こんにちは。システム開発グループでエンジニアをやっている鈴木です。
本記事はABEJAアドベントカレンダー2022の4日目の記事です!
タイトルだけ見ると、なんのこっちゃって感じですが、本記事は真面目な書き方をするとデータサイエンティストとの協業がテーマになります。
社外向けイベントでも紹介させていただいたのですが、今回は技術に突っ込んだ部分も含めてお話しします。
目次
転生したらデータサイエンスの国でクッキーの型職人になっていた
エンジニアリングの国で働く
転生前は所謂SIerで働いていました。
SIがメインのお仕事でしたが、晩年は自社でSaaSビジネスを進めるためのプロダクト開発みたいなことをやってました。
機械学習系の案件に携わることもあり、機械学習エンジニア的な動きをすることもありました。
それが高じてプライベートでもKaggleのコンペにも参加するようにもなり、Expertを取れるくらいにはなりました。
ABEJAにはつよつよなMasterが複数名在籍しており、中にはKaggle Days Championshipで優勝しちゃう人もいるので「Kaggleできます!」とは口が裂けても言えませんが笑
tech-blog.abeja.asia
ABEJAには今年の2月に転生をしており、現在はシステム開発グループ(エンジニアリングの国)でソフトウェアエンジニアをやっています。(生後10ヶ月)
神様からチートスキルはもらえませんでしたが、転生前の知識や経験を活かして、フロント・バックエンド、インフラ構築などフルスタックに働いています。
システム開発グループでの働き方は以下の資料に詳しく書いています。
speakerdeck.com tech-blog.abeja.asia
データサイエンスの国でも働く
この世界にはエンジニアリングの国の他にプロジェクトマネージメント、データサイエンスなどの国があり、"ゆたかな世界を、実装する"ために手を取り合って暮らしています。
私のメインロールはエンジニアではありますが、データサイエンスへの関心が強かったことで、エンジニアリングの国の王から「データサイエンスの国でクッキーの型を創る仕事をやらないか(超意訳)」と勅命をいただくことになったのです。
"クッキーの型を創る仕事"が何か説明する前にデータサイエンスの国と働くときの仕事内容についてお話しいたします。
データサイエンティストとの協業では構築したモデルを組み込む業務があり、以下のようなことをコミュニケーションを取りながら進めていきます。
- アプリへのインテグレーション
- データパイプラインの構築
- モデルデプロイ環境の構築
データサイエンスの国の方々の働き方は以下の記事をご覧いただければと思います。
課題
モデルを組み込んでいく業務ではコードのディレクトリ構成やI/Fをインテグレーション用に変更することがあり、一定のコストがかかっているという課題があります。
データサイエンティスト、エンジニア共に常にコードの品質には気を使ってはいるものの、プロジェクトのフェーズごとにフォーカスする価値観が異なることが関連しています。
モデル開発
モデル開発に注力するフェーズでは以下のような要素が実験ごとに変わることがあります。
- 取り込むデータの仕様
- 前処理の方法
- 使用する機械学習モデルやフレームワーク
ビジネス課題を解決する価値のコアとなる部分を限られた期間で創り上げていくため、仮説 -> 検証のサイクルをお客さまといかに早く回せるかが重要になってきます。
インテグレーション
インテグレーションのフェーズでは取り決められたデータの仕様に沿って、品質の高いシステムを構築することが求められます。
将来への変更容易性も考慮しつつ、システムアーキテクチャに対して制約を課すことでこの品質を高めていくことになります。
クッキーの型を創る仕事
このような背景からプロジェクト全体の生産性を最適化するには自由な試行錯誤と型にはめたモデル開発をバランス良く進められる仕組みを整えていくことが大事だと考えます。
この2つは二律背反ではないものの、バランスをとることが難しい項目でもあります。
この課題を解決する狙いで進めている取り組みが"クッキーの型を創る仕事"、モデル開発テンプレートになります。
モデル開発テンプレート
モデル開発テンプレートとはモデル開発が生じるプロジェクトで共通化しておける機能をテンプレート化する取り組みになります。
これを配布・利用し、個別プロジェクトの工数を削減しようという狙いがあります。
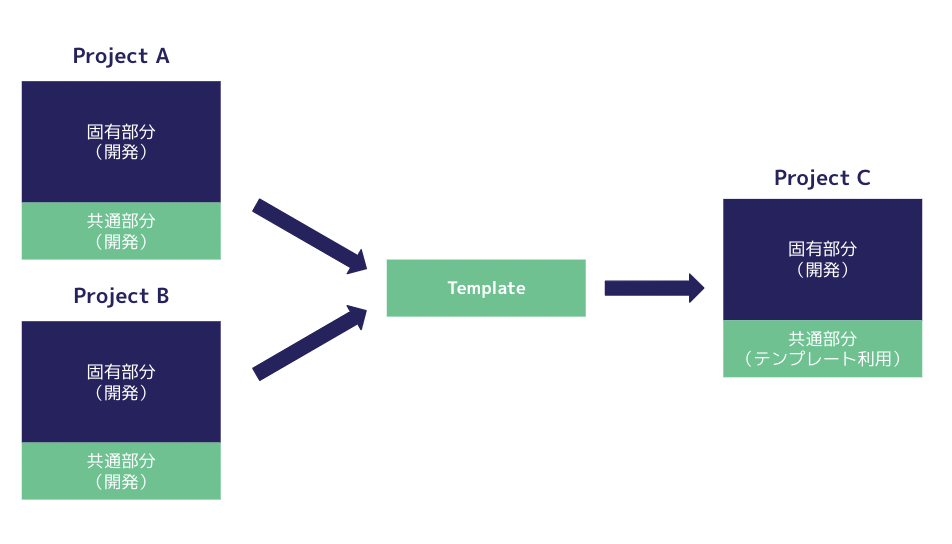 テンプレート配布にはCookiecutterというOSSを利用しています。
テンプレート配布にはCookiecutterというOSSを利用しています。
Cookiecutter
日本語で言うとクッキー型(タイトル回収)ですが、テンプレートからプロジェクトを作成してくれるCLIツールです。
github.com
予め作成しておいたクッキー型(テンプレート用のリポジトリ)を指定することで任意の構成でプロジェクトを初期化でき、開発時のイニシャルコストを軽減できます。
類似したコンテキストで進めるプロジェクトが多い、組織や取り組みと相性が良く、個人的にはKaggleのコンペ用などでオレオレ構成を使い回したりするのにも使えそうだなと思います。
Pythonのライブラリですが、それ以外の言語でもテンプレートを作れます。
GitHubでcookiecutter-templateのTopicで検索をかけると色々な方が作成したテンプレートを確認できます。
テンプレート導入の利点
モデル開発テンプレート導入の利点は大きく分けて2つあります。
開発工数の削減
主に環境構築、プロジェクト構成検討、過去のプロジェクトで利用した機能の実装工数あたりが削減でき、利用者はモデル開発周りの作業に注力しやすくなります。
全社的な取り組みの展開のしやすさ
組織単位で実施したい開発系の方針などをテンプレート経由で展開することで、プロジェクト個別での対応負荷を減らしたり、方針展開のスピードを早めることができます。
弊社ではABEJA Platformと呼ばれる統合ML基盤を使ってのデリバリーも多いので、プラットフォーム関連の施策とも相性が良いなと運用し始めてから気づきました。
提供機能
プロジェクト作成時のディレクトリ構成は以下の通りになっています。

環境構築周り
プロジェクト開始時のイニシャルコストを削減するため、以下をテンプレートから提供し、環境構築周りを簡略化しています。
- linter、formatterを含む、必要最低限のライブラリのインストール
- CIの設定(PR作成時にGithub Actionsでlint、testを実行)
- ABEJA Platformで動作させるためのDockerfile
データ関連のユーティリティ
モデル開発案件では様々なプラットフォームにデータを置くことが起こります。
こうしたデータ周りの定型作業の支援ツールや共通のI/Fでデータ取得するモジュールを提供しています。
パッチ機能
テンプレート配布の性質上、機能のアップデートを作成済のプロジェクトに取り込みづらいという課題があります。
モデル開発テンプレートでは変更を後付けでも取り込めるようパッチを充てる機能を提供しています。
重要な機能のリリース時にはパッチを充ててもらうようにアナウンスし、各プロジェクトで取り込んでもらう運用にしています。
サンプルコードの配布
ABEJAのプロジェクトではテーブルデータ、CV、NLP、時系列など、さまざまな形式のデータを取り扱います。
そういった状況で試しに実行できるサンプルコードをプロジェクト作成時にダウンロードできます。
CookiecutterにはPre/Post-Generate Hooksというプロジェクト作成前後でスクリプトを実行する機能があります。
モデル開発テンプレートではこの機能を使い、プロジェクト作成時のプロンプトの選択内容に応じて必要なサンプルコードを構成に含めるようにしています。
DS Codebookとのコラボレーション
データサイエンスグループの取り組みの一つにDS Codebookというものがあります。
デリバリー完了後のコードをクリーンかつ再現可能な状態で蓄積する取り組みなのですが、DS Codebookへの登録を簡略化する機能を提供しています。
DS Codebookの詳細は以下の記事で紹介しています。
tech-blog.abeja.asia
運用
多くのシステム開発と同様、一度作ればおしまいではなく、利用者(データサイエンスの国の人たち)の声を聞きながらメンテナンスすることが重要です。
データサイエンスの国の人たちと会話しながらモデル開発プロジェクトでのコンテキストを共有し、追加する機能や運用の方針を決めています。
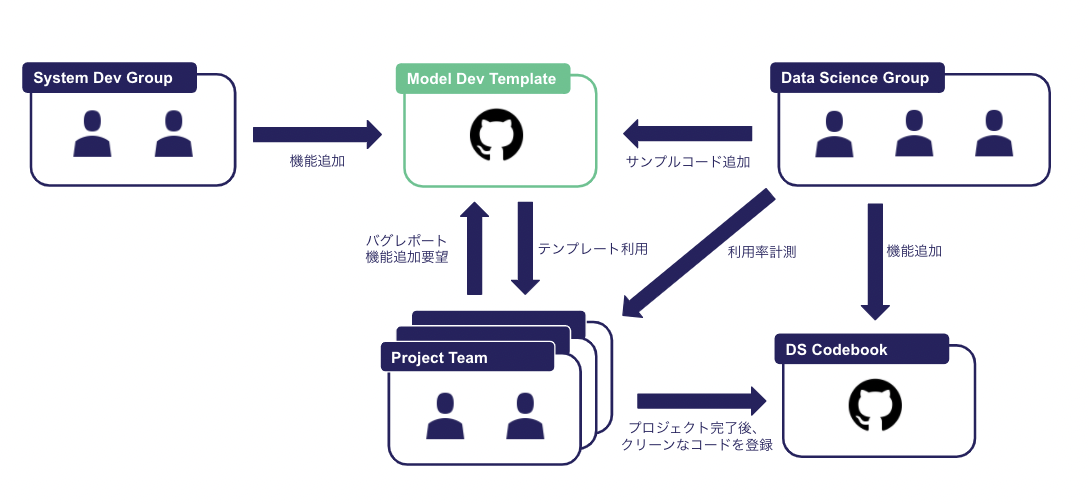
自由にやりすぎると取り組みの旨味が減ってしまいますが、ルールをガチガチに固めてしまうとプロジェクトごとに取り回しが効きづらくなるので、この辺のバランス感に気をつけながら今のABEJAにとってのベストを探っています。
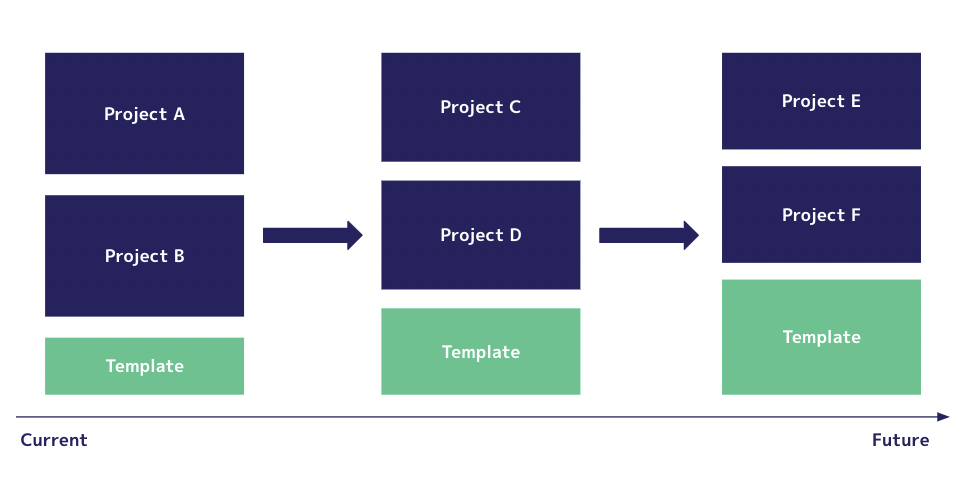
まずは最小限の機能の提供から始め、徐々に充実させていく方針で長く多くのプロジェクトで使われる取り組みになるよう試行錯誤しています!
We Are Hiring!
ABEJAでは一緒に働く仲間を募集しています!
幅広い技術を活用・習得したい、顧客・社内メンバーと協業しながら開発したい、このブログを読んで興味を持った方は是非こちらの採用ページからエントリーください!
