こんにちは!ABEJAでエンジニアをしている飯嶌です。これはABEJAアドベントカレンダー2024の16日目の記事です。
弊社では、ABEJA Platformに組み込まれた一つのアプリケーションとして「ABEJA Insight for Retail」を提供しています。このサービスには、IoTデバイスで取得したデータと、取り込んだPOSデータをもとに分析できる機能が備わっており、主には小売業界で活用されています。
POSデータは企業様からお預かりお預かりいただいたものですが、企業ごとにフォーマットや内容が異なり、多種多様です。 今回は、LLMを活用してそのようなデータのテーブルフォーマットの統一化できないか挑戦しましたので、その取り組みについてご紹介いたします。
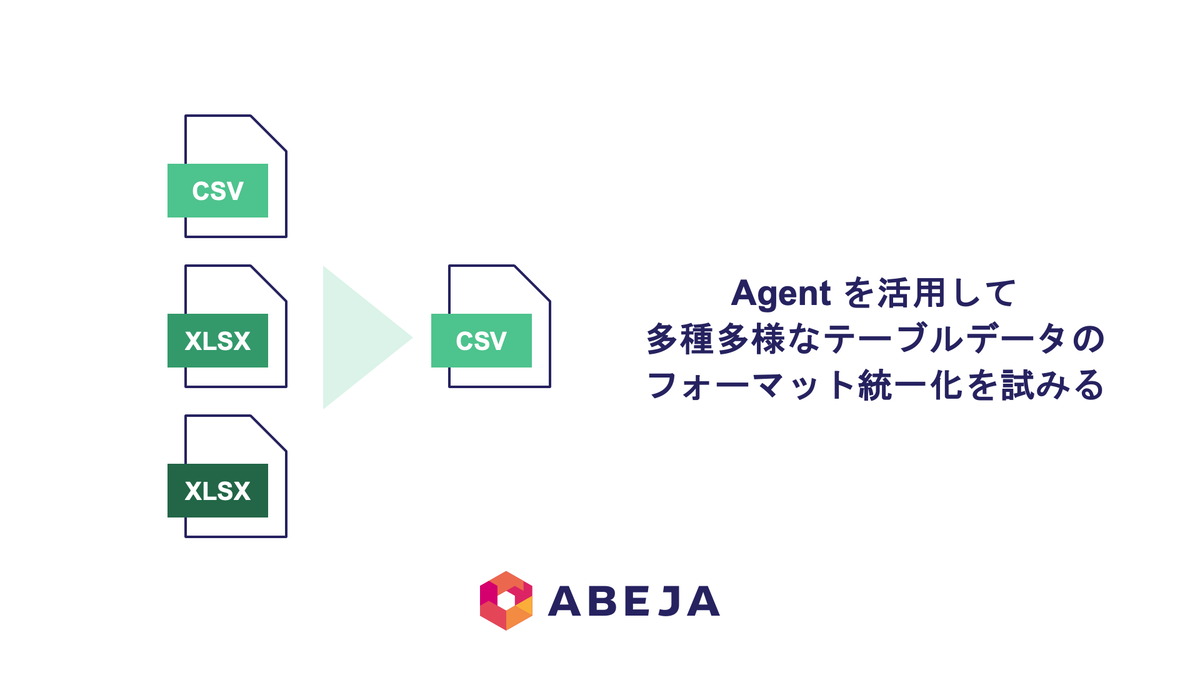
TL;DR
今回、Agent によるデータフォーマット統一の技術検証を行った結果、NaNをうまく排除したり、売上数が負の数を検出しながら、一定のロバスト性を持つようになりました。詳しくは本文でご紹介します!
前提
「ABEJA Insight for Retail」とは
本題に入る前に、まずは「ABEJA Insight for Retail」について簡単にご紹介します。
「ABEJA Insight for Retail」は、ABEJA Platformに組み込まれたアプリケーションで、店舗の内外で起こる顧客行動をAIで可視化・分析することで、売上向上につながる深いインサイトを引き出すことが可能です。主に小売業界で活用されています。具体的には、店頭前の通行量、入店率、来店顧客の属性など、カメラセンサーから取得できる定量データと顧客企業が保有する売上情報を組み合わせることで、より戦略的な意思決定をサポートします。
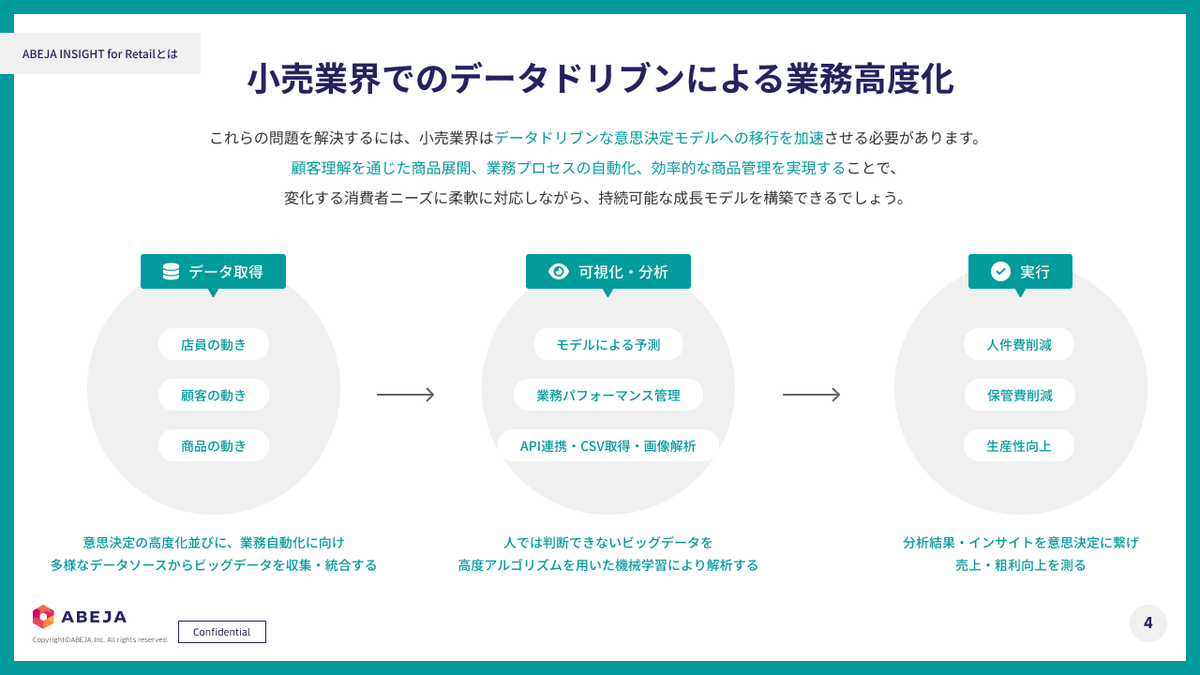
こうした仕組みにより、運営上の課題発見と改善施策の導出がよりスムーズになります。
サービスが抱える課題
一方で、「ABEJA Insight for Retail」の分析効果を最大限引き出すには、さまざまなデータの整合性を保つ必要があります。弊社提供のカメラを通じて集約できる来店人数や行動データはフォーマットが一定していますが、企業様が保有する売上データや予算データ、マーケティング施策の管理表などは、ExcelやCSVなど多様な形式で独自管理されています。
企業規模が大きく、多数の店舗を展開している場合、データ形式は千差万別です。それらを人手でテーブルフォーマットの統一化するのは大変な負担となり、導入から改善施策までのサイクルを遅らせる原因になります。 このような課題を解決し、クライアント企業が価値を即座に享受できるようにするためには、データ統合プロセスの自動化や変換処理の効率化が重要なポイントとなります。
ABEJA Platformは、「ABEJA LLM Series」など最先端技術を統合したアプリケーション群です。先述の課題に対して 、ABEJA Platform上に搭載された Agent を活用した解決ができないか検討しました。
Agent によるテーブルフォーマットの統一化を試みる
今回想定したアウトプットと利用するデータ
「ABEJA Insight for Retail」では、分析時に週次のデータをベースに解析を行います。ですので今回下記のようにフォーマットの統一化することを想定しました。
| 店舗名 | 年月 | 週 | 売上 | 購入件数 | 客単価 | 平均商品単価 | 平均買上点数 |
|---|---|---|---|---|---|---|---|
| 店舗A | 2024/12 | 第1週 | XXX | XXX | XXX | XXX | XXX |
| 店舗A | 2024/12 | 第2週 | XXX | XXX | XXX | XXX | XXX |
| 店舗B | 2024/12 | 第1週 | XXX | XXX | XXX | XXX | XXX |
| 店舗B | 2024/12 | 第2週 | XXX | XXX | XXX | XXX | XXX |
そして、今回2つのデータに対して、上記情報の抽出を行うことにしました。こちらは実際の企業様からいただくパターンで多いデータのケースを元に作成しています。
館別・ブランド別に、月次で「売上金額」「客数」「平均商品単価」「平均買上点数」といった指標で管理されている場合
基本的な1行が「特定日付における、特定店舗、特定アイテム(品番単位)の売上明細」である場合
実際に取り組んでみる
今回、こちらの問題に取り掛かるにあたり、以下のようなフローを想定しました。
- 初期分析: Agent が与えられた生データを読み込み、フォーマットの統一化するための初期ロジックを提示する。
- 人間によるレビュー: 人間がその提案ロジックを確認し、修正点(例えば、特定列の除外、期間計算方法の変更、指標計算ロジックの微調整など)を指示する。
- Agent による反映: Agent が指示内容を踏まえて再度コードを生成する。
- 結果確認: 生成されたコードをその場で実行し、結果を確認する。
- 人間によるレビュー: 必要なら再度人間が介入し、さらなる修正や確認を行う。
人間が介在しないケースでの処理も試みましたが、制度上の限界があり、人によるレビューを加えました。うまくいかなかった点については、「結論」の章で後述します。
加えて、コード品質を向上させる取り組みとして、エラー処理と再試行の仕組みを導入しています。例えば、以下のような対応を行いました。
- LangChainの
OutputParserクラスを用いて、CodeBlockOutputParserを定義している。 - LLMが生成したコードの実行時にエラーが発生した場合、LLMによる再帰的な修正処理を実装し、人間の工数を可能な限り削減する。
以下にコードを示します。
src/pos_analyzer.py
import logging import pandas as pd from langchain_core.prompts import ChatPromptTemplate from langchain_core.output_parsers import StrOutputParser from langchain_openai import AzureOpenAI class POSAnalyzer: def __init__(self, logger: logging.Logger, llm: AzureOpenAI, df: pd.DataFrame, system_message: str | None = None): if system_message is None: system_message = """ あなたはPOSデータ分析とデータフォーマットの統一化に関する熟練のデータエンジニアです。 ### 目的 ユーザーはPOSデータ(DataFrame形式)を週次×店舗単位でフォーマットの統一化し、以下のような形のテーブルを得たいと考えています。 ``` | 店舗名 | 年月 | 週 | 売上 | 購入件数 | 客単価 | 平均商品単価 | 平均買上点数 | |-|-|-|-|-|-|-|-| | 店舗A | 2024/12 | 第1週 | XXX | XXX | XXX | XXX | XXX | | 店舗A | 2024/12 | 第2週 | XXX | XXX | XXX | XXX | XXX | | 店舗B | 2024/12 | 第1週 | XXX | XXX | XXX | XXX | XXX | | 店舗B | 2024/12 | 第2週 | XXX | XXX | XXX | XXX | XXX | ``` - 店舗名: 小売店舗の名称 - 年月: データの対象期間となる年月 - 週: 月内の週次区分 - 売上: 対象期間における総売上金額 - 購入件数: 対象期間における取引 - 客単価: 1取引あたりの平均売上金額 - 平均商品単価: 販売された商品1点あたりの平均価格 - 平均買上点数: 1取引あたりの平均購入商品数 ### あなたに求められること - 入力として与えられるPOSデータ(df_markdownなどの形で提示される)を、上記のフォーマット統一化テーブルへ変換するための具体的で実行可能な「プロセス」を説明してください。 - プロセスは以下を明確に示すこと: 1. 元データの粒度や列構造を踏まえた、集計の前提条件(返品データや顧客属性の扱いなど) 2. 日付からの週次区分方法(第1週、第2週などの定義) 3. 店舗名・年月・週をキーとしたグルーピングと、売上や購入件数などの基本指標の合計・算出方法 4. 客単価・平均商品単価・平均買上点数などの派生KPIの定義と計算ロジック 5. フォーマット統一化テーブルに整形するまでのステップ(データ整形、マッピング、欠損処理、返品処理など) - 不明点があれば仮定を述べた上で進めること。 - Human-in-the-Loopを前提とし、人間からのフィードバックがあれば、その指示に従いプロセスを柔軟に再提案・改善してください。 ### 留意事項 - あなたが生成したコードは、`exec(code_str, global_vars, local_vars)` で実行されます。 - `global_vars = {{"pd": pd}}`, `local_vars = {{"df": self.df}}` が定義されていることを留意してください。 - 再実行(rerun)が行われ、追加のフィードバックが与えられた場合、その指示に応じたプロセス修正を行ってください。 """ self.logger = logger self.llm = llm self.df = df self.df_markdown = df.to_markdown() self.messages = [ ("system", system_message), ("user", f"以下は今回分析するPOSデータです。解析方針を提案してください。\n\n{self.df_markdown}") ] def run(self, human_feedback: str | None = None): if len(self.messages) > 2 and human_feedback: escaped_feedback = self._escape_markdown(human_feedback) self.messages.append(("user", f"【フィードバック】\n{escaped_feedback}")) elif len(self.messages) <= 2 and human_feedback: self.logger.warning("Feedback provided on first run will be ignored") prompt = ChatPromptTemplate.from_messages(self.messages) chain = prompt | self.llm | StrOutputParser() result = chain.invoke({}) self.messages.append(("ai", self._escape_markdown(result))) return result def _escape_markdown(self, text: str) -> str: return text.replace("{", "{{").replace("}", "}}")
src/pos_formatter.py
import logging import traceback import pandas as pd from langchain_core.prompts import ChatPromptTemplate from langchain_openai import AzureOpenAI from .output_perser import CodeBlockOutputParser class POSFormatter: def __init__(self, logger: logging.Logger, llm: AzureOpenAI, df: pd.DataFrame, system_message: str | None = None): self.logger = logger self.df = df self.df_markdown = df.to_markdown() self.parser = CodeBlockOutputParser() if system_message is None: system_message = """ あなたはPOSデータフォーマットの統一化処理を行うエンジニアです。 以下の要件に従ってDataFrameのフォーマット統一化コードを生成してください: ### 必須要件 1. 必ず df_final という名前のDataFrameを生成すること 2. df_final は以下の列を含むこと: - 店舗名: 小売店舗の名称 - 年月: データの対象期間となる年月 - 週: 月内の週次区分 - 売上: 対象期間における総売上金額 - 購入件数: 対象期間における取引 - 客単価: 1取引あたりの平均売上金額 - 平均商品単価: 販売された商品1点あたりの平均価格 - 平均買上点数: 1取引あたりの平均購入商品数 ### エラー発生時の対応 - 列名が存在しない場合: 仮の列名でダミー計算を行い、コメントで明記 - グルーピング不足: キーの過不足を確認 - 計算エラー: 0除算などを考慮した安全な計算処理 ### 留意事項 - あなたが生成したコードは、`exec(code_str, global_vars, local_vars)` で実行されます。 - `global_vars = {{"pd": pd}}`, `local_vars = {{"df": self.df}}` が定義されていることを留意してください。 - 再実行(rerun)が行われ、追加のフィードバックが与えられた場合、その指示に応じたプロセス修正を行ってください。 """ + f""" ### 現在のDataFrame構造: {self.df_markdown} ### コード生成規則 {self.parser.get_format_instructions()} """ self.llm = llm self.messages = [("system", system_message)] def run(self, result: str | None = None, human_feedback: str | None = None, max_retries: int = 3) -> pd.DataFrame: if not (bool(result) ^ bool(human_feedback)): # XOR check raise ValueError("Exactly one of 'result' or 'human_feedback' must be provided") if result is not None: escaped_result = self._escape_markdown(result) self.messages.append(("user", f"下記分析結果を参考に、DataFrameのフォーマットを統一化するコードを提示してください。\n{escaped_result}")) if human_feedback is not None: if len(self.messages) <= 2: raise ValueError("Feedback is not required for the first run.") escaped_feedback = self._escape_markdown(human_feedback) self.messages.append(("user", f"下記フィードバックを参考に、元のコードを修正してください。\n{escaped_feedback}")) prompt = ChatPromptTemplate.from_messages(self.messages) chain = prompt | self.llm | CodeBlockOutputParser() code_str = chain.invoke({}) self.messages.append(("ai", self._escape_markdown(code_str))) retries = 0 last_error = None while retries < max_retries: try: global_vars = {"pd": pd} local_vars = {"df": self.df} exec(code_str, global_vars, local_vars) if "df_final" not in local_vars: raise RuntimeError("df_final not found in generated code output") df_final = local_vars["df_final"] if not isinstance(df_final, pd.DataFrame): raise RuntimeError("df_final must be a pandas DataFrame") required_columns = ["店舗名", "年月", "週", "売上", "購入件数", "客単価", "平均商品単価", "平均買上点数"] missing_cols = [col for col in required_columns if col not in df_final.columns] if missing_cols: raise RuntimeError(f"Missing required columns: {missing_cols}") return df_final except Exception as e: last_error = e error_message = ( f"Error executing code: {str(e)}\n" f"Traceback:\n{self._escape_markdown(traceback.format_exc())}\n" "Please fix the code and ensure df_final is properly created." ) self.messages.append(("user", error_message)) if retries == max_retries - 1: raise RuntimeError(f"Failed after {max_retries} attempts. Last error: {last_error}") prompt = ChatPromptTemplate.from_messages(self.messages) chain = prompt | self.llm | CodeBlockOutputParser() code_str = chain.invoke({}) self.messages.append(("ai", self._escape_markdown(code_str))) retries += 1 def _escape_markdown(self, text: str) -> str: return text.replace("{", "{{").replace("}", "}}")
src/output_perser.py
import re from langchain_core.output_parsers.base import BaseOutputParser class CodeBlockOutputParser(BaseOutputParser[str]): """LLMからの出力テキスト中に含まれるコードブロック(``` で囲まれた部分)を抽出するパーサー.""" pattern: str = r"```(?:[A-Za-z0-9_+\-\.:\/]*\n)?(.*?)```" def get_format_instructions(self) -> str: return ( "Your response should be a code block with each item on a new line. " "For example: \n\n```python\nprint('Hello, World!')\n```" ) def parse(self, text: str) -> str: """テキスト中の最初のコードブロックを抽出して返す。 Returns: 抽出したコードブロックの文字列。コードブロックが見つからなかった場合は空文字列を返すか、もしくは例外を発生させる。 """ match = re.search(self.pattern, text, flags=re.DOTALL) if match: code = match.group(1).strip() lines = code.splitlines() # 最初と最後の空行を除去 while lines and not lines[0].strip(): lines = lines[1:] while lines and not lines[-1].strip(): lines = lines[:-1] return '\n'.join(lines) else: raise ValueError("No code block found in the given text.") @property def _type(self) -> str: return "code_block_output_parser"
結果
結論
用意した CSV ファイルにおいては 成功 しました。下記に実際のログを示します。
実際に検証してみたログ
こちらでは、月次データしか含まれていないことをはじめの分析で言及しています。今回はそちらを週次で処理する旨を伝えています。 また、NaNのデータも表を読み取り正しく処理しています。
for index, row in df.iterrows(): if not pd.isna(row['館']): current_store = row['館'] if not pd.isna(row['ブランド']): current_brand = row['ブランド']
こちらでは、フィードバッグを行わずに改修が可能でした。こちらのデータではすぐにLLMが一列が一商品だと把握し、売上数が負の場合もよしなに処理をしてくれています。
残った課題
CSV の LLM によるフォーマットの統一化がうまく行えた一方で一部課題も残りました。
人によるレビューの必要性
出力結果にはレビューが必要な場面が多く見られました。例えば、週次で集計すべき情報であるにもかかわらず、月次のデータしか含まれていないケースがあり、要件を満たしていないことがありました。 また、売上データの単位が「XXX千円」と記載されていることが多く、この判断は人間が行う必要がありました。プロンプトエンジニアリングを改善すれば、レビューを大幅に省略できる可能性があると考えられます。
複雑なExcelへの対応
今回利用したデータは、表形式で成形されたものをベースに変換しました。しかし、企業によってはExcelシートが必ずしも表形式で整えられていないケースも多く存在します。例えば:
- セル結合内に説明が記載され、その下に表が配置されている
- シート内に画像が含まれている
こういった複雑なケースに対応するには高度な工夫が求められますが、今回はこれを考慮していません。表形式で整理されていない場合、より「職人芸」とも言える設計が必要になりそうです。
非エンジニアによる対応の可能性
データ処理の成否を非エンジニアが判断しやすい仕組みは整備できていませんでした。CLIによる処理が中心だったため、レビューしやすいビューの提供など、改善の余地があります。
まとめ
今回は、LLMが生成したコードを用いてCSVをエクスポートする関数を作成しました。単純な表形式であれば、高精度で変換できることを確認しました。複雑な表に対しても変換が可能になると魅力的ですが、その実現にはより高度な実装が必要そうです。
We Are Hiring!
ABEJAは、テクノロジーの社会実装に取り組んでいます。 技術はもちろん、技術をどのようにして社会やビジネスに組み込んでいくかを考えるのが好きな方は、下記採用ページからエントリーください! (新卒の方やインターンシップのエントリーもお待ちしております!)
特に下記ポジションの募集を強化しています!ぜひ御覧ください!
プラットフォームグループ:シニアソフトウェアエンジニア | 株式会社ABEJA
