
- 1. はじめに
- 2. 先行研究からの学び
- 3. 前提
- 4. アーキテクチャ変更候補
- 5. 小規模モデルでの実験
- 6. 中規模モデルでの実験
- 7. 13Bパラメーターへの適用
- 8. まとめ
- 9. 最後に
1. はじめに
こんにちは、ABEJAの服部です。GPTブログの第三弾ということでモデルのアーキテクチャの工夫についてお話したいと思います。 こちらは、弊社データサイエンティストAnujさんが書いた英語記事をベースに一部追記・改変をした日本語版になります。
先日のブログ投稿のとおり、ABEJAでは最大130億パラメータを持つ独自のGPTモデルに日本語の言語コーパスを学習させました。
第一弾(取り組み全体の話)
第二弾(並列分散学習の話)
モデルアーキテクチャの工夫英文記事
2. 先行研究からの学び
GPTのモデル自体は最初のリリース当初(2018年頃)からGPT-3を経てもモデルのアーキテクチャは変わっていません。 ただ当時から時間も経っており、その間にもモデルの学習における工夫点などの研究において進展もあったはずです。 その努力を無駄にせず活用するためにも、大規模言語モデル(LLM)の学習で開発されたベストプラクティスに従うことにしました。
GoogleのPaLMに試行錯誤のための改善策案がまとまっています。それらの変更を試みた結果を中心に今回の記事ではまとめてご紹介します。
注:パフォーマンスの向上に関する実験結果については、ハードウェア構成や実装方法などの要因に依存する可能性があります。この記事に出てくる実験結果・分析は定性的なものであることにご注意ください。
3. 前提
本記事は、下記について基本的な理解がある読者を想定しています。
- GPTのようなTransformerモデル
- Positional Encoding
- 活性化関数
4. アーキテクチャ変更候補
既存のコードベースに以下のPaLMの提案を適用し、結果を比較しました。
- 活性化関数の変更 (SwishGLU)
- Transformer layerの並列化
- biasパラメータ除去
- Input-Output Embeddingの共有(Weight tying)
活性化関数の変更 (SwishGLU)
Transformer層におけるMLPの中間活性化として、GeLUの代わりにSwishGLU を使用します。
PaLMの論文の中でも言及されていますが、下記にて標準のReLU, GeLU, Swishと比較して品質を向上させることが示されています。
Transformer layerの並列化
元々のTransformer層では
attn = Attention layer, ln = layer normとしたとき
x = x + attn(ln1(x))
のあとに
x = x + MLP(ln2(x))
と直列で実施しています。
これを代わりに「並列」で実行します。
x = x + attn(ln1(x)) + MLP(ln2(x))
MLP(ln2(x)) における xがattention層を通る前のxに変わります。
PaLMの論文によると、約15%の高速化がされるようです。(精度向上というより高速化が目的)
biasパラメータ除去
こちらは先行研究というよりPaLMの中で提案されているものになります。 (内容としてもシンプルなため割愛します)
Input-Output Embeddingの共有 (Weight tying)
Transformer以前からも言語モデルで時々使われている手法で、単語埋め込みの重み行列を入力層と出力層で共有するというものです。
PaLM論文内に参考文献は見つけられなかったですが、おそらくこちらの論文などで言及されているものかと思います。
5. 小規模モデルでの実験
実験コストを考慮し、まずは14Bトークンのテキストコーパスで小規模なGPTモデル からとりかかりました。
実験設定
num-layers: 12 hidden-size: 768 num-attention-heads: 12 seq-length: 2048 max-position-embeddings: 2048 norm: "layernorm" pos-emb: "rotary" no-weight-tying: true
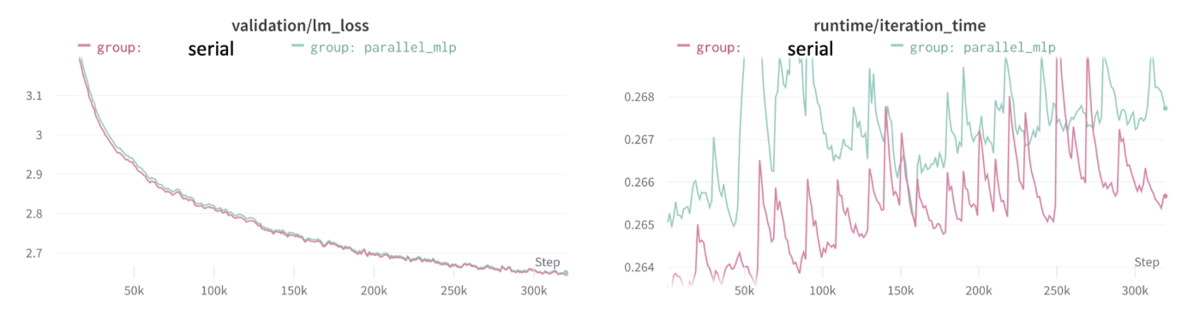
Transformer layerの並列化
左側がvalidation lossで、右側がiterationごとにかかる時間です。 そして赤色の線が従来のtransformer layerで、緑色が並列化したものです。
残念ながら、学習速度が遅くなり、lossも少し悪化してしまいました。
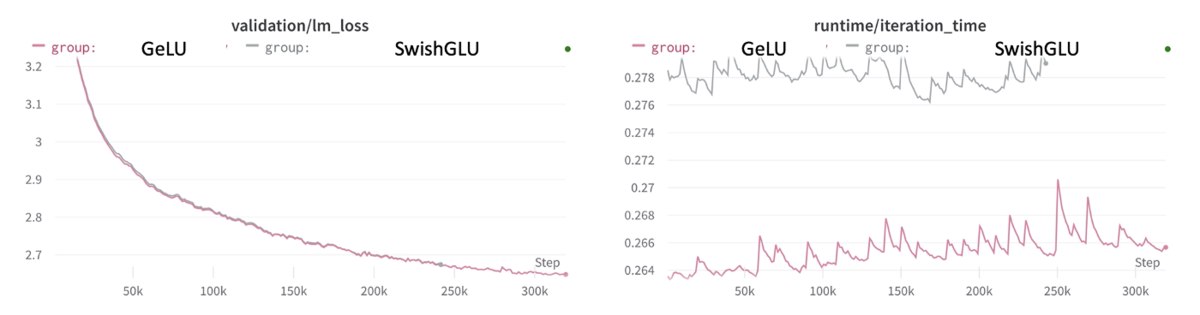
SwishGLUの適用
1つ前と同様に、左側がvalidation lossで、右側がiterationごとにかかる時間です。
SwishGLUの学習の方が時間がかかり、パフォーマンスの大幅向上もみられませんでした。
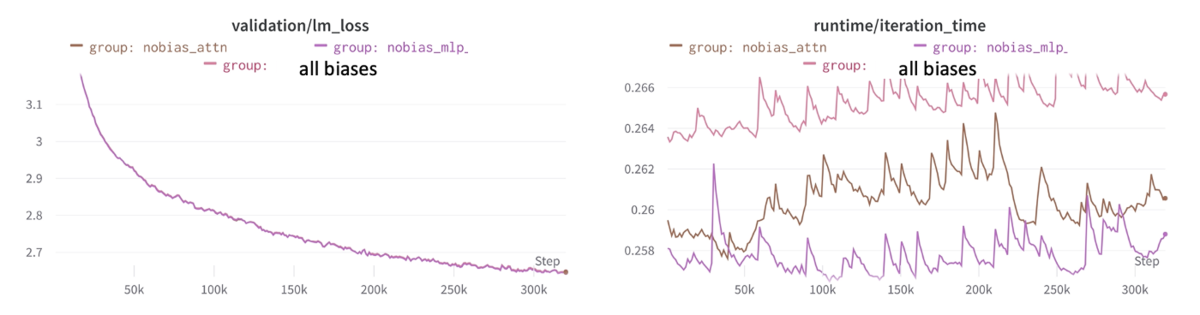
Bias parameterの除去
bias削除の実験
以下3つでの比較を行いました。 - Projection Layerからバイアスを削除したもの(nobias_attn) - 中間のMLP層からバイアスを削除したもの(no_bias_mlp) - すべてのバイアスを保持
「no_bias_mlp」は学習速度は最速でした。 パフォーマンスとしては、(グラフ上からは違いが分かりませんが)「no_bias_mlp」 > 「nobias_attn」>「すべてのバイアスを保持」の順でした。
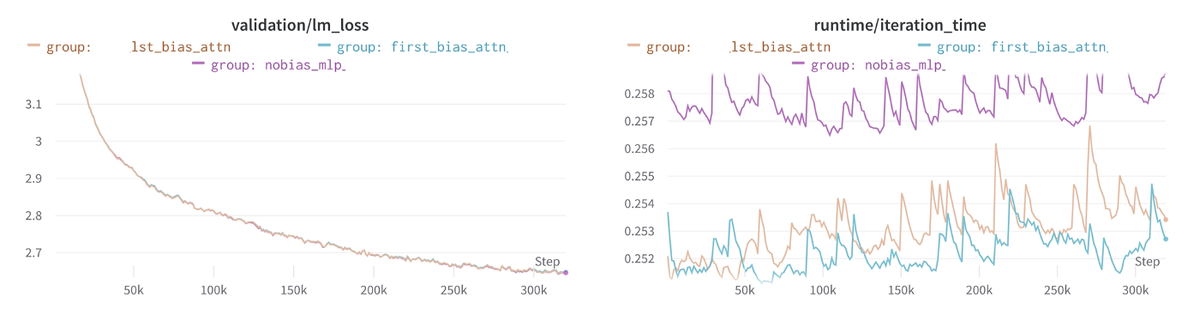
最初もしくは最後のbiasだけを残す
全てバイアスを取り除いてしまうと、学習が不安定になることに繋がります。これを克服するため、アーキテクチャの各セクションからバイアスを徐々に取り除くという、さらなる実験を行いました。最終的に、すべての中間MLPと、Attentionブロックの最後を除く全てのprojection layerからバイアスパラメーターを削除する方法で、最適なモデル(速度と検証性能)が実現されました。
水色が最初のみにbiasをつけたもの、茶色が最後のみにbiasをつけたもの、紫がbiasなしのものになります。
Input-Output Embeddingの共有 (Weight tying)
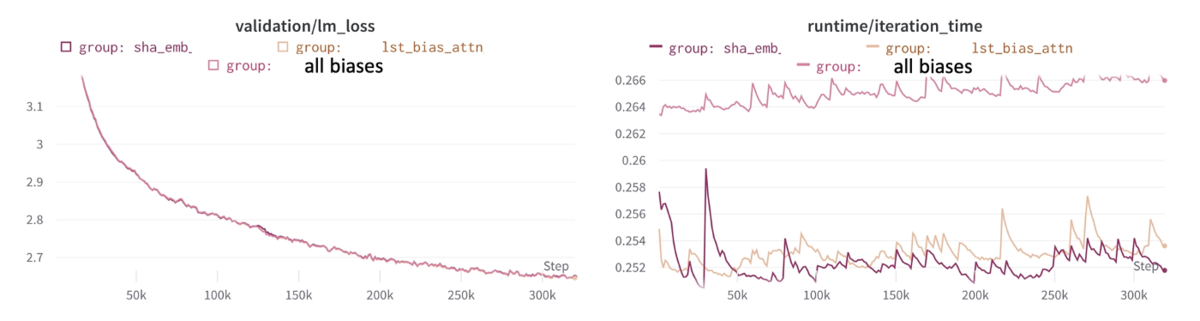
こちらは以下3つに比較です。
- 全バイアス(All_biases)
- 最後の投影層のみにバイアスパラメーター(lst_bias_attn)
- 「lst_bias_attn」にShared Input-output embeddings(weight tying)を適用したもの(sha_emb)
Weight Tyingはパフォーマンスの向上を期待しましたが、あまり効果が得られませんでした。 これは実験時のモデルのサイズがとても小さかった事が原因である可能性があります。
6. 中規模モデルでの実験
ここまでの実験をベースに、以降の実験は、最後のprojection layerにのみバイアスパラメータを持つモデルアーキテクチャをベースラインとする、さらに大きなモデル(中)で行いました。
上記で述べたベースラインモデルから学んだ事をふまえ、より大きなモデル(パラメータ約3倍、テキストコーパス約3倍)に移行しパフォーマンスを比較しました。
実験設定
num-layers: 24 hidden-size: 1024 num-attention-heads: 16 seq-length: 2048 max-position-embeddings: 2048 norm: "layernorm" pos-emb: "rotary" no-weight-tying: true
モデルサイズでの比較
まずは最初に行った実験と、新たにパラメータサイズを大きくしたモデルでの性能を比較しました。
パラメータサイズを大きくしたときのほう(緑色)が、lossの下がり方が顕著にパフォーマンスが良いことが分かります。
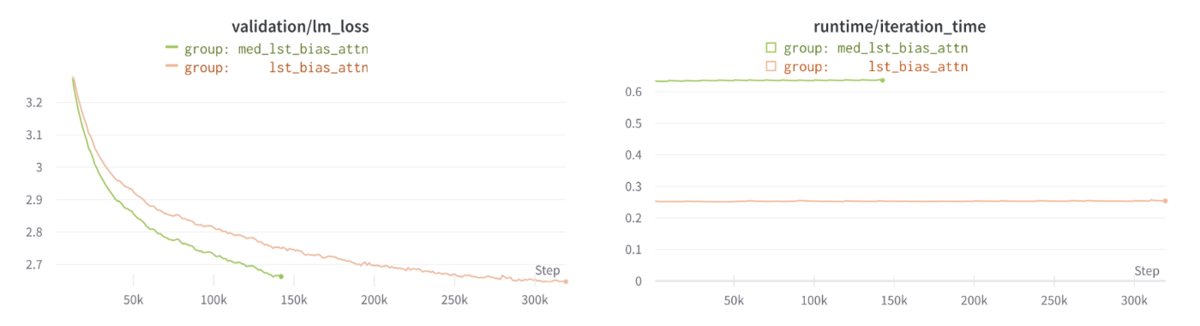
Shared Input output embeddings (weight tying)
小規模モデルでは効果があまり見られなかったWeight Tying(InputとOutputの単語埋め込みの共有)ですが、こちらでは学習速度、lossの下がり方ともにパフォーマンスの向上が見られました。
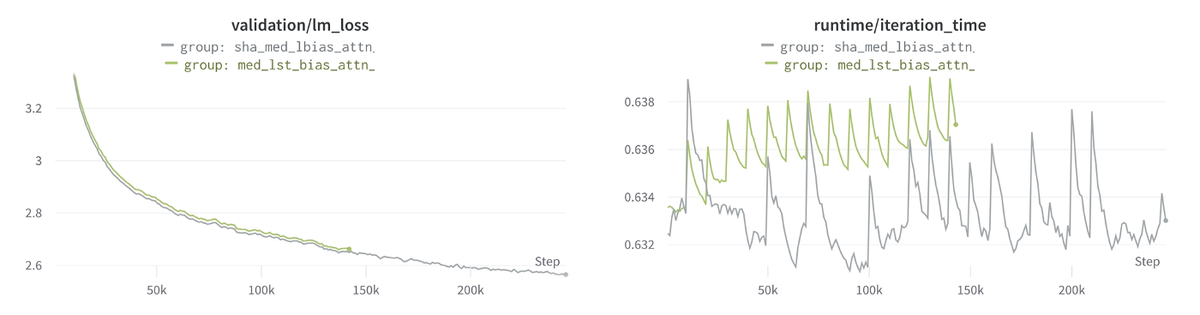
Transformer layerの並列化
小規模モデルでの結果と同じく、Transformer layerでの並列化は、学習速度が遅くなり、lossも悪化してしまいました。
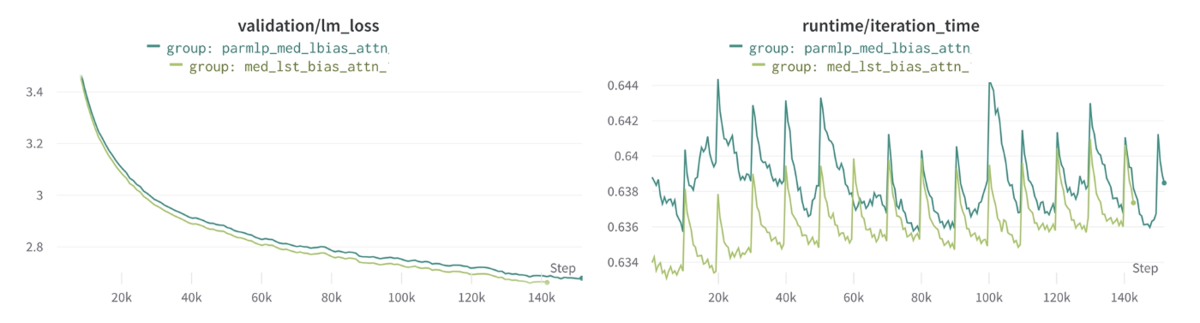
SwishGLUの適用
小規模モデルの結果と同じく、lossのパフォーマンス向上はなく、学習速度だけ遅くなりました。
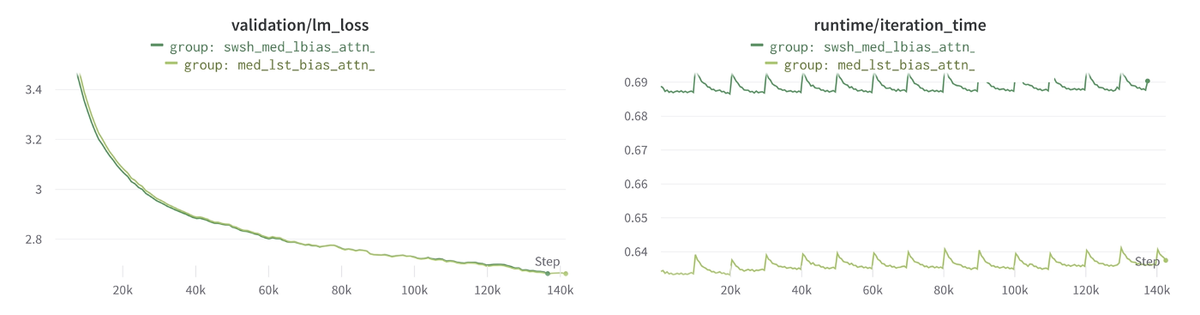
7. 13Bパラメーターへの適用
ここまでの実験まとめ
ここまでの実験、特に精度面での結果を簡単にまとめると以下のようになります。
| 工夫 | 小規模 | 中規模 |
|---|---|---|
| 活性化関数(SwishGLU)の適用 | x | x |
| biasパラメータ除去 | ○ | ○ |
| Transformer Layerの並列化 | x | x |
| Weight Tying(Input-Output Embeddingの共有) | △ | ○ |
今までの実験の中で効果のありそうなものは
- Biasパラメータ除去
- Weight Tying
の2つです。
これら2つについて、最終的に学習させたい大規模モデルに適用させました。
Dropout追加
上記実験に合わせて、Metaから出たopt-175bの研究にならって、Attention層にdropout: 0.1 (dropoutさせる確率)を実装することにしました。
結果的に元々のモデルで発生したlossの発散が起きず、パフォーマンスの向上及び全体的に学習が安定するようになりました。 (赤が元々のモデル、紫がdropout適用版)
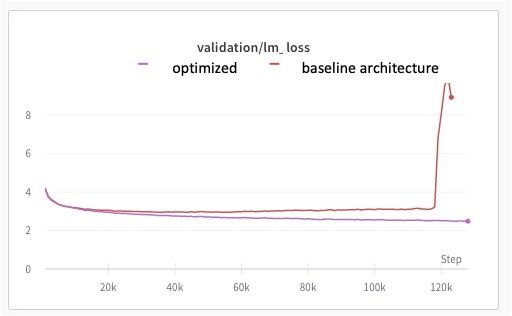
ただし、学習速度は全体的に遅くなっています。
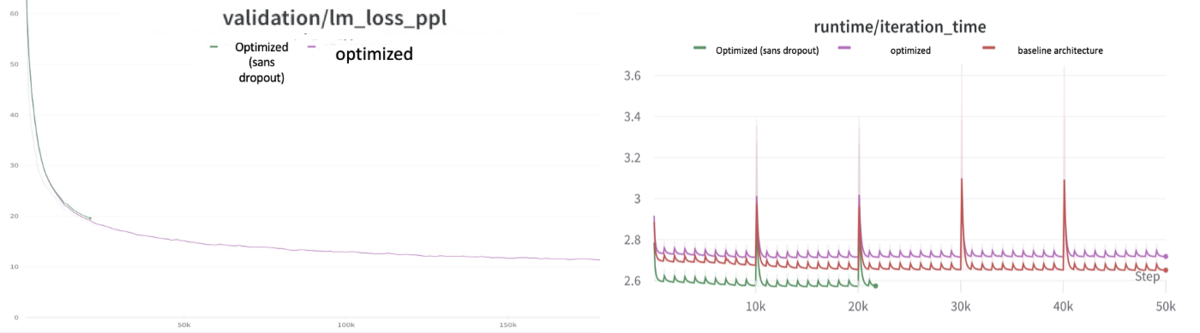
Dropoutを追加することで学習時間は伸びますが、それ以上にパフォーマンスの向上が見られるのと、時間が伸びるのは学習時のみで推論時には影響がないので取り入れることにしました。
8. まとめ
今回はPaLMを中心に、大規模言語モデルの最新の研究で取り入れられているモデルアーキテクチャの工夫を実際に実験しながら、我々のGPTモデルに取り入れる過程をご紹介しました。
最終的には以下3つを取り入れています。
- biasパラメータ除去
- Weight Tying
- dropout 0.1
そして、実際にこれのおかげで学習が成功した部分もあります。
また、こういった実験を自分たちの思いつきでやると多大なる計算コストがかかるので、こういった先行研究を元に試すことで効率よくモデルの改善が出来ることは大事であり、先行研究に感謝です。
9. 最後に
ABEJAでは幅広い業界のプロジェクトを扱っており、様々なデータに触れられます。ABEJAは画像系のイメージを持っている方も多いかもしれませんが、自然言語処理の分野にも取り組んでいます。お客様からの要望に従って分析・モデル構築するだけではなく、ゼロから解決策を検討・提案・実行できるところが、難しくもあり面白い所でもあります。幅広いだけでなく、深い知識も得られるよう、ナレッジシェアなどにも力を入れています。ちょっと話を聞いてみたい、もう少し詳しく知りたいなどありましたら、是非ともご連絡ください。 DSチーム、HRメンバー共々心よりお待ちしております。
