
今回は LangChain 社より公開されている local-deep-researcher という、ローカル LLM で動作する Deep Research を簡単に作成できる OSS を動かして、その構造について解説します。
※ 本記事では Linux と Mac 向けの動作手順を記載しています。 Windows 向けの環境構築手順は下記レポジトリの README をご参照ください。 github.com
こちらの OSS では OpenAI や Google をはじめ、各社が提供している deep research 機能に近しいアプリケーションを、ローカルの LLM モデルを使って実現しています。
OSS の名称から推察できますように、こちらは Ollama を利用してローカル LLM を動作させ、 LangGraph を用いて調査業務を担ってくれる AI エージェントを構築しています。
動作の仕組み
OSS の README にある記述を元に、簡単に説明します。 とりあえず動かしたい!!という方は 動かしてみる! のセクションにスキップしてください。
Local Deep Researcher で使われている手法
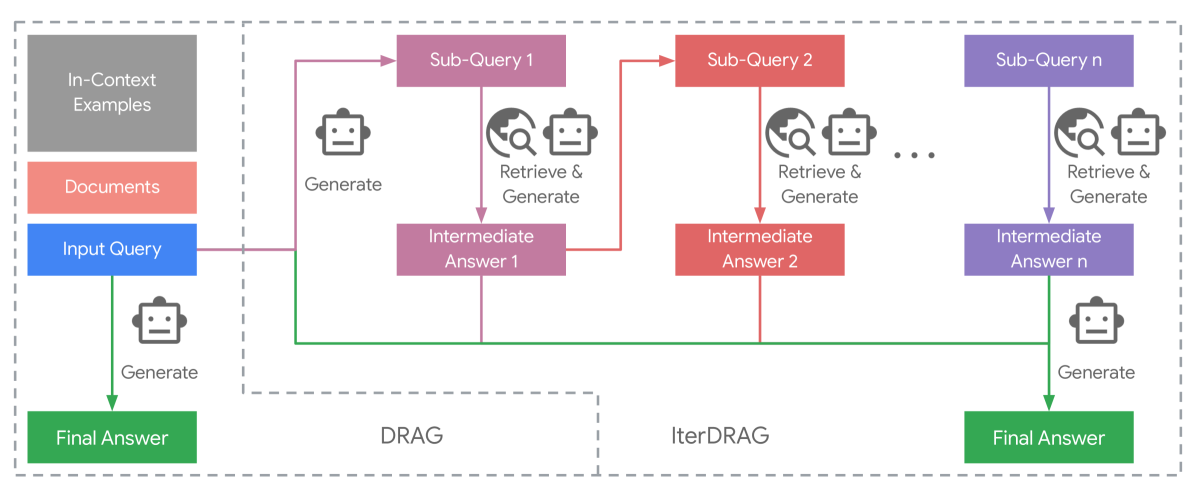
Local Deep Researcher では、 IterDRAG と同様の手法を用いています。
- ユーザーが入力した調査タスクに基づいて、ローカル LLM(Ollama 経由)を使用してウェブ検索クエリを生成
- 設定された LLM 向けのウェブ検索エンジン (Tavily もしくは Perplexity 等) を用いて、関連する情報源を探索
- ユーザーが入力した調査タスクに関連するウェブ検索結果を LLM で要約
- その後、LLM を利用して要約を振り返り、不足している知識を特定
- 知識の不足を解消するため、新たな検索クエリを生成
- 2 〜 5 までのプロセスが設定された回数分繰り返し、ウェブ検索から得た情報を利用して要約を逐次更新
IterDRAG
Local Deep Researcher は IterDRAG から着想を得て作られています。
IterDRAG で提案されている手法は、ユーザーが入力した調査タスク (クエリ) を LLM がより細かい質問 (サブクエリ) を生成、その細かい質問に対して LLM が RAG を用いて回答を生成し、その回答内容に不足があると LLM が判断すれば再度「より細かい質問を生成 -> 回答を生成」のフローを実行、回答内容に不足がないと LLM が判断すればユーザーに対してその回答を提示する、といったものになります。
IterDRAG の論文に記載の図が分かりやすいので、以下に示します。
LangGraph の入門
IterDRAG の実装を確認する前に、まずは簡単に LangGraph の解説を行なっておきます。 Local Deep Researcher では LangChain 社が提供している LangGraph という AI エージェント構築用のライブラリを使って実装されています。
LangGraph では AI エージェントのワークフローをグラフ構造としてモデル化して扱います。そのため、基本的には下記の 3 つの要素を用いて AI エージェントを構築します。
State: 現在の AI エージェントの状態を保持する構造体。Node: AI エージェントが行う処理を格納した関数。現在の State を受け取り、何らかの処理や副作用を実行した後に、更新された State を返します。Edge: 次に実行する Node を決定する関数。 固定の Node を指定させることもできますし、条件によって次に実行する Node を変化させることもできます。
例えば、特定の都市をユーザーが入力した時、関連する都市の天気も取得するシンプルな AI を構築すると下記のようになります。この場合、 start や get target city が Node となり、その Node 同士を繋ぐのが Edge になります。
┌─────────────────────┐
│ start │
└──────────┬──────────┘
│
┌──────────▼──────────┐
│ get target city │
└──────────┬──────────┘
│
┌─────────────▼─────────────┐
│ get surrounding cities │
└─────────────┬─────────────┘
│
┌───────────────▼────────────────┐
│ get weather for all cities │
└───────────────┬────────────────┘
│
┌───────────────▼────────────────┐
│ generate output │
└───────────────┬────────────────┘
│
┌──────────▼──────────┐
│ end │
└─────────────────────┘
この時の State は例えば下記のように書けます。
{
target_city: "Tokyo", # ユーザーが入力した都市名
nearby_cities: ["Saitama", "Urayasu", "Kawasaki"] # 周辺の都市名
weather_for_cities: [
{
city: "Tokyo",
weather: "Sunny"
},
...
]
}
そして、処理の流れとしては下記のようになります。
startNode から開始して State を初期化、get target cityに進むget target cityNode でユーザーから入力を受け取り、State にあるtarget_cityの値をセットget surrounding citiesNode で外部の API を利用して、nearby_citiesに入れる都市の一覧を取得して State の値をセットget weather for all citiesNode でtarget_cityとnearby_citiesの一覧にある都市の天気を外部の API 等で取得して State のweather_for_citiesに値をセットgenerate outputNodeで現在の State にあるweather_for_citiesの値を LLM に入力して応答文を生成、ユーザーに返答するendNode で AI エージェント終了
IterDRAG の実装
Local Deep Researcher の中身の実装は /src/ollama_deep_researcher 配下にあります。ディレクトリ内にあるファイルを確認してみましょう。
├── __init__.py ├── configuration.py # AI エージェントの config を定義 ├── graph.py # Node と Edge でグラフを定義 ├── lmstudio.py # lmstudio 用のコード ├── prompts.py # LLM を利用する箇所のプロンプトを記載 ├── state.py # State を定義 └── utils.py # util の格納場所
graph.py と state.py を覗いてみましょう。
graph.py には以下の関数が定義されており、それぞれが Node に対応しています
generate_query(state, config)ユーザーの指定した調査内容に基づいて、最適化された検索クエリを生成する関数web_research(state, config)生成されたクエリを使用して外部の検索ツールを用いてWeb検索を実行する関数summarize_sources(state, config)Web検索の結果を要約する関数reflect_on_summary(state, config)現在の要約を分析し、知識のギャップを特定finalize_summary(state)最終的にユーザーに返すレポート文を作成route_research(state, config)検索のループ回数が上限に達したかチェックして、継続する場合はweb_research、終了する場合はfinalize_summaryに進む
一方で、state.py は下記のように SummaryState が定義されています。
[フィールド詳細]
research_topic : 調査のトピック(ユーザーが指定する調査内容)
search_query : 現在の検索クエリ(LLMが生成した最適化されたクエリ)
web_research_results : Web検索結果のリスト
sources_gathered : 収集したソース情報のリスト
research_loop_count : 研究ループの実行回数(何回検索・要約を繰り返したかのカウンター)
running_summary : 実行中の要約(最終的にはここに完成したレポートが格納される)
以上を踏まえて、以下のような処理の流れになっていることが確認できるかと思います!
[1] START → generate_query(開始ノード)
- グラフは
STARTから始まり、最初にgenerate_queryノードを呼び出します。 - 状態の初期化:
SummaryStateオブジェクトが作成されます。 - ノードは最初の
research_topicを受け取ります。 - LLM を使用して 検索クエリ を生成し、
state.search_queryに保存します。
[2] generate_query → web_research
web_researchノードは、生成されたsearch_queryを受け取ります。- 設定済みの外部 検索 API(例:Tavily、Perplexity、DuckDuckGo、SearxNG など)を呼び出しています。
- 取得結果は
state.sources_gatheredとstate.web_research_resultsに保存されます。 research_loop_countがインクリメントされます。
[3] web_research → summarize_sources
summarize_sourcesノードは、直近の Web リサーチ結果(state.web_research_results[-1])を受け取ります。- LLM にプロンプトを与え、情報を要約します。
- 生成された要約は
state.running_summaryに保存されます。
[4] summarize_sources → reflect_on_summary
reflect_on_summaryノードは、現在のrunning_summaryを分析します。- LLM に対し、知識の不足部分を特定し、必要に応じて 追加クエリ を生成します。
- 新しいクエリは
state.search_queryに保存されます。
[5] reflect_on_summary → route_research
route_research関数は、state.research_loop_countと設定されたmax_web_research_loopsに基づき、次のステップを決定します。- ループ回数が上限未満の場合、
"web_research"を返して再びデータ収集サイクルを繰り返します。 - 上限に達した場合は
"finalize_summary"を返します。
[6] finalize_summary(終了ノード)
finalize_summaryノードは、収集した全ての情報を重複排除・整形し、それをrunning_summaryに追加して最終的な出力を生成します。- その後、グラフは
ENDに到達し、AI エージェントは終了します。
こうまとめてみると全体像が掴みやすくなりますね。
では早速環境構築をしつつ、実際に動作を確認してみましょう!
動かしてみる!
1. Ollama を こちら からダウンロードして、動作させたい環境にインストールします。
2. Ollama からローカル LLM を pull します。 README では deepseek-r1:8b を利用していますが、今回はせっかくなので別の軽量モデル qwen3:4b を利用してみます。
ollama pull qwen3:4b
3. Ollama Deep Researcher のリポジトリをクローンします。
git clone https://github.com/langchain-ai/local-deep-researcher.git cd local-deep-researcher
4. ウェブ検索ツールを選び、 API キーを発行します。現在は DuckDuckGo、SearXNG、Tavily もしくは Perplexity が使えますが、デフォルトは無料で利用できる DuckDuckGo が指定されているので、まずはこちらを利用してみます。
5. サンプルの環境設定ファイルをコピーします
cp .env.example .env
6. お好みのテキストエディタで .env ファイルを編集し、API キーを追加できますが、今回は DuckDuckGo を利用するので修正不要です。
MAX_WEB_RESEARCH_LOOPS は IterDRAG をループさせる回数 (デフォルトは 3 ) 、 FETCH_FULL_PAGE は DuckDuckGo でページのコンテンツ全体を取得するか (デフォルトは false ) を設定する値になっています。
SEARCH_API=xxx # the search API to use, such as `duckduckgo` (default) TAVILY_API_KEY=xxx # the tavily API key to use PERPLEXITY_API_KEY=xxx # the perplexity API key to use MAX_WEB_RESEARCH_LOOPS=xxx # the maximum number of research loop steps, defaults to `3` FETCH_FULL_PAGE=xxx # fetch the full page content (with `duckduckgo`), defaults to `false`
注: 環境変数を直接 API キーを使用したい場合は、シェルで以下のように設定できます。
export TAVILY_API_KEY=tvly-xxxxx # OR export PERPLEXITY_API_KEY=pplx-xxxxx
環境変数で API キーを設定した後、以下のようなコマンドでキーが正しく設定されているか念のため確認しておきましょう。
echo $TAVILY_API_KEY # Should show your API key
7. (推奨) 仮想環境を作成します。お好みの Python 仮想環境のツールがあればそちらを使用しても問題ありません。
python -m venv .venv source .venv/bin/activate
8. LangGraph サーバーを使用してアシスタントを起動します。
# Install uv package manager curl -LsSf https://astral.sh/uv/install.sh | sh uvx --refresh --from "langgraph-cli[inmem]" --with-editable . --python 3.11 langgraph dev
※ 次回以降の起動は以下のコマンドのみで大丈夫です
uvx --refresh --from "langgraph-cli[inmem]" --with-editable . --python 3.11 langgraph dev
9. LangGraph Studio Web UI https://smith.langchain.com/studio/?baseUrl=http://127.0.0.1:2024 にアクセスして、反復回数と利用するローカル LLM を指定する
以下のスクリーンショットのような画面が表示されますので、 [new +] をクリックして、今回使うパラメーターを設定しておきます

Assistant Name: <パラメータの構成名、任意の名前で大丈夫です> Research Depth: 3 LLM Model Name: qwen3:4b LLM Provider: ollama Search API: duckduckgo Fetch Full Page: ☑️ Ollama Base URL: http://localhost:11434/ LMStudio Base URL: http://localhost:1234/v1 Strip Thinking Tokens: ☑️ Recursion limit: 25
10. [Research Topic] に調べてもらいたい内容を記述して、 [Submit] を押して実行
以下は『友人の転職祝におすすめのプレゼントを調べてください。相手は私と同じ 20 代後半で、予算は 4000 円程度でおねがいします』と調査をお願いしてみた結果です。

▼出力結果はこのような感じになりました(クリックして展開)▼
Summary
以下は、予算4000円程度で友人の転職祝いに送るおすすめプレゼントです。キャリアに関する本や、転職・副業に関連するアイテムを考慮して選んでいます。
● 1. キャリアに関する本(4000円以内) - 『転職と副業のかけ算 生涯年収を最大化する生き方』
- 転職と副業の組み合わせで収入を最大化するための実用的なアドバイスが満載。転職を機にキャリアを再考する人に最適。
- 価格: 3,500円前後(書店で購入可)。
『世界一やさしい「やりたいこと」の見つけ方』
- 自己理解とキャリアの方向性を明確にするためのメソッド。転職をきっかけに「自分に合った仕事」を発見するのに役立つ。
- 価格: 3,000円前後(電子書籍も含む)。
『科学的な適職【ビジネス書グランプリ2021 自己啓発部門 受賞! 】』
- 理論的アプローチで職業の適性を分析する本。転職の際に「自分に合った業界」を特定するのに役立つ。
- 価格: 3,200円前後(書店で購入可)。
● 2. キャリアに寄り添った小物(4000円以内) - 転職向けマニュアル・ポストカード
- 転職活動に役立つマニュアルや、キャリアのステップを示したポストカード。
- 価格: 1,000円前後(印刷・手作りも可能)。
- キャリアテーマのマグカップ・ペン
- 「新しいステップ」「キャリアの未来」などのメッセージ入りのマグやペン。
- 価格: 1,500円前後(通販や書店で購入可能)。
● 3. サブスクリプション(4000円以内) - キャリア関連のサブスクリプション
- 転職向けのオンライン講座や、キャリア改善のための月刊誌のサブスクリプション。
- 価格: 月額1,000円前後(1年間の利用可能)。
● 4. パーソナライズされたアイテム - 名前入りキャリアボード
- 転職を記念して、自分のキャリアをまとめたボード。
- 価格: 2,000円前後(カスタムオーダー可能)。
● ポイント - 本は「転職のきっかけ」や「キャリアの未来」をテーマにした内容が豊富で、長期的な価値があります。
- 小物は即座に使える形で、転職を祝う気持ちを伝えることができます。
- サブスクリプションは、継続的なサポートを提供する形で、転職後のキャリアサポートにも役立ちます。おすすめ: 本を贈るか、転職に役立つマニュアルのポストカードを贈るか、どちらかを選んでください。4000円以内で、転職を祝う気持ちと実用性を兼ね備えた贈り物になります。
(参考にしたサイトのリンク先がこの後に記載されていますが、割愛)
ローカルの MacBook Pro (M2 2022モデル) でも 5 分程度で上記の内容がまとまって提示されたので、意外と使えそうかもと思ったのは私だけでしょうか?
より大きなローカルモデルを利用してどれくらい ChatGPT や Gemini の Deep Research に肉薄するか確認してみたくなりますね...!
最後に
Ollama と LangGraph を用いることで、お手軽に Deep Research 機能をローカル LLM で作成することができました。
本記事が今後皆様の快適なローカル LLM ライフを送る上での足掛かりとなりましたら幸いです。
We Are Hiring!
ABEJAは、様々な業界におけるテクノロジーの社会実装に取り組んでいます。 技術はもちろん、技術をどのようにして社会やビジネスに組み込んでいくかを考えるのが好きな方は、下記採用ページからエントリーください! 新卒の方やインターンシップのエントリーもお待ちしております!
