ABEJAでデータサイエンティストをしている服部です。
2022年10月28, 29日にバルセロナにてKaggle Days World Championship Finalというデータサイエンスに関するイベント兼コンペティションが開催され、そこに参加しました。そして幸いなことに私の所属するチームが優勝することができました!!
本記事では今回のイベントそのものと、優勝に至るまでのコンペ上での過程や工夫点などについてご紹介しようと思います。

- Kaggle Days World Championship Finalとは
- 1日目(ワークショップやプレゼンテーション等)
- 2日目(コンペティション当日)
- 最後に
Kaggle Days World Championship Finalとは
データサイエンス界隈には、機械学習モデルの精度を競い合うKaggleという世界最大のコンペティションプラットフォームが存在します。そしてそのKaggleとLogicAIによる運営でKaggle Days World Championshipというコンペティションイベントが昨年より行われていました。12回の予選それぞれの上位3チームが決勝に招待され、その決勝大会(Final)というのが今回になります。
予選には計5321人が参加し、決勝に残りFinalに参加したのは24チーム、77人でした。
本イベントはHP社がスポンサーであり、会場はHP社のバルセロナオフィスで行われました。

1日目(ワークショップやプレゼンテーション等)
初日はワークショップやプレゼンテーションが行われました。プレゼンテーションルームでは終日多くのプレゼンテーション発表があるのと同時に、希望者が参加できるワークショップやブレインストーミング、スポンサーイベント等が行われました。 以下では私が参加したものの一部について紹介したいと思います。
Opening remarks by LogicAI and Kaggle

Kaggle DaysのイベントはKaggleとLogicAIという2つの会社で運営されています。 最初にLogicAIのCEOとKaggleのCEOからの話がありました。
LogicAIのCEOであるMaria Parysz 氏からは、今回のイベントの予選から決勝に至るまでの話、イベント内容に関する共有がありました。
予選では5321人の参加者と1000以上のチームがあり、そこから選ばれたWinnerがここにいるということ、決勝ではコンペ自体も楽しみにしているし、Kaggler同士での交流を深めてほしいという旨の話もありました。
KaggleのCEOである D.Sculley氏は今年KaggleのCEOに就任したところであり、初めて話を聞きました。元々Google Brainでディレクターをしていたようです。データサイエンスの研究分野には、Positive Result Bias(良い結果だけが論文投稿される)やSingle Benchmark Bias(特定のデータセットでの結果だけで議論される)などのいくつかのバイアスが存在しており、これらを解決できるのが大きなコミュニティであり、Kaggleではそれを実現できるといった話でした。
HP introduction - Key note
スポンサーであるHP社からのKeynoteがありました。
HPバルセロナではプリンタ関連の事業を一つとしてしているらしく、プリンタの中で使われている画像関連のML技術や、SitePrintと呼ばれる建築時に図面通りに線を引くロボットにおける3Dオブジェクト検出などのML応用例が紹介されていました。
エッジデバイス上での話や、具体的なアルゴリズムの話(Teacher-Studentモデルの話など)等もされており、興味深かったです。
Kaggle Team - Ask Me Anything
KaggleのCEO含む運営メンバーが何でも質問に答えるよ!という時間でした。参加しているKagglerたちから様々な質問が飛び交ってました。
一つQAをピックアップすると、「KaggleにとってKPI・成功は何か?」という質問がありました。 これに対しては、たくさんあるが一つとして、ホストにKaggleコンペの本当の価値を気付いてもらうことを大事にしているとのことでした。 ただデータを提供して問題を送信して勝者を決めてソリューション提供のためにお金を払うのではない、フォーラムでのディスカッション内容や沢山の素晴らしいノートブックなど他にも多くの価値があり、それに気付いてもらうことを大事にしているといった旨を話していました。 Happy Whaleコンペでは、ザトウクジラの研究について少なくとも1ダースの新しい発見がありました。こういったサクセスストーリーも楽しみにしているとのことでした。
またKaggle自体を、熱心に取り組む人はもちろんですが、それ以外の多くの人も歓迎する場所にしたいといった話もしていました。OpenRemarkでのトピックと共にですが、Kaggle自体はコンペティションのプラットフォームであるだけでなく、コミュニティとして大きく価値あるものにしていきたいという意思を個人的には感じました。

Winners team presentation
こちらは、予選で総合成績1位のチームSSSSによる、予選12回の各コンペティションのソリューション及び短期間のコンペでのTIPSが紹介されました。
12回のコンペ全てに参加しているチームは少なく、その中での様々なコンペティションでの知見などは非常に参考になりました。短期間かどうかに関わらず有用な情報だったと思います。発表スライドはこちらで公開されています。
UI/UX User Interview
こちらはイベントのアジェンダとは別にはなりますが、休憩エリアにてKaggleのUI/UXに関するユーザーインタビューも実施しておりました。
KaggleのUI/UXデザイナーの方から、
- ソリューションを共有するテンプレートがあるとしたら、どういった内容が必要か?(例を提示されて)テンプレートを見てどう思うか?
- TopページのUIとして、(4枚のページ画像を提示されて)どのUIが一番好きか?それはなぜか?
といったいくつかのインタビューを休憩スペースにて受けました。
Kaggle運営としてもこういった直接のユーザーに声を聞く機会は貴重だったのではないかと思います。 また、こうしてユーザの声を聞きながらUI/UXを改善していく姿勢は好感が持てました。
2日目(コンペティション当日)
2日目はお待ちかねのコンペティションでした。
2日間ともコンペティションでもいいかと思いましたが、そうすると1日目での交流や情報が得られず、なにより徹夜になってしまうので、2日目をコンペティションにしたのは正解だと思いました。

コンペティション概要
以下はコンペティションの概要です。
- 午前8:30から19:30まで11時間
- 2コンペ同時開催
- それぞれのコンペの順位に対して得点がつき、合計得点で総合順位が決まる
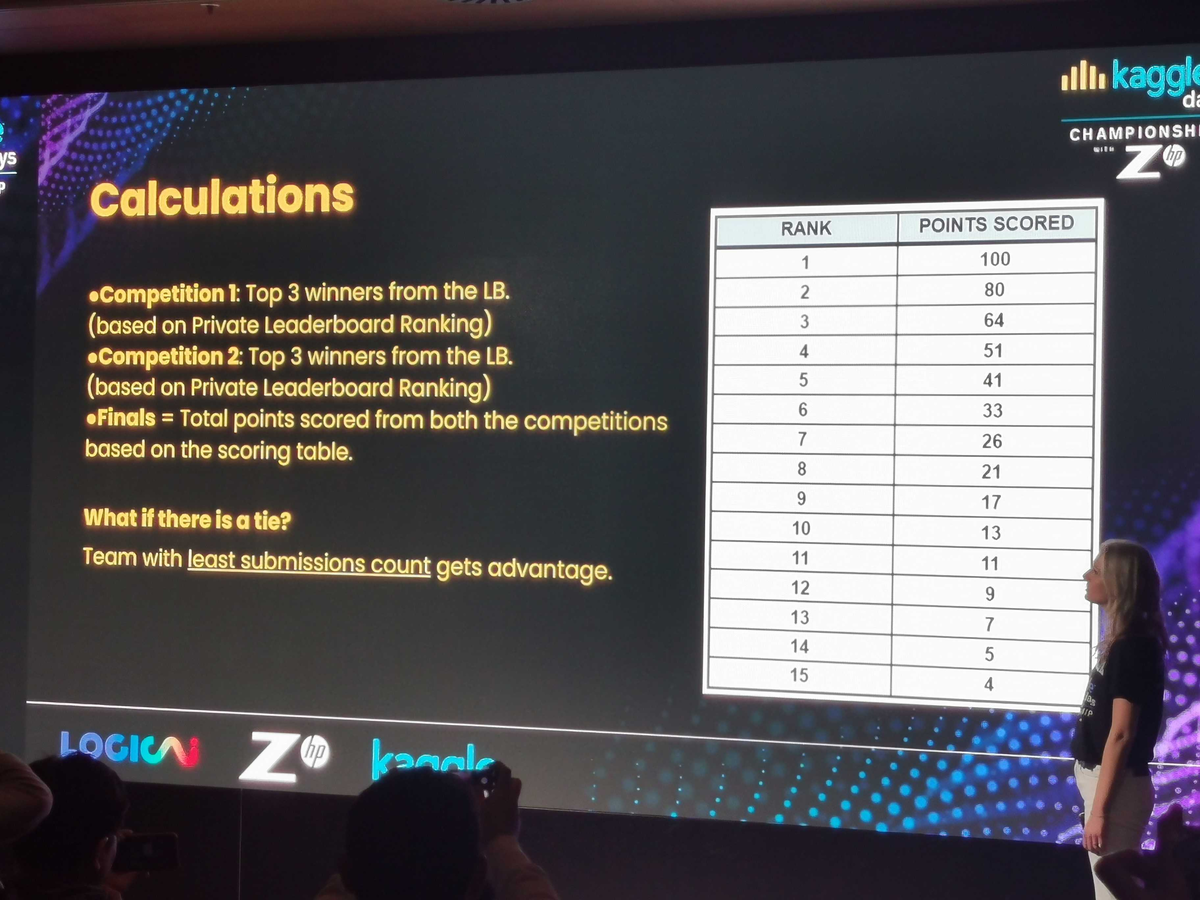
2コンペ同時というのは異例で会場からも驚きの声が出ました。 チーム内でどういう分担でコンペに挑むのか、力の入れ具合はどうするのか?といった単独のコンペとは異なる戦略が必要になります。
また、チーム人数は最大4人なのですが、私のチームは3人だったため、同時に2個というのは少しビハインドになる条件でした。
Competition1: Starry Starry Night!
1つ目のコンペの内容です。
- お題: 条件の異なる地点・時間における星がどれだけ明るく見えるかを予測する
- 明るさが8段階存在し、クラスを予測する分類問題(評価指標はミクロF1)
- データには以下のような情報が含まれる
- 予測対象の緯度経度、国名
- 測定日時
- センサーでの測定値
- 雲の量
- 観測した星
- 観測時のコメント
- コメント1: 予測対象地点の情報
- コメント2: 予測した日の天気の情報
Competition2: Time isn’t the main thing, it’s the only thing
2つ目のコンペの内容です。
- お題: Kaggle上でのNotebookの実行時間をソースコードから予測する
- 時間を予測する回帰タスク(評価指標はRMSE)
- データには以下のような情報が含まれる
- 各セルの内容(Pythonのコードやマークダウンのテキスト等)
- Notebookにおける入出力のファイル情報
通常のKaggleとの違い
通常のKaggleコンペティションに比べて今回のChampionship Finalは、いくつか性質が異なるところがあります。
期間の短さ
通常Kaggleでは2~3ヶ月かけて1つのコンペを行うのですが、このChampionshipでは1日という短かい期間でコンペを行います。 予選では4時間、決勝では11時間で行われました。 そのため、コンペ中にとれる戦略が通常のKaggleとは大きく変わってきます。
ちなみに私自身はatmaCupと呼ばれる1回あたり1日~2週間程度の比較的時間の短いコンペティションで過去に何度か入賞したことがあり、比較的得意な方ではありました。 また、短期間のコンペでの戦い方について下記で共有しています。
お題が直前までわからない
通常のKaggleでは同時にいくつもコンペが開催されています。 そして参加者は、自分が興味あったり得意だったり参加したいコンペを選んで参加します。
しかしChampionshipでは課題は直前に発表されて、参加者が選べるわけではありません。 その結果、勝率を上げるには、幅広いコンペに対応できることも望まれます。
事前準備
11時間しかないため、事前にソースコードの用意をしておくことも大事になってきます。
十分に準備をする時間はとれませんでしたが、私はテーブルデータとNLPに絞って用意をしました。 画像系については中途半端に用意するよりも、その領域が得意なチームメンバーに任せることにし、私は自分が戦える領域に絞って用意しました。 結果的に準備を絞ってよかったと思います。
テーブルデータ
テーブルデータのパイプラインには、特徴量作成から勾配Boosting系モデルの学習・予測までのコードで、以下のようにテキストカラムの処理含むいくつかの処理と関数が含まれています。特別なものがあるわけではなく、これまでの経験上よく使う且つ効きやすいものに絞っています。
- コード全体
- データ読み込みから特徴量作成・学習、OOF(OutOfFold)及びTestの予測結果保存
- デコレータ関数
- 一度作った特徴量をキャッシュから読み込む or リセットできる
- noglobal(notebook頻出のグローバル変数汚染対策。指定したglobal変数以外を関数内で使うとエラーになる)
- 特徴量作成コード(一部抜粋)
- TargetEncoding
- TextカラムへのTFIDF+SVD特徴量
- マルチカテゴリカラム or カテゴリカラム間でのWord2Vec特徴量
- Groupbyでの集約特徴量系
- 学習用コード
- XGBoost, Catboost, LightGBMの3つに対応
NLP
こちらはConfigで基本的な学習条件などは切り替えれるようにしておきましたが、以下のシンプルなコードです。
- BERT系(Transformer)のベクトル抽出
- BERT系モデルのFineTuning
最近のNLPコンペだとBERT系を使うことがほとんどのため、この部分だけ用意しています。 また、BERT系以外のNLP部分はテーブルデータ側の方に寄せてます。
どんなパイプラインを用意するか?
ここは流儀が分かれるところで最適解は人によって違うと思いますが、私は以下の方法で用意しました。
- Notebook形式
- 1実験1ファイル
- 過去コンペデータでテンプレートのコードを用意
Notebookと1実験1ファイルにしたのはある程度のお題に対して柔軟で対応しやすいのと、実行環境を移行しやすい(トラブル時にKaggle Notebook上に移行するなども出来る)ためです。
また、過去コンペデータでテンプレートを用意したのは、直前までパイプラインを修正しても動作確認しやすいためです。 テンプレの関数とかだけ用意する方法もありましたが、コンペに合わせたコードを追加するのと、既存のコードを修正するのであれば、実装時間もそこまで変わらないので、1実験1ファイルと併用できるテンプレート形式を採用しました。
この方法がベストだとは思いませんが、色んな方法を試した結果たどり着いた方法であり、あくまで自分にとっては戦いやすかったものでした。
コンペ中の軌跡
私はほとんどCompetition1について取り組んでいたため、Competition1についての取組について紹介したいと思います。 参加者以外細かい部分は分からないかも知れませんが、考え方などのイメージが伝わるよう具体的に書いています。

EDA: Train/Testの分かれ方とCV戦略
まずは基本的なEDAを10~20分程度したあとに、TrainデータとTestデータの分け方について確認しました。 そしてCV(CrossValidation)の作り方について考えました。
こういったコンペティションでは、予測結果を提出することでPublicスコアが計算されますが、自分の手元のValidationデータでモデルの性能を測れるようにしておくことが非常に重要と言われています。
短期間コンペだからこそ、ここを一度間違った方針にしてしまうと後で大きなロスになるため多めに時間を使いました。 そして以下の流れで考えながらCVを作っていきました。
- データ的にも時間情報を持っているデータであるため、TrainとTestは時間で分割されているのでは?
- TrainとTestの時間を確認したが、どちらも2013~2020年のデータを含んでおり、時間で分割されていなかった
- 国や位置情報で分割されているのでは?
- TrainとTestの国や位置情報の分布を比較したが、重複していて、分割されていなかった
- じゃあ同じ場所でほぼ同じ時間のデータがTrainとTestに含まれているってこと??(そんなリークしそうな分け方ありえるのか?)
- Train/Testで共通した場所のデータの時間を確認→年が重複していない!(Trainは2014, 2015, 2018年, Testは2016, 2020年)
ということで結論、同じ場所・年を一つのグループとして、StratifiedGroupKFoldで、同じグループがTrain/Valid間にならないようにCVを作ることにしました。他のチームではあまりやっていなかった部分であり、後続の工夫の効き具合にも間接的に影響はしていたのかなと思っています。
LightGBMのモデル
CV戦略が定まったあとはベースラインモデルをLightGBMで作りました。
最初は、基本的な特徴量(数値特徴量+カテゴリをLabelEncoding)とテキスト特徴量(TFIDF + SVD)で作りました。その後、テキストデータに対してのWord2Vec特徴量を追加したり、Groupbyでの集約特徴量などを試したり、個人的にコンペで定番的にやることを次々と試しました。事前準備のおかげもあり、効率的には進められたかと思います。
この時点では10チームくらいがサブミットしていてその中で4位くらいだったと思います。
方向性を考える
私はベースモデルを作り終えたタイミングで、残り時間をどこに使うか?を考えることが多く、今回もこのタイミングで考えました。
現状の自身のスコアとトップチームのスコア、タスクやデータの質、今思いついているアイデア、そしてモデルのfeature importanceを見ることが多いです。
| feature | importance |
|---|---|
| sensor_reading | 279283 |
| le_clouds | 238981 |
| latitude | 55877 |
| year | 51950 |
| longitude | 47789 |
| elevation_m | 44197 |
| population | 32543 |
| le_type | 29787 |
| tfidf_svd_comment_2_3 | 22556 |
| month | 20527 |
| tfidf_svd_comment_1_3 | 18352 |
| w2v_comment_1_7 | 17862 |
| le_country | 17639 |
| day | 16227 |
| w2v_comment_1_16 | 16194 |
こちらは途中段階のモデルのimportanceです。(85個の特徴量のうち上位15個を表示) ここからいくつかの事象が読み取れ、仮説を立てられます。
sensor_reading(センサーでの明るさの値)が効いている- そもそもかなり欠損しているのに、このimportanceの高さになっている
- 欠損値をうまく補完すると、精度が上る可能性はあるかも?
le_clouds(雲の量に関するカテゴリデータ)が効いている- 雲の量によって星がどれだけ見えるかはたしかに大きく変わりそう
- 数パターンしかなくてimportance上位なのは非常に効いている
- 他の条件と組み合わせた特徴量は作ったほうが良さそう
- 緯度経度(latitude, longitude)が高い
- 場所によって星がどれだけ見えるかは変わりそうなので納得感はある
- 近くの場所で実際どれくらいのTargetの分布になるかは特徴量として使えそう
- テキスト特徴量(
tfidfやw2vとついたもの)はそこそこ上位にいる- Top10には入ってないまでも、それなりには効きそう
- 単語ベースでこれであれば、BERTなど文脈も加味するともっと効くかも知れない
- 他の特徴量(
yearやle_type、elevation_mのような特徴量)も効いている- これらももっと活用の可能性はありそう
- ある時期・ある場所でどうだったか?のような特徴量も使えるかもしれない
これらを元に以下の3つを行うことを考えました。(実際には他にも細かいものは考えてましたがそれは省略します)
sensor_readingの欠損値補完をする- textカラムに対してBERTベースの特徴量を入れる
- 上位に入っていた複数カラムの組み合わせ情報を使う→カラムを組み合わせたTargetEncodingを行う
そして、2のBERTは時間が学習含めて時間がかかりそうだったので、BERTの実装を先にしつつ、処理中に他の実装をやることにしました。
その後の改善
仮説を元にいくつか実験を行いました。
1. sensor_readingの欠損値補完をする
元々LightGBMなどの勾配ブースティングモデルは欠損値があっても精度良く分類できますが、importanceが明らかに上位だと補完も試して見る価値があると思いました。 実際にKaggle Championshipの予選の一つでは欠損値補完が勝つための鍵でした。
しかし、こちらは結果的にあまりうまくいきませんでした。
欠損していない sensor_reading で学習し欠損した値を予測値で埋めましたが、スコアはほぼ変わらずでした。
(予測値は別カラムにする、欠損部分だけ予測値で埋める、欠損フラグも合わせて用意するなども試しましたがダメでした。)
2. textカラムに対してBERTベースの特徴量を入れる
こちらはうまくいきました。 そして勝因の一つだったと思います。
最初は、学習済みBERTのembeddingを特徴量に入れました。 ただ、そちらは精度向上しませんでした。その後はFineTuningを試しました。
具体的には、
- 2つのテキストカラム(
comment_1とcomment_2)を[SEP]トークンで連結させたものをInputに使う - モデルはdistilroberta-base を1 epoch学習
- モデルのOOF(Out Of Fold)予測結果(各クラスの予測確率)をLightGBMの特徴量に入れる
としました。
「distilroberta-base を1 epoch学習」というのは一般的に言うと、モデルも小さく学習数も少ないです。
ただ、今回のデータをよく使われるモデルで学習させると、1epochで20~30分かかりました。(GPUはA100 x 1)
LightGBMの5FoldのCVに合わせると、1epochだけで2~3時間かかります。
これは11時間のコンペでは致命的な所要時間です。
まずは、BERT系の取組み自体が成功するかを早い段階で見極めたかったため、軽量モデルかつ1epochという条件で試しました。
結果、Public LBで0.52672 から 0.55415(その時点で6位以下から1位)に上がりました!!
ちなみにその後チームメイトに多数のモデルを試していただきましたが、結果的に精度向上しませんでした。 恐らく、テキストデータには同じ文言が何度も入っていたり過学習がしやすい要素もあり、軽量で1epochというのが良かったのかと思います。
3.上位に入っていた複数カラムの組み合わせ情報を使う→カラムを組み合わせたTargetEncodingを行う
こちらも大きく効きました。 具体的には、以下のカラムの組み合わせを使いました。
- 緯度経度を小数点を丸めてカテゴリ化(緯度経度を元にした長方形のエリアをカテゴリにする)
- 小数点以下は1桁、2桁、3桁を用意
- 例: 緯度35.39234, 経度135.72951 => 2桁の場合
35.39_135.72というカテゴリを作る
clouds(雲の量)evaluation_m_round(高度)を丸めたものyear(年)type(センサーの種類)
緯度経度のカテゴリ化については、具体的には以下のような形でpandasで作っています。 実際には緯度によってエリアの広さが変わってくるためGeoHashなどを使うほうが正確ですが、実装速度を優先しました。
df["area3"] = df["latitude"].round(3).astype(str) + "_" + df["longitude"].round(3).astype(str) df["area2"] = df["latitude"].round(2).astype(str) + "_" + df["longitude"].round(2).astype(str) df["area1"] = df["latitude"].round(1).astype(str) + "_" + df["longitude"].round(1).astype(str) df["area0"] = df["latitude"].round().astype(str) + "_" + df["longitude"].round().astype(str)
そしてこれらに対して、TargetEncodingを行いました。 Target EncodingでKaggleでよく使われる手法で、カテゴリをTargetの平均値で数値にEncodingする方法(ただしLeakを抑えるためにCrossValidationに合わせて計算する)です。
結果、ここで0.018程度トータルで上がりました。(これがなかったら8位相当でした。)
最終モデル
最終的には私が上記で作ったモデルに少し手を加えた最終版モデルと、チームメイトが作ったモデルをアンサンブルすることによって、Public Scoreで1位になることが出来ました。
私が作ったBERTモデルの予測結果のみ特徴量として共有しましたが、それ以外は別々で作っていたため、モデル同士の相関は低く、アンサンブルの効果も高かったです。
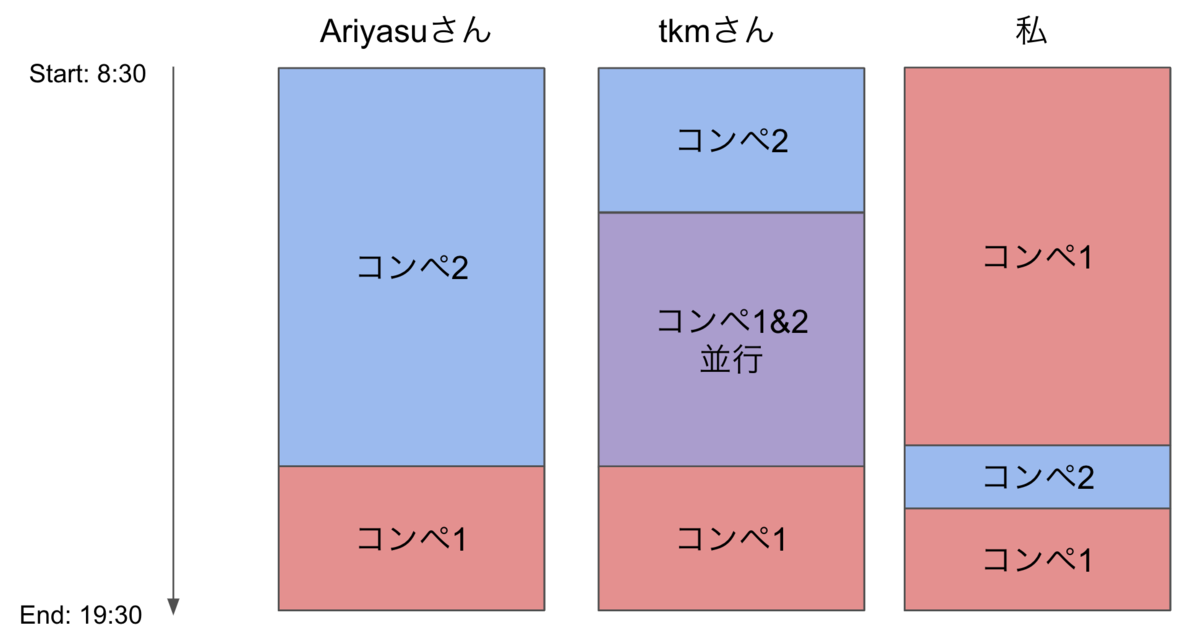
チームの体制について
3人で2コンペに対応する必要があったため、以下の体制で実施しました。
私は主にコンペ1のほうに、ほとんど時間を使っていました。 コンペ2が面白そうだなーと思いつつ、コンペ1だけでやることが沢山あって、コンペ2に手を出す余裕が殆どありませんでした。 また、両方のコンペを見ていたチームメイトのtkmさんが、両コンペのバランスを見ながら、後半にコンペ1に時間を注いだほうが良さそうと考え、チームでもそちらに時間をかけたことも勝因の一つだったと思います。
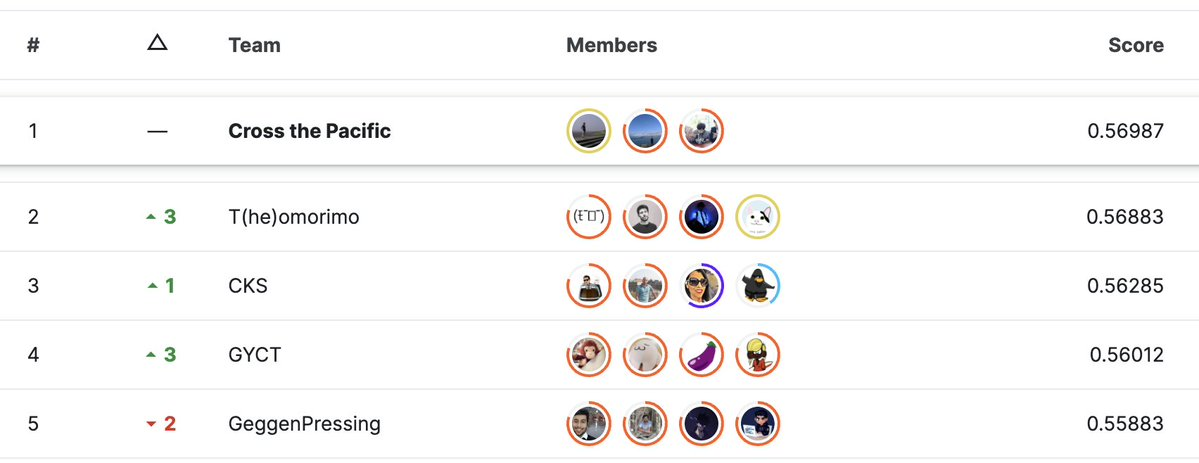
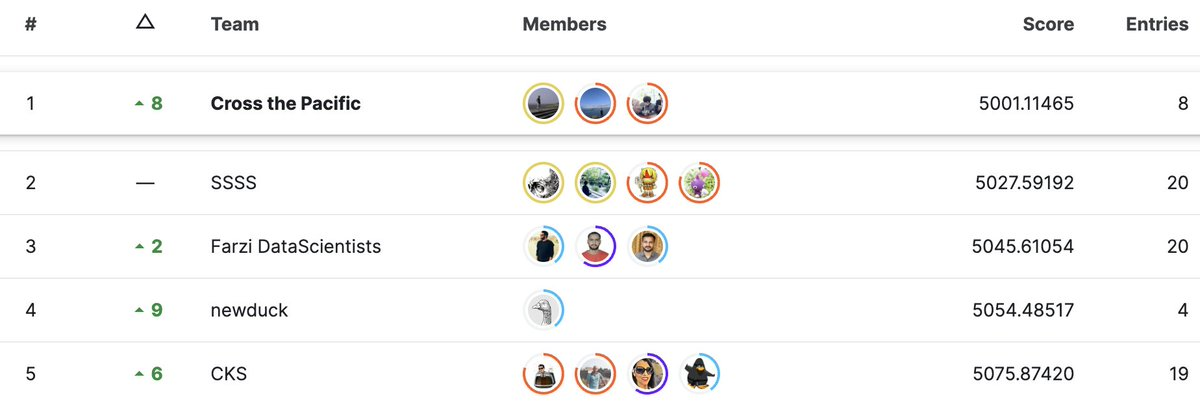
結果発表
最終的な結果発表です。
3位から順番に発表があり、3位、、2位、、と名前が呼ばれなかった時点で諦めかけていました。
が、最後にチーム名が呼ばれ、1位を取ることが出来ました!!!!
そしてなんと両方のコンペティションで1位という形で優勝することが出来ました。

振り返り
コンペティションの解法自体は、過去のKaggleコンペティションの解法と比べて洗練されているというよりはシンプルなものだと思っています。
ただ、通常の3ヶ月程度のコンペに対して今回は11時間しか使えず、
- 大事な要素を見極めて素早く実装すること
- 事前の準備やその場で使える引き出しを多く用意しておくこと
そういった点が重要だったかと思います。
コロナ禍ではこういったオフラインでのコンペティションは減っていましたが、対面で会話しながら皆で集中しながらコンペティションに参加することは、通常のKaggleなどでは味わえない体験です。
そしてチームメイトにも恵まれました。 同じ宿で事前準備や作戦会議をしたのはいい思い出です。 チームメイトには感謝してもしきれないですし、ただ勝つだけでなく楽しくコンペができるチームでした。
第2回以降もやるという話を運営の方がされていたので、今後も参加し勝てるようにしたいと思います。


最後に
イベントへの参加に関して
今回のKaggle Championshipについて移動日含め業務として参加させていただきました。 こういったイベントへの理解及び参加を柔軟に認めていただける会社に感謝するとともに、ここでの知見を持ち帰り業務でも短時間で大きなアウトプットが出せるようにしていきたいと思います。
採用メッセージ
ABEJAでは共に働く仲間を募集しています。 Kaggle好きな方も歓迎しておりますし、ABEJAのデータサイエンティストはKaggleでの経験が活きる仕事だと思います。(実際に複数のKaggle Masterが活躍しています!) また、他にもGPTモデルの開発もしたり、多くのチャレンジをしています。
ちょっと話を聞いてみたい、もう少し詳しく知りたいなどありましたら、是非ともご連絡ください。
データサイエンティスト以外にもソフトウェアエンジニアや様々な職種も募集しています。
心よりお待ちしております。
