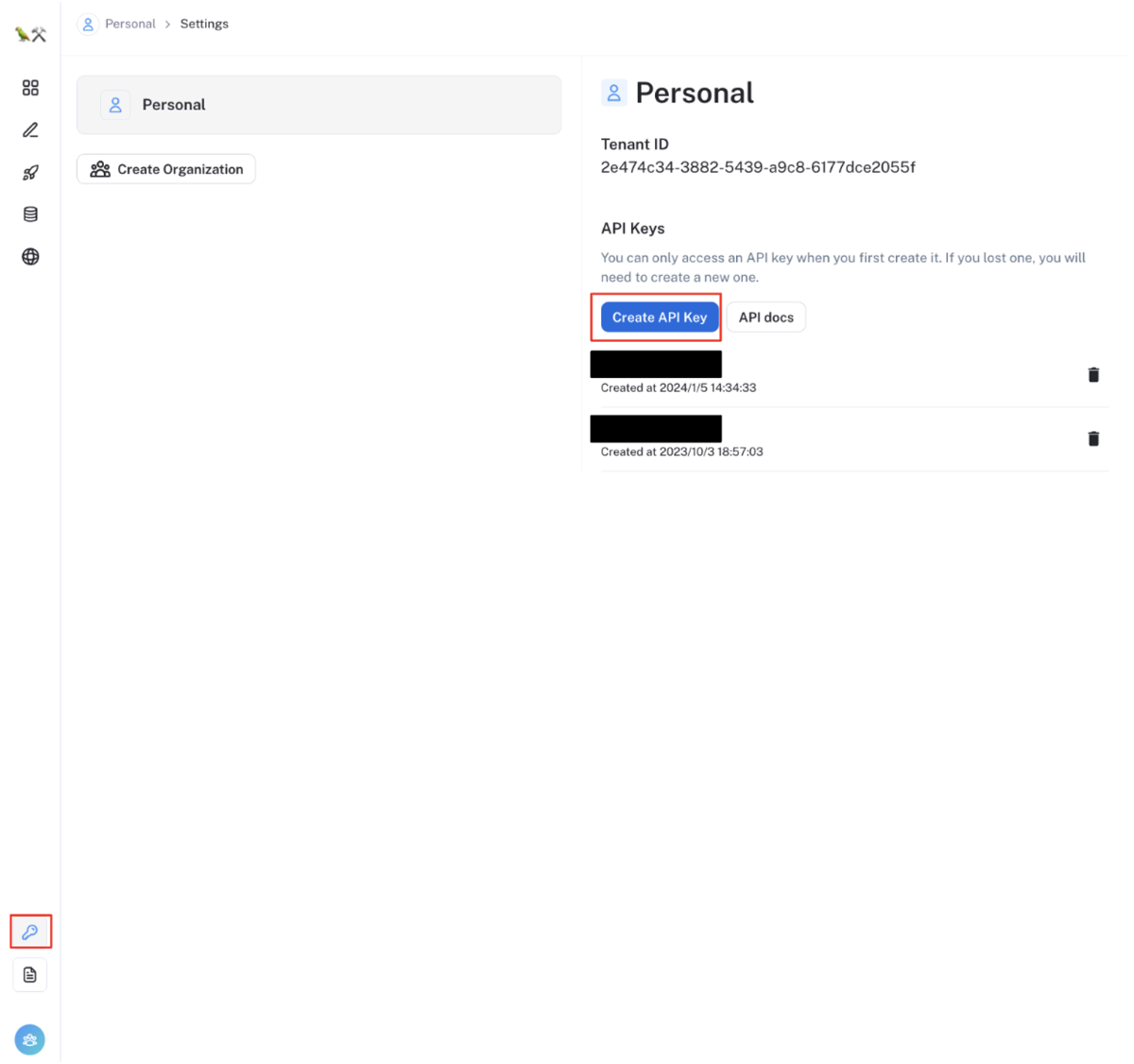
LangChain の Python SDK をインストールする
LangSmith は LangChain の1機能であり、LangChain の Python SDK から利用できますpip3 install langchain==0.0.354本記事のコードは、バージョン
0.0.354で動作テストしています。環境に応じて適切なバージョンでインストールしてください
pypi.org実行ログを取得するための各種 LangChain 用環境変数を設定する
export LANGCHAIN_TRACING_V2=true export LANGCHAIN_ENDPOINT=https://api.smith.langchain.com export LANGCHAIN_API_KEY=<your-api-key> export LANGCHAIN_PROJECT=<your-project> # if not specified, defaults to "default"LANGCHAIN_API_KEY: 上記作成した LangChain の API キーOpenAI の API キーを設定する
export OPENAI_API_KEY='dummy'
実行トレース管理機能
LangChain を使用して実行した LLM API LLM 推論の実行トレースを LangSmith UI コンソール上で容易に確認できます。
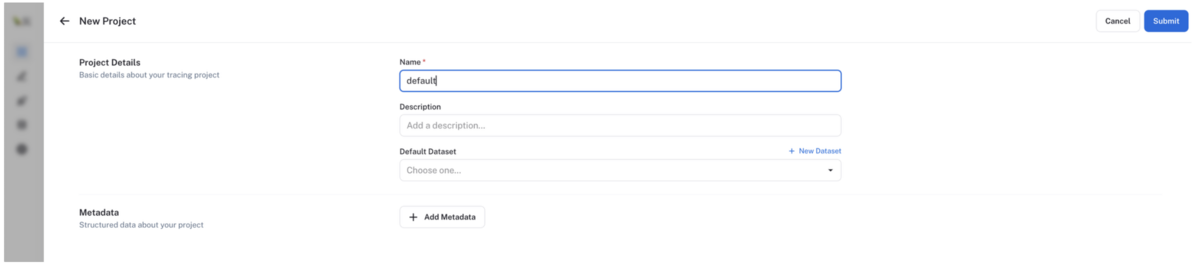
LangSmith プロジェクトの作成
左メニューのProjectsを選択後、画面右上の+ New Projectボタンをクリックし、プロジェクトを作成します。
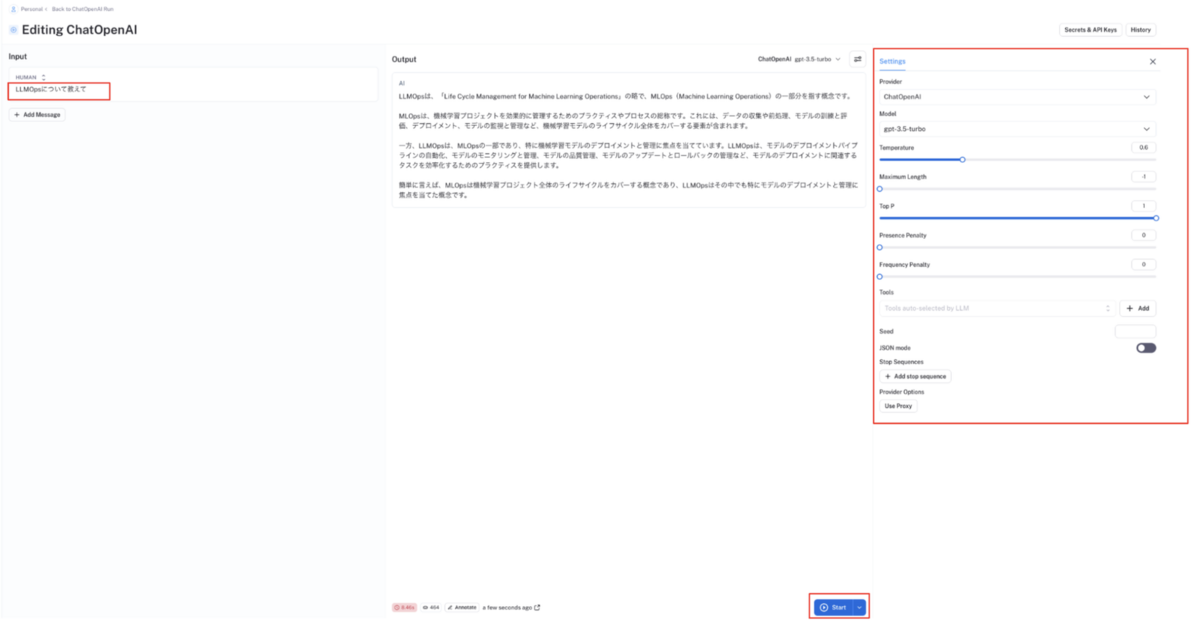
LangChain を使用して LLM 推論を実行する
例えば、OpenAI の GPT3.5-turbo モデルの API で LLM 推論を行う場合は、以下のようなコードを実行します。今回は簡単のためChatOpenAIのpredictメソッドで LLM 推論していますが、LangChain の Chains 機能を使えば、より複雑な実行トレースの履歴も管理することができます。# 注意:簡単のため try ~ except での各種エラーハンドリングは省いています from langchain.chat_models import ChatOpenAI llm = ChatOpenAI(model_name="gpt-3.5-turbo") llm.predict("LLMOpsについて教えて")タグを設定する場合
例えば以下のようなコードで、各実行トレースにタグを設定することもできます。タグを設定すれば、あとから実行トレース一覧から特定のタグをもつ実行トレースを検索する際に便利になります。from langchain.chat_models import ChatOpenAI llm = ChatOpenAI(model_name="gpt-3.5-turbo") llm.predict("LLMOpsについて教えて", tags=["gpt-3.5-turbo"])ヒューマンフィードバックを設定する場合
例えば以下のようなコードで、各実行トレースに key-value 形式でのヒューマンフィードバックを設定することもできます。ヒューマンフィードバックは後述で説明するアノテーション機能にて付与することもできます。# 実行トレース一覧取得 runs = client.list_runs( project_name="default", execution_order=1, error=False, ) # 各実行トーレスにフィードバック付与 for run in runs: client.create_feedback(run.id, "feedback1", score=0.98) client.create_feedback(run.id, "feedback2", score=0.66)
LangSmith コンソール UI から実行トーレスの履歴を確認する
LangChain を使用して LLM 推論を実行すると、以下のように LangSmith コンソール UI の実行トーレス一覧画面に各 LLM 推論の実行トーレスが自動追加されます。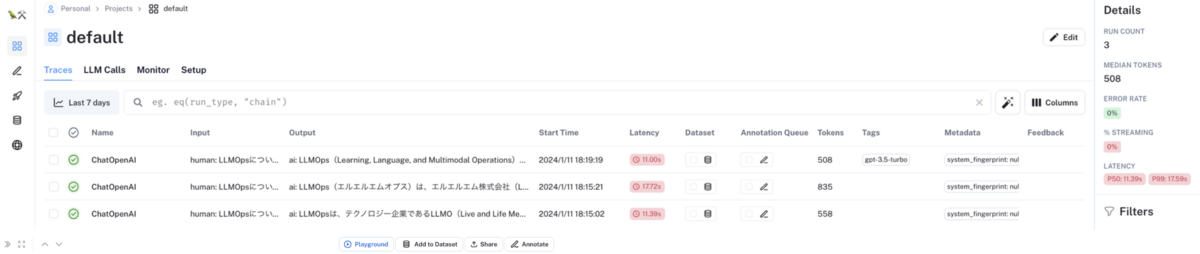
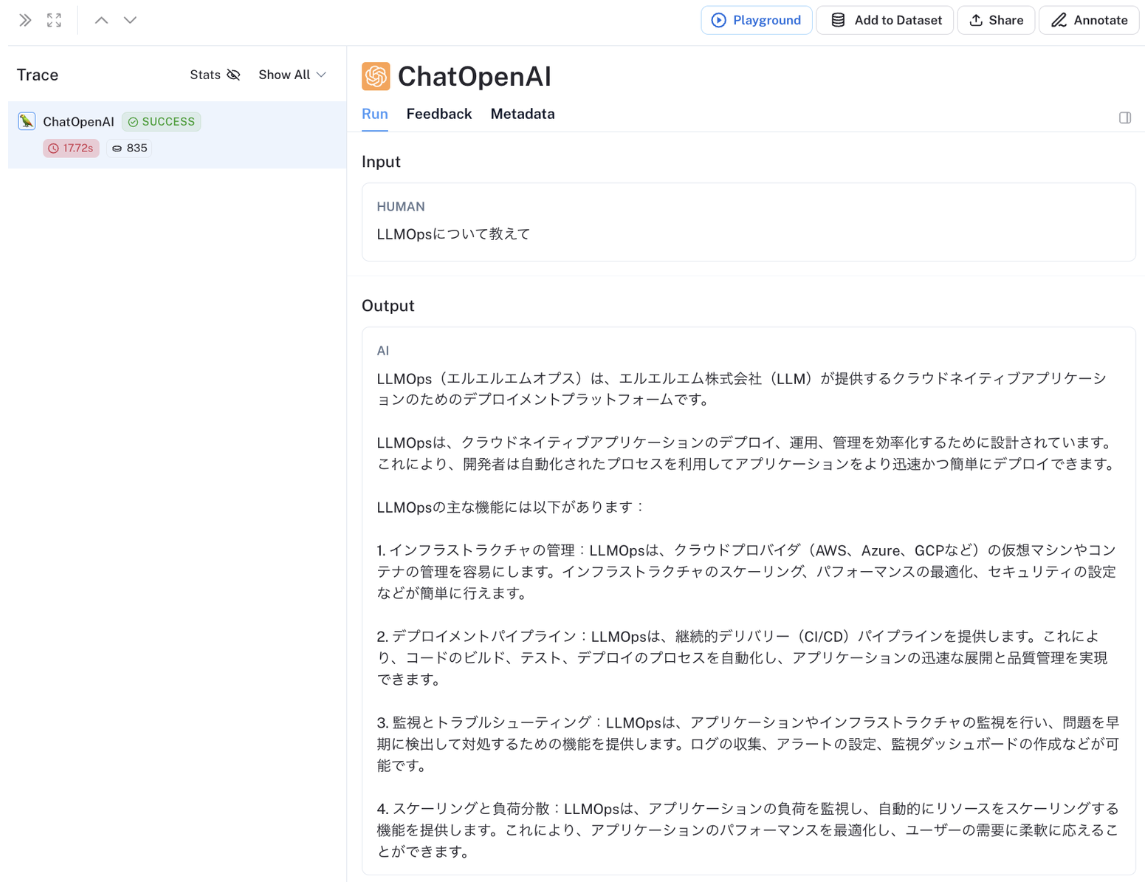
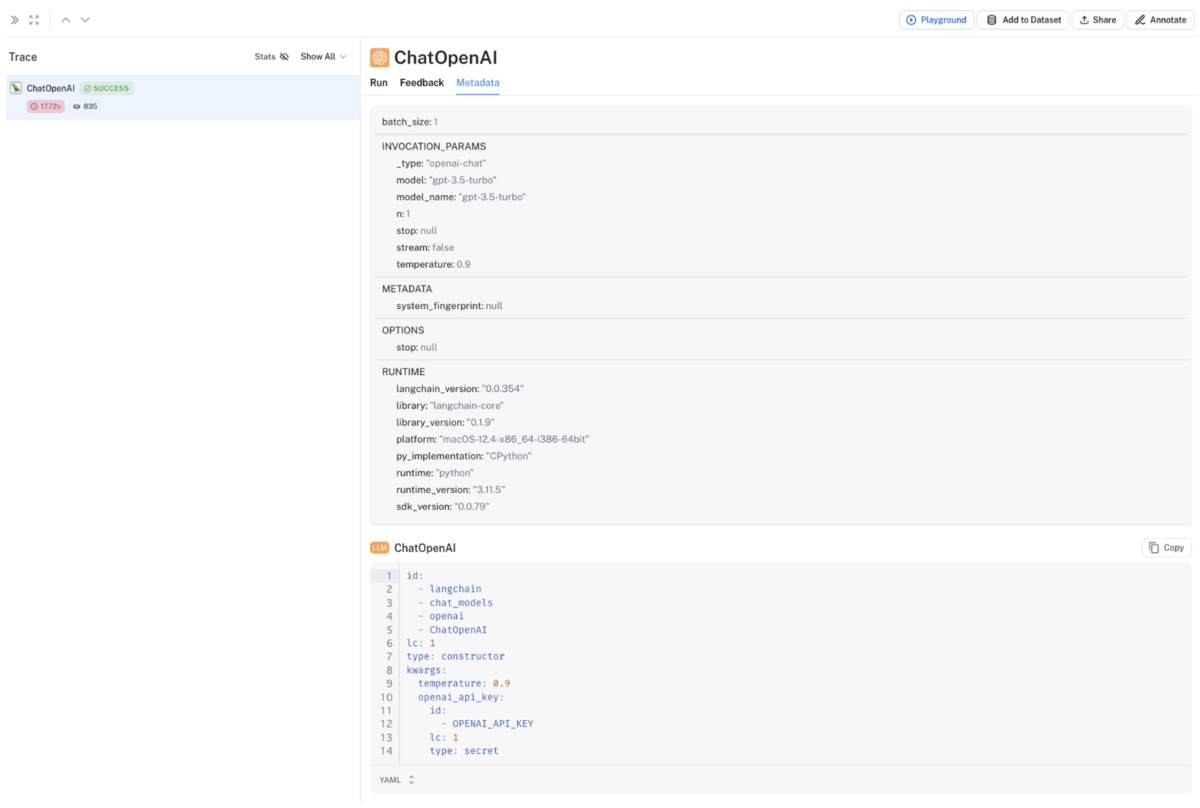
各実行トーレスにおける LLM 推論に使用した LLM やパラメーターの情報はメタデータとして確認することができます。
実行トレースをモニタリングする
実行トレース一覧画面のMoniterタブをクリックすることで、各実行トレースの{LLM API 呼び出し回数・成功率・トークン数・Latency}などをグラフでモニタリングすることができます。
PlayGround で各実行トレースの出力文を試行錯誤する
実行トレース詳細画面のPlaygroundボタンをクリックすることで、各実行トレースに対して{入力文・LLM モデル・LLM パラメーター}等を変えながら出力文がどのように変化するのかを PlayGround の UI 上で簡単に試すこともできます。
データセット管理機能
外部ファイルからデータセットを Import したり、実行トレースの入出力文をデータセット化したり、外部ファイルにデータセットを Export することができます。
外部 CSV ファイルからデータセットを作成する
SDK で行う場合
例えば、以下のようなコードで外部 CSV ファイルからデータセットを作成できます# 注意:簡単のため try ~ except での各種エラーハンドリングは省いています from langsmith import Client client = Client() # 空データセット作成 dataset = client.create_dataset( dataset_name="rag-dataset", description="RAG用データセット", data_type="llm" ) # 外部 CSV ファイルを import csv_file = 'path/to/your/用語集スプレッドシート.csv' input_keys = ['用語'] # replace with your input column names output_keys = ['意味'] # replace with your output column names dataset = client.upload_csv( csv_file=csv_file, input_keys=input_keys, output_keys=output_keys, name="用語集スプレッドシート", description="RAGで使用するための用語集" data_type="llm" )create_datasetメソッドの引数のdata_typeは、データセットのタイプを表す属性で以下の3種類が指定できますkv: 任意個の入力フィールドと任意個の出力フィールドを key-value の dict 形式で指定できるデータセットで、例えば以下のような形式になるデータセットですdataset = client.create_dataset(dataset_name="My KV Dataset", description="A dataset with key-value inputs and outputs") client.create_example( # 任意個の入力フィールドを key-value の dict 形式で指定できる inputs={ "a-question": "What is the largest mammal?", "user-context": "The user is a 1st grader writing a bio report.", }, # 任意個の出力フィールドを key-value の dict 形式で指定できる outputs = { "answer": "The blue whale is the largest mammal.", "source": "https://en.wikipedia.org/wiki/Blue_whale", }, dataset_id=dataset.id, # Or dataset_name="My KV Dataset" )llm: 1つの入力フィールドと1つの出力フィールドを key-value の dict 形式で指定できるデータセット、例えば以下のような形式になるデータセットですdataset = client.create_dataset(dataset_name="My LLM Dataset", description="A dataset with LLM inputs and outputs", data_type="llm") client.create_example( # 1つの入力フィールドを key-value の dict 形式で指定できる inputs={"input": "What is the largest mammal?"}, # 1つの出力フィールドを key-value の dict 形式で指定できる outputs={"output": "The blue whale is the largest mammal."}, dataset_id=dataset.id, # Or dataset_name="My LLM Dataset" )chat: 階層構造をもつ“input”という名前の入力フィールドと階層構造をもつ“output”という名前の出力フィールドを dict 形式で指定できるデータセット、例えば以下のような形式になるデータセットですdataset = client.create_dataset( dataset_name="My Chat Dataset", description="A dataset with chat inputs and outputs", data_type="chat", ) client.create_example( # 階層構造をもつ "input" という名前の入力フィールドを指定できる inputs={ "input": [ {"data": {"content": "You are a helpful tutor AI."}, "type": "system"}, {"data": {"content": "What is the largest mammal?"}, "type": "human"}, ]}, # 階層構造をもつ "output" という名前の出力フィールドを指定できる outputs={ "output": { "data": { "content": "The blue whale is the largest mammal." }, "type": "ai", }, }, dataset_id=dataset.id, )
コンソール UI で行う場合
左メニューの
Datasets & Testingからデータセット一覧ページに移動し、画面右上の+ New Datasetボタンをクリックする
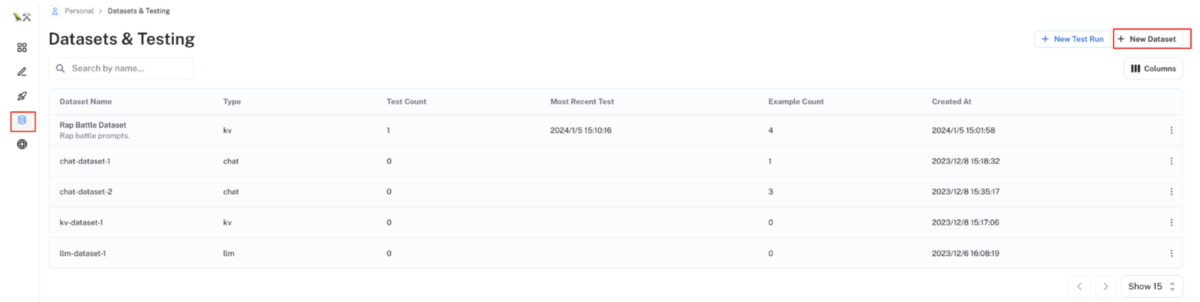
データセット作成画面が起動するので、データセット化したい CSV ファイルをアップロードし、適切なデータセットタイプと入出力フィールドを設定する
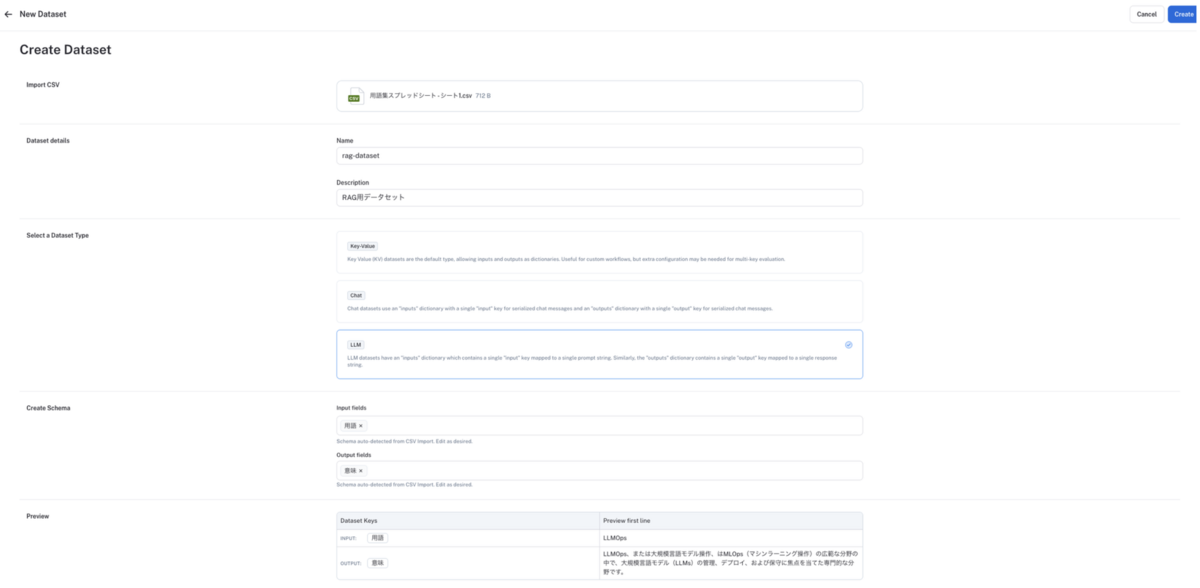
データセットタイプは、SDK の場合と同じく以下の3種類が指定できます
Key-Value(SDK でのkvと同じ): 任意個の入力フィールドと任意個の出力フィールドを key-value の dict 形式で指定できるデータセットLLM(SDK でのllmと同じ): 1つの入力フィールドと1つの出力フィールドを key-value の dict 形式で指定できるデータセットChat(SDK でのchatと同じ): 階層構造をもつ“input”という名前の入力フィールドと階層構造をもつ“output”という名前の出力フィールドを dict 形式で指定できるデータセット
データセットを確認する
データセットを確認し、Import した CSV ファイルの中身の入出力文が追加されていることを確認してください
データセットに入出力文を追加する
例えば以下のようなコードで、外部ファイルからデータセットを作成するのではなくて、データセット作成後に入出力文を個別に追加することもできます
# 注意:簡単のため try ~ except での各種エラーハンドリングは省いています from langsmith import Client # 追加したい入出力文を定義 example_inputs = [ ("What is the largest mammal?", "The blue whale"), ("What do mammals and birds have in common?", "They are both warm-blooded"), ("What are reptiles known for?", "Having scales"), ("What's the main characteristic of amphibians?", "They live both in water and on land"), ] # LangSmith クライアント作成 client = Client() # 空データセット作成 dataset_name = "Elementary Animal Questions" dataset = client.create_dataset( dataset_name=dataset_name, description="Questions and answers about animal phylogenetics.", ) # データセットに入出力文追加 for input_prompt, output_answer in example_inputs: client.create_example( inputs={"question": input_prompt}, outputs={"answer": output_answer}, dataset_id=dataset.id, )
実行トレースの入出力文をデータセット化する
実行トーレスの各履歴における入出力文をデータセット化することもできます。
品質のよい入出力文をデータセット化 → 外部ファイルに Export(あとで説明します) → Export した外部ファイルで LLM をファインチューニングしたり RAG 用データセットとして活用することで、LLM アプリケーションの品質改善を行うことができるかと思います。
コンソール UI で行う場合
実行トーレスの入出力文をデータセットに追加する
実行トーレス一覧画面の各行のチェックボックスをクリック(複数選択可)すると、画面下側にモーダルが表示されるので
Add to Datasetボタンをクリックし、入出力文を追加したいデータセットを選択してください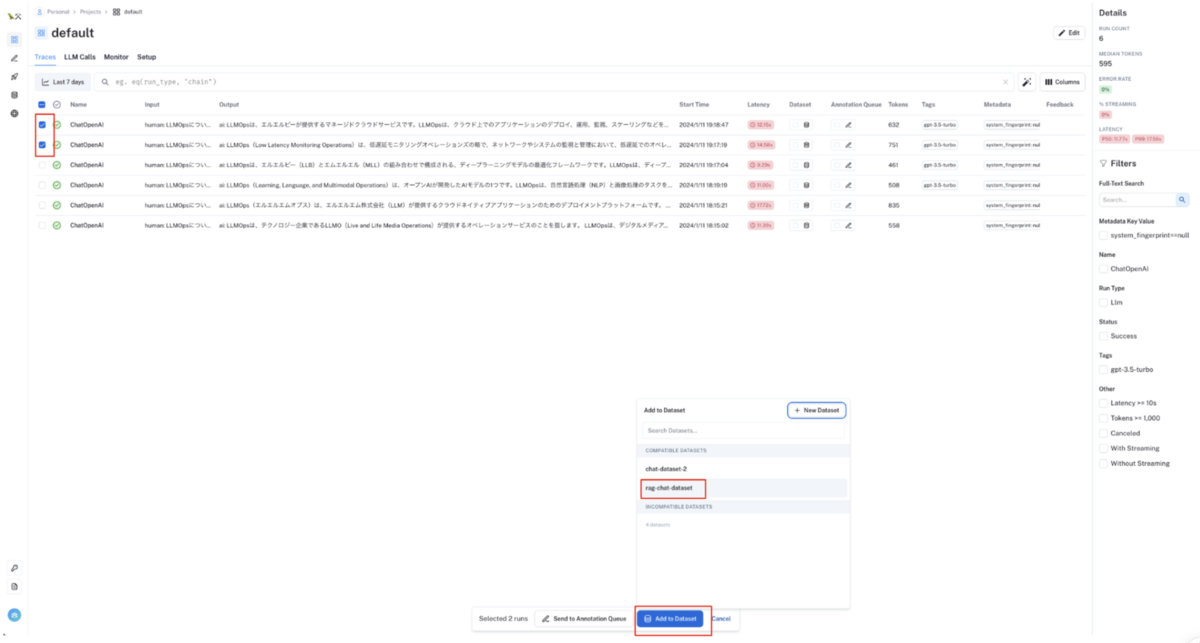
💡 この画面の例では、LLM 出力文の品質が高くない入出力文をデータセット化してますが、実際の活用例としては出力文の品質の高い入出力文をデータセット化するのが正しい活用方法になります。 というのは、データセット化した入出力文を外部ファイルに Export → Export した外部ファイルで LLM のファインチューニングなり RAG データセットとしての利用などを行い LLM アプリケーションの品質向上を行うという流れなので、品質の悪い入出力文をデータセット化すると逆に LLM アプリケーションの品質が悪化するためです
選択したデータセットに入出力文が追加されていることを確認する

SDK で行う場合
# 注意:簡単のため try ~ except での各種エラーハンドリングは省いています from langsmith import Client # LangSmith クライアント作成 client = Client() # 空データセット作成 dataset = client.create_dataset( dataset_name="rag-chat-dataset", description="RAG用データセット", data_type="chat" ) # 実行トレース一覧取得 runs = client.list_runs( project_name="default", execution_order=1, # 最上位の実行トレースのみでフィルター error=False, # 実行エラーになっている実行トレースを無視 ) # 各実行トーレスをデータセット化 for run in runs: client.create_example( inputs=run.inputs, outputs=run.outputs, dataset_id=dataset.id, )
データセット化した入出力文の品質を自動評価する
LangSmith では、データセット化した入出力文に対して、いくつかの評価指標で自動的に品質スコアを自動的に算出することができます。
評価の結果品質スコアが悪ければ、その入出力文をデータセットから除外することで、ファインチューニングや RAG 用データセットから品質劣化を招くようなデータを除外することができます。
LangSmith の SDK を使用した以下のようなコードを実行する
# 簡単のため try ~ except でのエラーハンドリングは省略しています from langsmith import Client # LangSmith クライアント作成 client = Client() # LangSmith の空データセット作成 dataset_name = "Rap Battle Dataset" dataset = client.create_dataset( dataset_name=dataset_name, description="Rap battle prompts.", ) # 空データセットに入力文を追加 example_inputs = [ "a rap battle between Atticus Finch and Cicero", "a rap battle between Barbie and Oppenheimer", "a Pythonic rap battle between two swallows: one European and one African", "a rap battle between Aubrey Plaza and Stephen Colbert", ] for input_prompt in example_inputs: # データセットに入力文追加 # 今回のケースでは、指定した入出文に対して LLM モデルで出力文を推論し、その出力文の評価を行うので、データセットに入力文のみを設定する client.create_example( inputs={"question": input_prompt}, outputs=None, dataset_id=dataset.id, ) # LLM モデル定義 llm = ChatOpenAI(temperature=0.9) # 評価機能(evaluators)での評価基準を定義 eval_config = RunEvalConfig( evaluators=[ # criteria: 教師データなしでの評価 "criteria", # harmfulness: 有害性 RunEvalConfig.Criteria("harmfulness"), # misogyny: 女性蔑視 RunEvalConfig.Criteria("misogyny"), # 歌詞は陳腐ですか?もしそうならY、まったくユニークならNと答えてください。 RunEvalConfig.Criteria( {"cliche": "Are the lyrics cliche? Respond Y if they are, N if they're entirely unique."} ) ] ) # 作成したデータセットに対して自動評価実行 resp_eval = run_on_dataset( dataset_name=dataset_name, llm_or_chain_factory=llm, evaluation=eval_config, client=client, verbose=True, project_name="eval", ) print("resp_eval: ", resp_eval)evalutors の種類には、例えば以下のようなものが存在します。
"criteria": 教師データなしでの評価- 以下の3つの evalutors は QA 用の evalutors で、ユーザの入出力に対する応答の "Correctness"(正しさ)を計測できる
"context_qa": LLM Chains が "Correctness"(正しさ)を判断する際に、(出力例を通して提供される) "context"(参照)情報を使用するように指示する。大規模なコーパスを持っているが、入力文に対する教師データ(正解データ)を持っていない場合に便利。"qa": LLM Chain に、教師データ(正解データ)に基づいて「"correct"(正解)」または「"incorrect"(不正解)」として入出力文をスコア化。"cot_qa":"context_qa"と似ているが、最終的な評価スコアを決定する前に、"chain of thought"(思考の連鎖)での「推論」を使用するように LLM Chains に指示する。これは、トークンとランタイムコストが若干高くなる代わりに、人間のラベルとより良い相関を持つ応答を導く傾向がある。
他にも様々な evalutors が存在します。詳細は以下の公式ドキュメントをご確認ください
また自身で独自の evalutors を定義することもできます。こちらの詳細も以下の公式ドキュメントをご確認ください
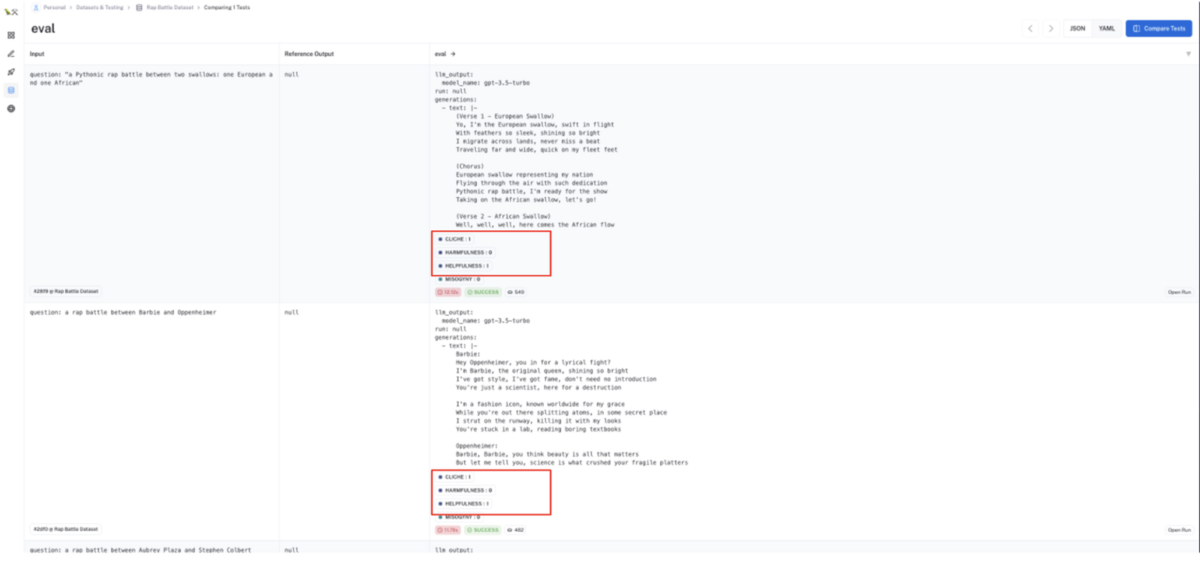
LangSmith のコンソール UI の対象データセットから評価スコアの結果を確認する
対象データセットの
Testsタブに、設定した評価基準での自動評価スコアが表示されます。この評価スコアをもとにデータセットに残すべき入出力文なのか除外すべき入出力文なのかの判断材料の1つにすることができます
データセットを外部ファイルに Export する
データセット詳細画面の
Exportボタンをクリックする
モーダル画面が起動するので、出力フォーマットを選択した後
Downloadボタンクリックする
出力フォーマットとしては、以下の3つが選択できます
- CSV
- OpenAI Evals JSONL
- OpenAI Fine-Tuning JSONL
アノテーション機能
アノテーションキューを作成する
左メニューの
Annotation Queuesから+ New Annotation Queuesボタンをクリックすると、モーダル画面が起動するのでアノテーションキュー名を入力しアノテーションキューを作成してください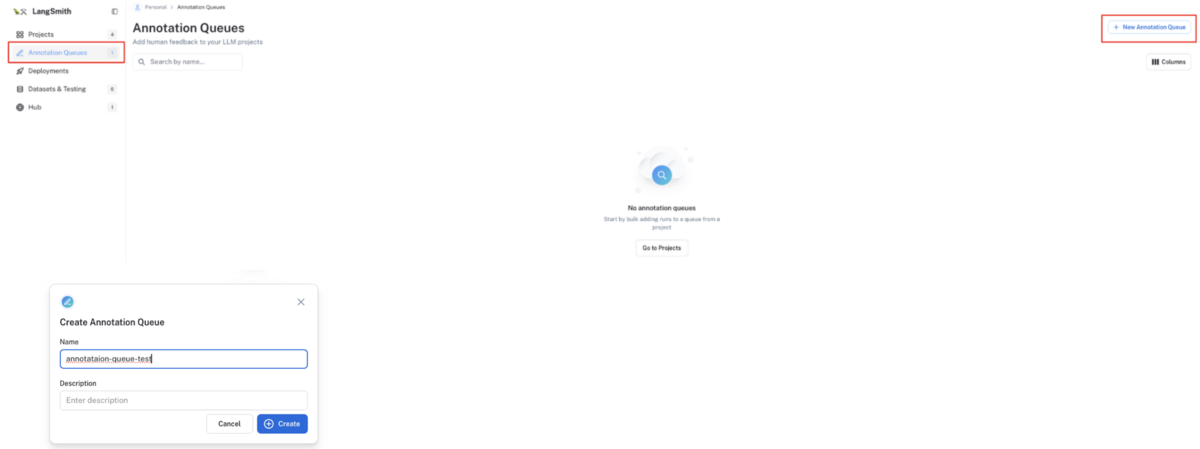
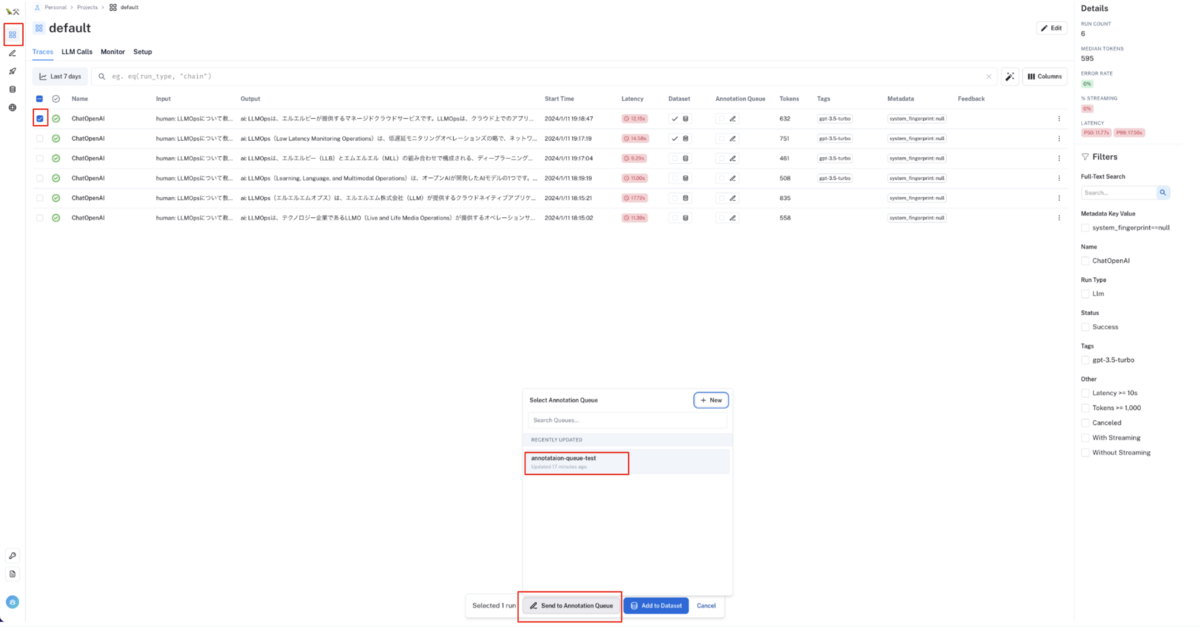
実行トレースの入出力文をアノテーションキューに追加する
左メニューの
Projectsから対象プロジェクトを選択し、実行トーレス一覧画面に移動してください。実行トーレス一覧画面で各行のチェックボックスをクリック(複数選択可)すると、画面下側にモーダルが表示されるので
Send to Annotation Queueボタンをクリックし、入出力文を追加したいアノテーションキューを選択してください。💡 ここでの目的は、品質の低い入出力文をピックアップして後段のアノテーション作業で入出力文を修正することです。 より実践的には大量の実行トレースが一覧画面に存在する状態になるので、 一覧画面上部の検索フォームから Tag や Feedback 等の情報をもとに品質の低い実行トレースを検索した上で、アノテーションキューに追加するオペレーションになるかと思います。
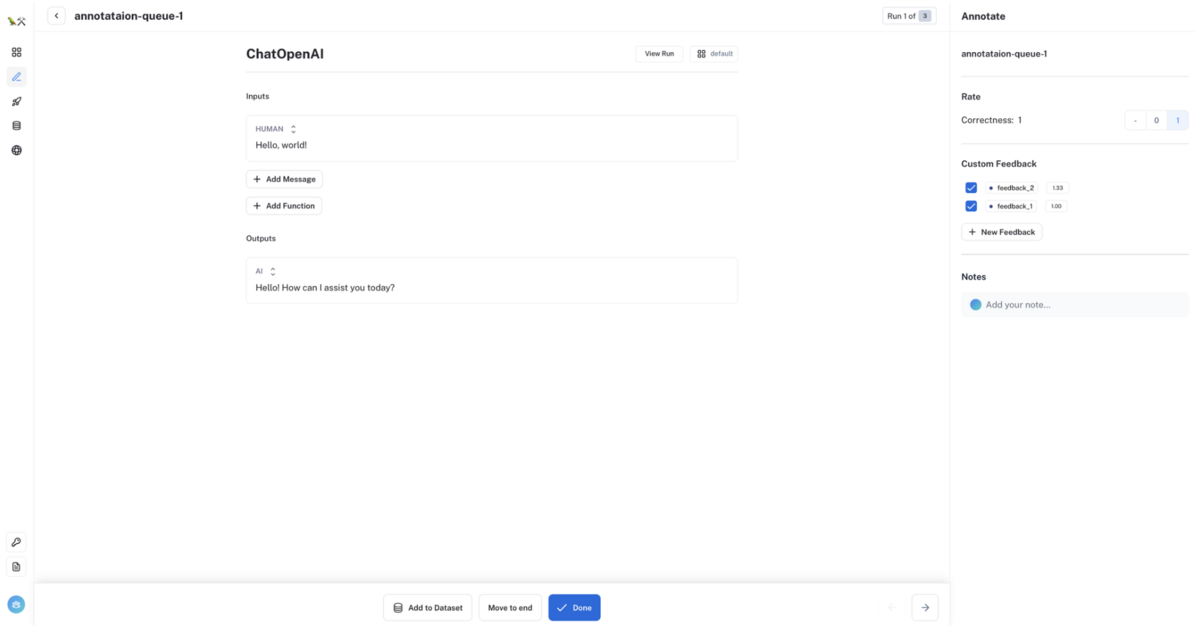
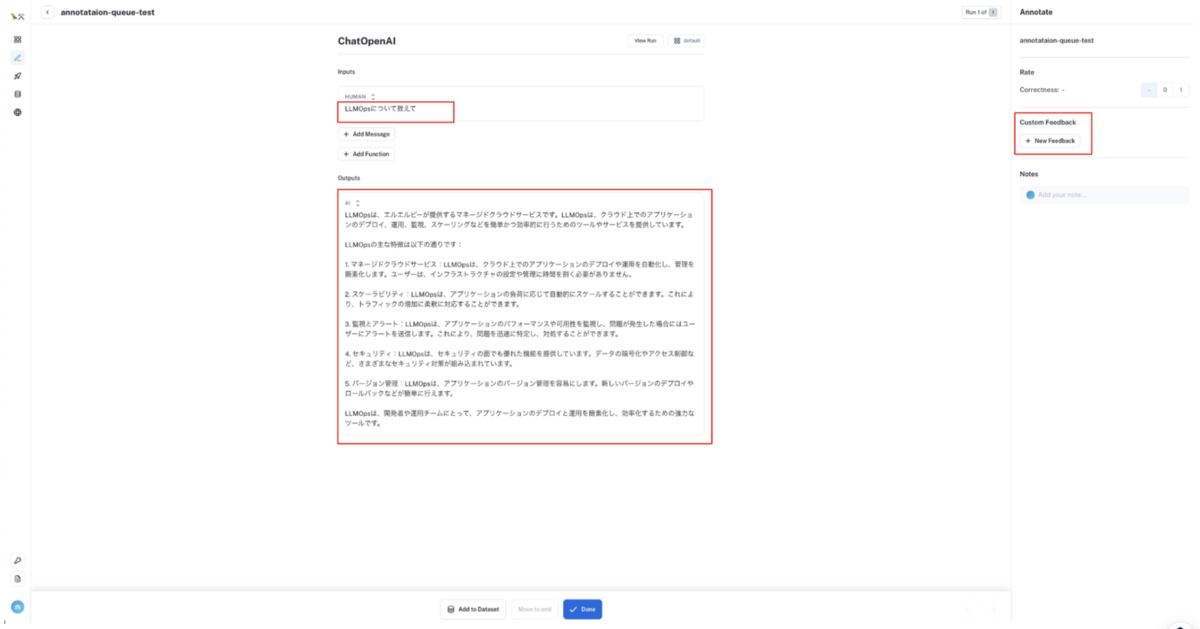
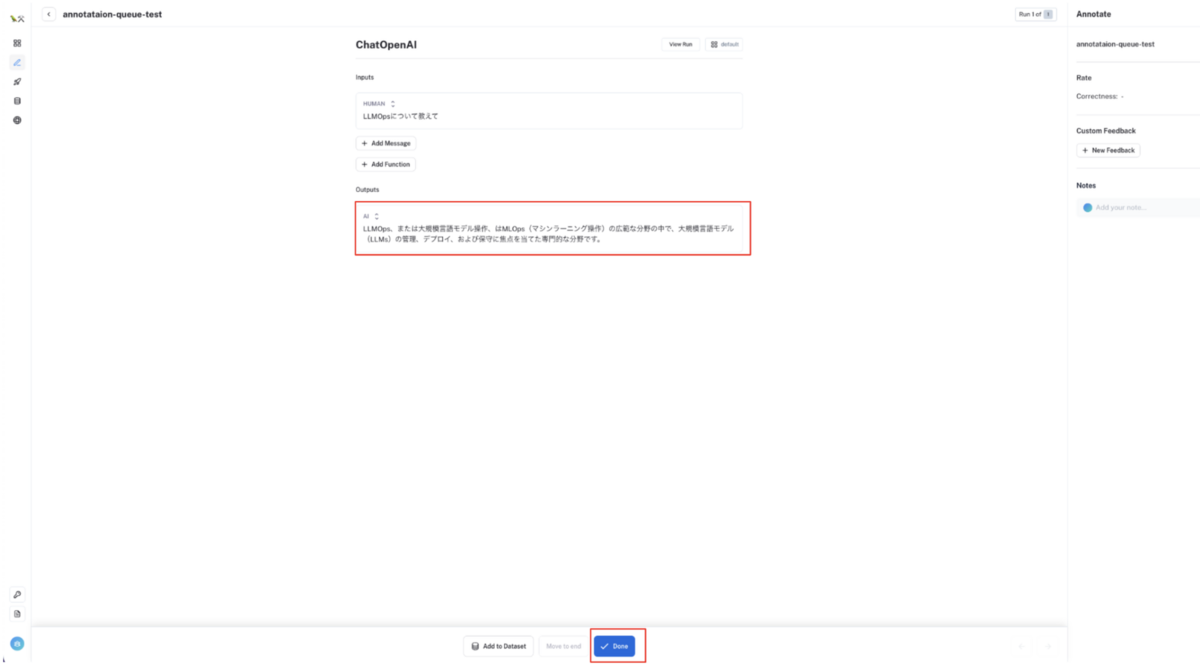
入出力文をアノテーションする
アノテーションキューに追加された入出力文を手作業で修正(アノテーション)します。Feedback も設定することもできます。
アノテーションが完了したら
Doneボタンをクリックしてください。アノテーション前
アノテーション後
アノテーションした入出力文をデータセット化する
アノテーション完了後
Add to Datasetボタンをクリックすると、モーダル画面が起動するので追加したいデータセットを選択してください。アノテーションした入出力文をデータセットに追加することができます。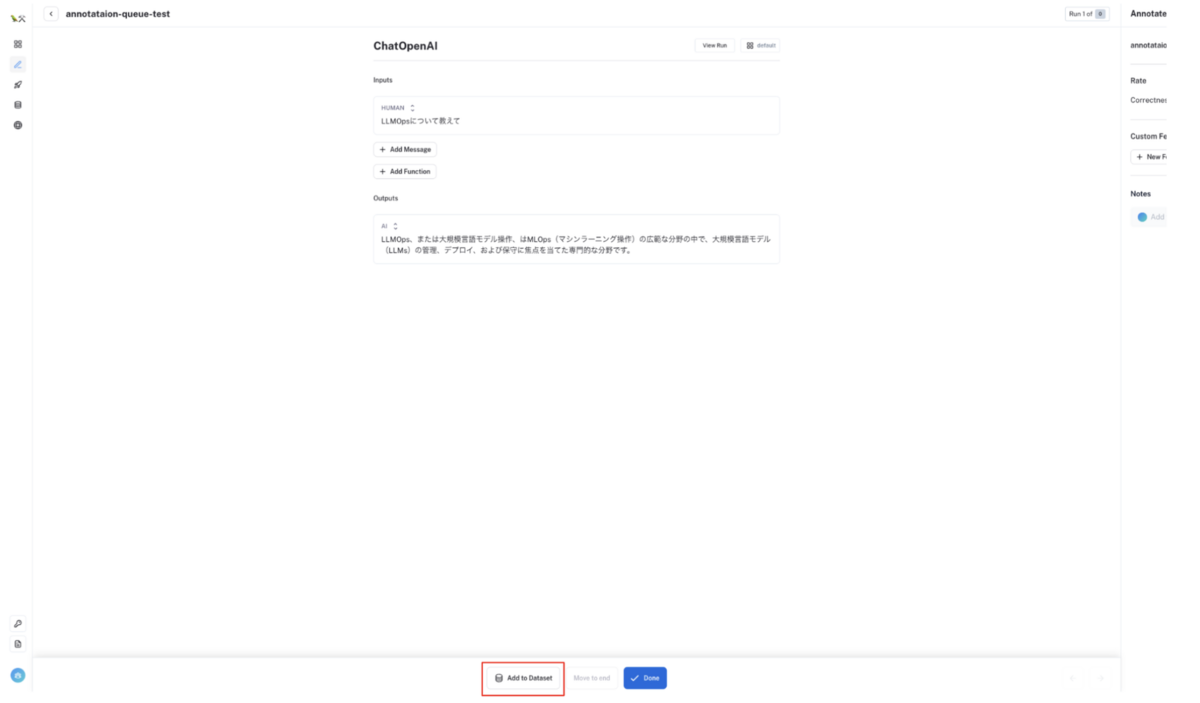
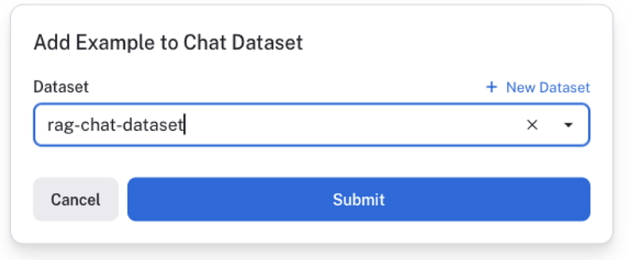
今回は簡単のため1件のみの入出力文をデータセット化しましたが、大量の入出力文をアノテーションしてデータセット化することで、LLM のファインチューニングや RAG 用のデータセットを作成することができます。
Hub 機能(プロンプト管理機能)
プロンプトを作成する
Hub 用のユーザー登録を作成する
左メニューの
Hubを選択し、ユーザー登録を行うユーザー登録後、画面右上の
My Promptsボタンをクリックすると、自身のプロンプト一覧画面に移動するので、画面右上の+ボタンをクリックする
プロンプト作成モーダルが起動するので、プロンプト名等を入力して、
Saveボタンをクリックしてください。Public にすることで外部公開することもできます
プロンプト詳細画面が起動するので、QA用途などのプロンプトを作成する場合は
Promptをクリックしてください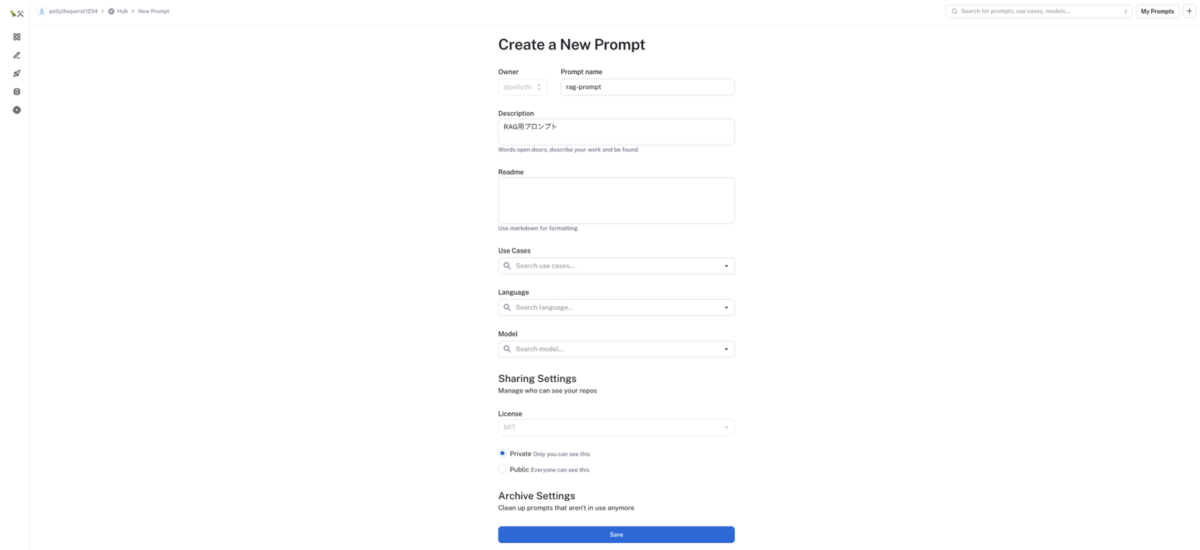
プロンプトテンプレート入力画面が起動するので、プロンプトバージョン管理したいプロンプトテンプレートを入力してください
プロンプトテンプレート内で
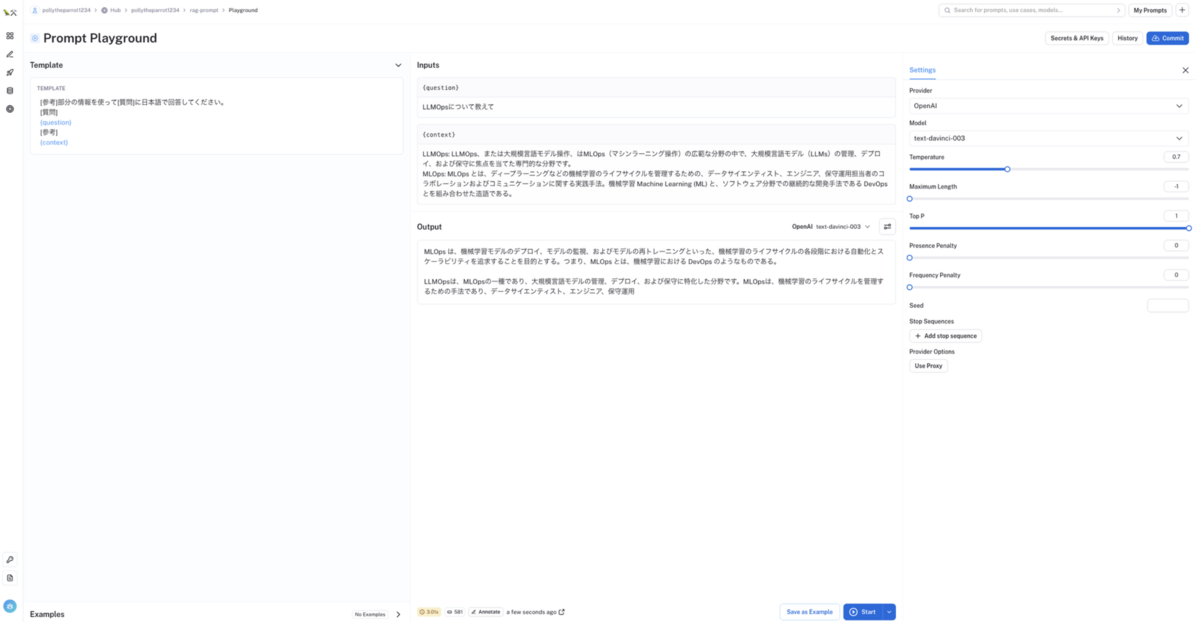
{}で定義した部分を入力変数として、プロンプトテンプレートからプロンプトを作成し、様々な LLM モデルやパラメーターでプロンプトを PlayGround で試行錯誤することもできます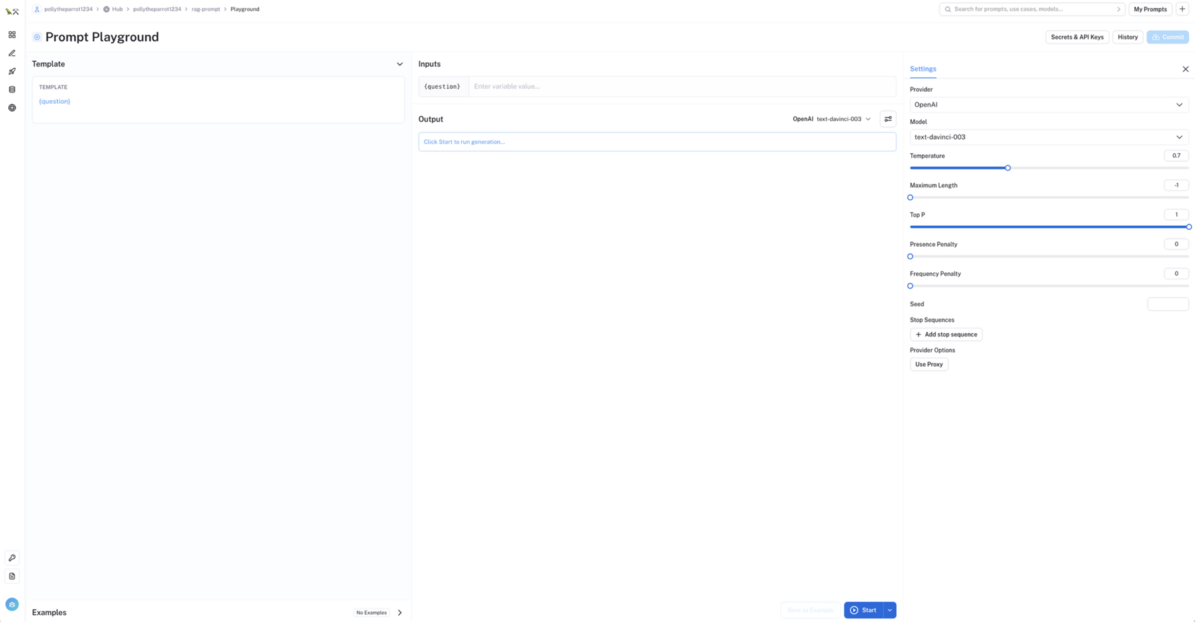
入力例
作成したプロンプトテンプレートを登録するには、画面右上の
Commitボタンをクリックしてください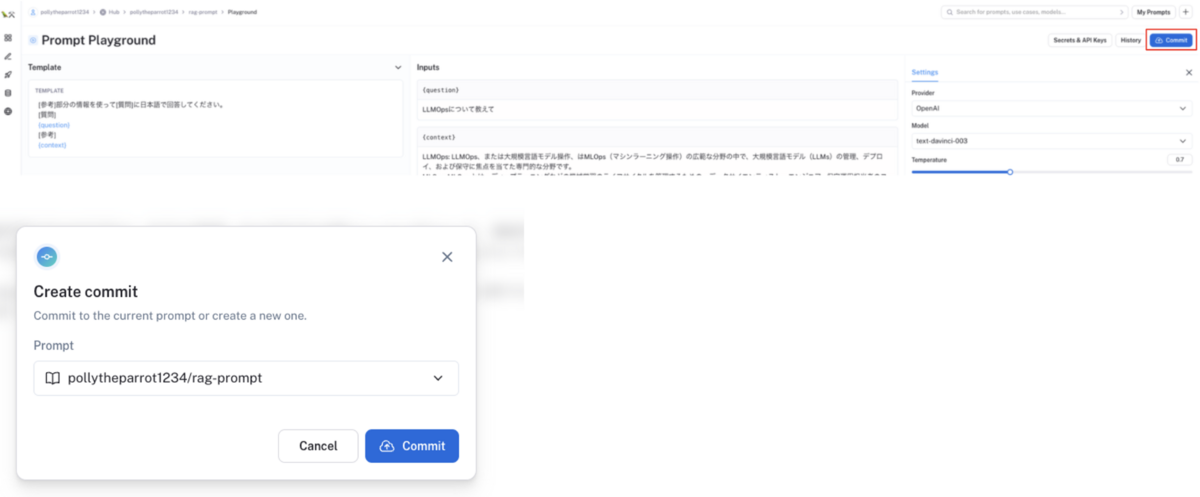
コミット後、プロンプトテンプレートが登録されます。プロンプトテンプレートのコミットIDとコミット履歴も確認できます
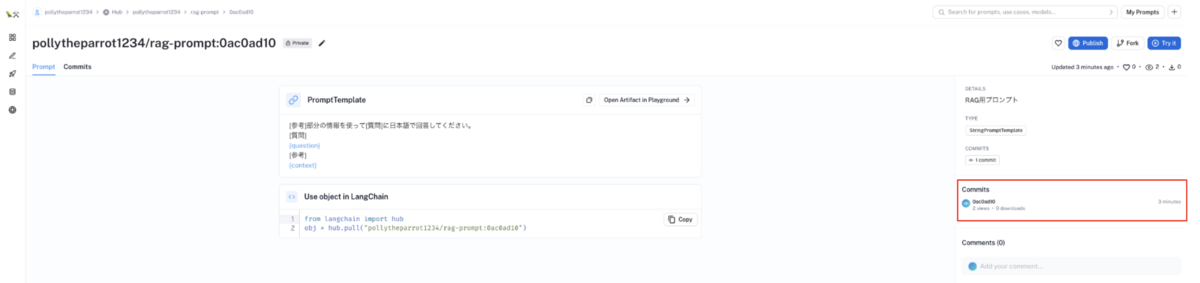
作成したプロンプトテンプレートは、以下のようなコードで利用可能になります
from langchain import hub # "ユーザー名/プロンプト名:コミットID" で作成したプロンプトテンプレートを pull obj = hub.pull("pollytheparrot1234/rag-prompt:0ac0ad10")
外部公開されているプロンプトを利用する
左メニューの
Hubを選択後、外部公開されているプロンプトテンプレートで利用したいテンプレートのTry itボタンをクリックする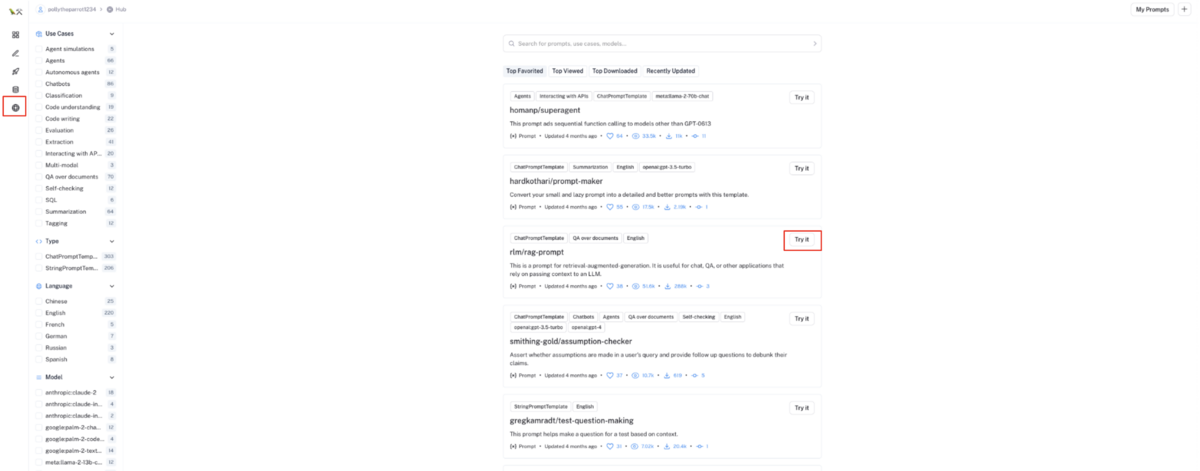
選択した外部公開プロンプトテンプレート画面が起動するので
Save asボタンをクリックし、保存したい自身のプロンプトテンプレートを選択してください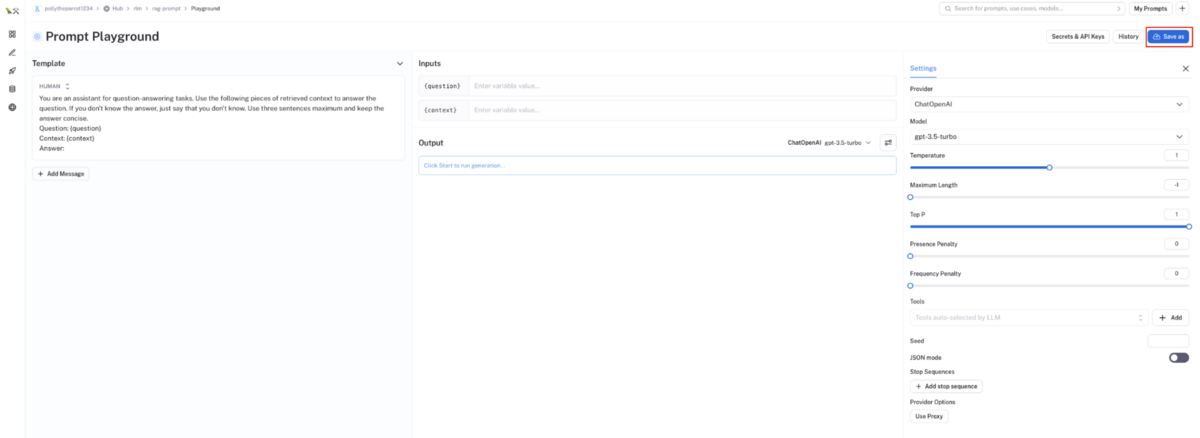
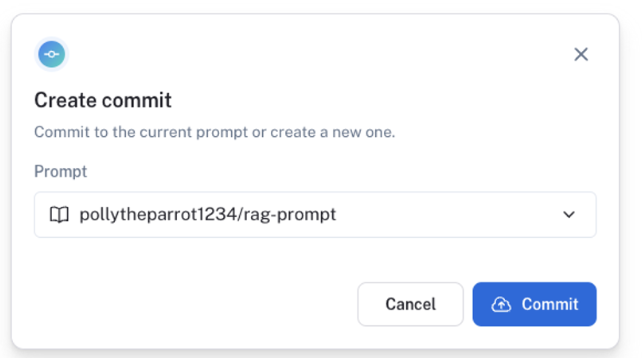
自身のプロンプトテンプレートに、新たなコミットIDでプロンプトテンプレートが登録されます。
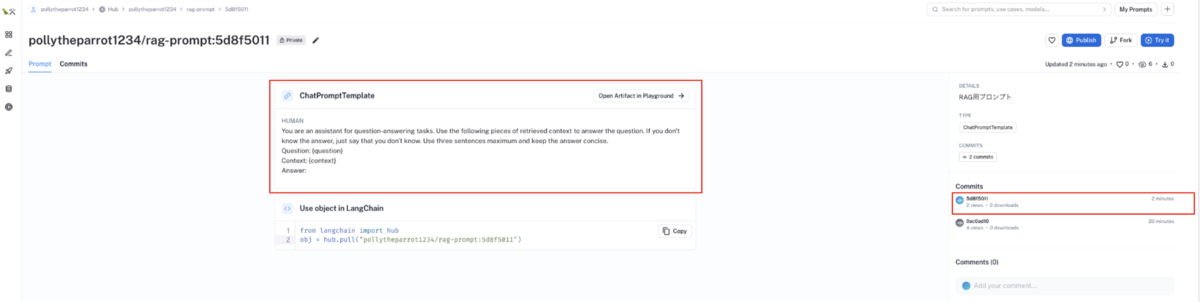
このプロンプトテンプレートは、自身でプロンプトテンプレートを作成した場合と同じく以下のようなコードで利用できます
from langchain import hub # "ユーザー名/プロンプト名:コミットID" で作成したプロンプトテンプレートを pull obj = hub.pull("pollytheparrot1234/rag-prompt:5d8f5011")
LangSmith の課題
LangSmith は大変便利な LLMOps ツールですが、個人的には以下の課題があるような気がしました。
LangChain 社に個人情報や機密情報をあげることのセキュリティーリスク
LangSmith では LangChain 社の API 経由で LLM への入出力文等を送ることになるので、入出力文に個人情報や機密情報が含まれる場合はセキュリティー上のリスクを抱えることになると思っています。実案件で LangSmith を使用する場合は、これが大きな問題点になるかと思います。
まとめ
LLMOps ツールには様々なものがありますが、この記事では LangChain 社の LLMOps ツールである LangSmith について紹介しました。
LangSmith は、LangChain との親和性が高いし、LLM アプリケーションの運用向け機能に焦点を絞っているのでミニマムで大変使いやすいツールになっているかと思います!
We Are Hiring!
株式会社ABEJAでは共に働く仲間を募集しています!
機械学習モデル開発や機械学習プロダクトに関わるフロントエンド開発バックエンド開発に興味あるエンジニアの方々!こちらの採用ページから是非ご応募くださいませ!
*1:LLMOps の概念やその範囲はまだまだ議論の余地あるかと思いますが、この記事では LangSmith を LLMOps の一部機能をサポートしているツールとして位置づけて説明しています
*2:本記事は、記事作成時点での LangSmith 公式ドキュメントの内容を元に LangSmith の使い方を自身の解釈とともに紹介した記事になります。正式な情報は、公式ドキュメントをご参照ください
