こんにちは!ABEJAでデータサイエンティストをしている藤原です。ABEJAアドベントカレンダー2024 の11日目のブログになります!
キーフレーズ抽出を簡単に試すという機会がよくあるのですが、簡単に検証する範囲だといつも同じツール・モデルを使っているため、他の方法でも上手くキーフレーズ抽出ができないか?ということで今回いくつか検証してみました。やることとしては、まず Embedding Model を使って日本語の長めの文章からキーフレーズを上手く抽出できるか?というのを検証します。その上で、色々な Embedding Model 間で抽出されるフレーズがどのように違うか?も比較してみます。
目次
- 目次
- はじめに
- Embedding Model でのキーフレーズ抽出のアルゴリズム
- 実装
- 実験条件
- 実験結果
- 実験1. キーフレーズ抽出のアルゴリズムの比較
- 実験2. Embedding Model の比較
- Model-1:sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2
- Model-2:sentence-transformers/paraphrase-multilingual-mpnet-base-v2
- Model-3:bclavie/JaColBERTv2
- Model-4:answerdotai/JaColBERTv2.5
- Model-5:intfloat/multilingual-e5-large
- Model-6:intfloat/multilingual-e5-base
- Model-7:pkshatech/GLuCoSE-base-ja-v2
- Model-8:pkshatech/RoSEtta-base-ja
- Model-9:cl-nagoya/ruri-large
- Model-10:cl-nagoya/ruri-base
- おまけ
- まとめ
- We Are Hiring!
はじめに
キーワード抽出・キーフレーズ抽出とは?
キーワード抽出・キーフレーズ抽出とは、対象の文章からその文章の中で重要な単語やフレーズを抽出するというものです。抽出したキーワードやキーフレーズは、例えば文章にタグをつけて検索に活用したり、長い文章の要点を把握するのに役立てたりという使い方ができます。基本的には、対象の文章のトピック・テーマをよく表現できているものや、トピック・テーマの分野や種類を判別するのに役立つものがその文章のキーワード・キーフレーズになります。
また、単語単位で抽出するのがキーワード抽出で、連続する単語をその品詞などによって一つのフレーズとしてフレーズ単位で抽出するのがキーフレーズ抽出です。単語単位の抽出だとその単語単体では意味が十分に理解できないことや、文章のトピックやテーマを表現するには不十分なことがあります。一方で、フレーズ単位での抽出では、例えば名詞の連続を一つの名詞句として取り出すことで、文章中での意味をより適切に理解できる形で語句を抜き出すことができるようになります。
キーフレーズ抽出の手法
キーフレーズ抽出のアプローチとしては主に以下の三種類が挙げられると思います。それぞれのメリット・デメリットも簡単にまとめてみます。
| アプローチ | ツール | メリット | デメリット |
|---|---|---|---|
| グラフベース・統計ベース | PKEなど | コストがかからない、処理速度が早い、抽出精度もそこそこ | 形態素解析精度にも依存するため専門用語などの高品質な抽出は難しい |
| LLM ベース | GPT4oなど | 高品質な抽出には良い | API利用コストがかかる、オープンなモデルを使う場合は強いGPU環境が必要 |
| Embedding ベース | KeyBERTなど | コストがかからない、処理速度はそこそこ | オープンソースの抽出ツールだと日本語の長文などで上手く機能しない、形態素解析の問題はPKE同様 |
1. グラフベース・統計ベース
PKE (Python Keyphrase Extraction) というオープンソースのライブラリを利用することができます。メリットとしては、利用コストがかからないことと、CPUでも高速に動作します。抽出精度としては、余計なフレーズが一部抽出されたりもしますが、重要なフレーズがある程度上位に抽出できる印象です。そのため簡単な検証などでは利用する機会が多く、自分がキーフレーズ抽出を試す時も、まずはPKEを使ってみることが多いです。デメリットとしては、文章を形態素解析する処理が必要なため、専門的な用語など上手く形態素解析ができない単語やフレーズは抽出に失敗しやすいです。
2. LLM ベースのアプローチ
このアプローチはシンプルで、対象の文章と指示を与えてLLMにキーフレーズを抽出してもらうという方法です。メリットとしては、形態素解析に依存せず、キーフレーズの定義もプロンプトで設計できるため、綺麗で必要最低限のキーフレーズを抽出したいといった要件の場合には良いアプローチだと思います。デメリットとしては、クローズドのモデルを使う場合はAPIの利用料金が、オープンなモデルで高性能なものを使う場合は強いGPU動作環境が必要になる点です。ノートPCなどで動かせるレベルのローカルLLMだと、処理速度や抽出精度、フレーズの品質が低いため、簡単な検証では利用するのが難しい印象です。
3. Embedding ベースのアプローチ
このアプローチがこの記事のメインテーマで、Embedding Model を使ってキーフレーズを抽出するという方法です。代表的なツールとしては KeyBERT があります。具体的な抽出のアルゴリズムやKeyBERTについての説明は後述しますが、メリットとしては日本語のみのモデルなどはかなりモデルサイズが小さく、ノートPCのGPUやCPUでも十分な処理速度で実行することができ、近年のオープンな日本語の Embedding Model は OpenAI の Embedding Model と比べても十分な性能を示しているため、利用コストをかけずに済みます。
デメリットとしては、そもそも KeyBERT が日本語に対応したツールではないため、日本語でキーフレーズ抽出するには少し工夫が必要です。また抽出精度も特に長文などではPKEを使った抽出結果に比べて不要な単語が多い印象があり、やはり簡単な検証ではPKEを使うことが多いです。ちなみに、Embeddingベースのアプローチでもフレーズ単位で抽出するには形態素解析を行う必要があるため、形態素解析が難しい単語・フレーズの抽出はPKE同様難しい可能性が高いです。
とはいえ、利用コストなし&オープンソースで利用できるので、PKE以外の選択肢を増やすべく、今回は KeyBERT のアルゴリズムを少しアレンジして、 Embedding Model で上手くキーフレーズ抽出ができないか?というのを検証してみます。また、実装した Embedding Model ベースのキーフレーズ抽出器を使って色々な多言語・日本語の Embedding Model でキーフレーズ抽出を行い、抽出結果を比較してみます。
Embedding Model でのキーフレーズ抽出のアルゴリズム
KeyBERT
KeyBERT での抽出のアルゴリズムはかなりシンプルなものになっています。README.md では以下のように記載されています。
First, document embeddings are extracted with BERT to get a document-level representation. Then, word embeddings are extracted for N-gram words/phrases. Finally, we use cosine similarity to find the words/phrases that are the most similar to the document. The most similar words could then be identified as the words that best describe the entire document.
処理のステップを整理すると、
- 文章全体を Embedding
- 単語(または N-gram)単位で Embedding
- 文章全体の Embedding と、各単語(または N-gram)の Embedding の類似度を算出
- 類似度の高い単語(または N-gram)をキーワードとして出力
となります。
この方法は入力の文章が短文の場合は問題なくキーワード抽出ができそうです。一方で、文章が長くなると一つの文章の中にいくつかのサブトピックが存在することも多く、それぞれのトピックの内容や各文の細かなニュアンスが一つの Embedding では表現するのが難しくなっていきます。また、Embedding のメリットは単語の文脈情報を埋め込めることですが、単語単位で Embedding するとそのメリットが上手く活かし切れなくなります。
アレンジ版
今回は KeyBERT で用いられているアルゴリズムをベースに少しアレンジする形でキーフレーズ抽出の精度を高められるか検証します。具体的に実装するアルゴリズムは以下のような処理ステップになります。
- 文章全体を Embedding
- 文単位で Embedding
- 文章全体の Embedding と、文単位の Embedding の類似度を算出し、文章と各文の類似度ランキングを作成
- 類似度が上位の文をキーワード抽出の対象とする
- 対象文中の各フレーズを Embedding
- 各対象文の Embedding とその文中のフレーズの Embedding の類似度を算出し、文ごとの文中のフレーズの類似度ランキングを作成
- 3の処理で得られた文単位の類似度のランキングと、6の処理で得られたフレーズ単位の類似度のランキングをマージ(Reciprocal Rank Fusion)
- マージ後のランキングでの上位をキーフレーズとして出力
変更点は大きく2つあり、一つ目が長文への対応のために文単位での Embedding を導入するという部分です。元々は文章と単語を直接比較してキーワードを抽出していたところを、まずは文章と文で比較して、さらに各文と文中の単語で比較します。これによって、「文章全体との類似度が高いキーワード」ではなく、「文章全体と類似度の高い文から、その文との類似度が高いキーワード」を抽出できるようになります。特に、文章と文の比較によって Embedding のメリットである文脈の埋め込みがより活かせるようになります。
もう一つの大きな変更点は抽出のアルゴリズムとは少し別の観点になりますが、単語単位ではなくフレーズ単位での抽出に変更している点です。後半の実験で PKE との比較を行うのですが、PKE では単語を形態素解析して、特定の品詞の系列を一つのフレーズにまとめることで単語単位ではなくフレーズ単位での抽出が行われています。今回はこの処理を導入して、フレーズ単位での抽出を行います。一個目の変更点同様、フレーズ単位にすることで文脈の埋め込みが単語単位よりも活かせるようになります。
実装
上記のアレンジ版の Embedding Model ベースのキーフレーズ抽出のモジュールを実装したものが以下になります。
▶︎ データモデルの定義 (data.py)
from typing import Literal, Self from pydantic import BaseModel, Field, computed_field, confloat, model_validator class EmbeddingPrompts(BaseModel): passage: str query: str class EmbeddingModel(BaseModel): name: str prompts: EmbeddingPrompts | None = None device: str = Field(default="mps", examples=["cpu", "mps", "cuda", "npu"]) trust_remote_code: bool = True # model_kwargs = {"torch_dtype": torch.float16} # torch.float16, torch.bfloat16, torch.float class Parameters(BaseModel): diversity_mode: Literal["normal", "use_maxsum", "use_mmr"] top_n_phrases: int max_filtered_phrases: int max_filtered_sentences: int cutoff_ratio_phrases: confloat(ge=0.0, le=1.0, strict=False) | None cutoff_ratio_sentences: confloat(ge=0.0, le=1.0, strict=False) | None threshold: confloat(ge=0.0, le=1.0, strict=False) | None nr_candidates: int nr_candidates_ratio: confloat(ge=0.0, le=1.0, strict=False) | None diversity: confloat(ge=0.0, le=1.0) @computed_field @property def use_maxsum(self) -> bool: return self.diversity_mode == "use_maxsum" @computed_field @property def use_mmr(self) -> bool: return self.diversity_mode == "use_mmr" @model_validator(mode="after") def validate_nr_candidates(self) -> Self: if ( self.nr_candidates < self.max_filtered_phrases or self.nr_candidates < self.max_filtered_sentences ): raise ValueError( f"`nr_candidates` ({self.nr_candidates}) must be greater than or equal to both " f"`max_filtered_phrases` ({self.max_filtered_phrases}) and " f"`max_filtered_sentences` ({self.max_filtered_sentences})." ) else: return self @model_validator(mode="after") def validate_nr_candidates_ratio(self) -> Self: if ( self.nr_candidates_ratio is None and self.cutoff_ratio_phrases is None and self.cutoff_ratio_sentences is None ): return self elif ( self.nr_candidates_ratio is None or self.cutoff_ratio_phrases is None or self.cutoff_ratio_sentences is None ): raise ValueError( """All values for `cutoff_ratio_phrases`, `cutoff_ratio_sentences`, and `nr_candidates_ratio` must be provided or all must be None.""" ) elif ( self.nr_candidates_ratio < self.cutoff_ratio_phrases or self.nr_candidates_ratio < self.cutoff_ratio_sentences ): raise ValueError( f"`nr_candidates_ratio` ({self.nr_candidates_ratio}) must be greater than or equal to both " f"`cutoff_ratio_phrases` ({self.cutoff_ratio_phrases}) and " f"`cutoff_ratio_sentences` ({self.cutoff_ratio_sentences})." ) else: return self
▶︎ KeyBERT を wrap して処理をアレンジしたもの (model.py)
from itertools import chain from typing import Literal import numpy as np from keybert._maxsum import max_sum_distance from keybert._mmr import mmr from nltk import RegexpParser from sentence_transformers import SentenceTransformer from sklearn.metrics.pairwise import cosine_similarity from spacy import Language from spacy.tokens.doc import Doc from .data import Parameters class JapaneseKeyBERTModel: def __init__( self, model: SentenceTransformer, text_processor: Language, batchsize: int = 32, stop_words: list[str] | None = None, use_prompt: bool = False, rrf_k: int = 60, show_progress_bar: bool = True, pos_list: list[ Literal[ "NOUN", "PROPN", "VERB", "ADJ", "ADV", "INTJ", "PRON", "NUM", "AUX", "CONJ", "SCONJ", "DET", "ADP", "PART", "PUNCT", "SYM", "X", ] ] = ["NOUN", "PROPN", "ADJ", "NUM"], ): # Embedding model self.model = model self.batchsize = batchsize self.use_prompt = use_prompt self.use_prompt = use_prompt # Initialize a tokenizer self.text_processor = text_processor self.pos_list = pos_list self.stop_words = stop_words # Parameters self.show_progress_bar = show_progress_bar self.rrf_k = rrf_k def _words_to_phrases( self, words: list[str], words_pos: list[str], grammar: str = None ) -> tuple[list[str]]: # Initialize default grammar if none is provided if grammar is None: grammar = r""" NBAR: {<NOUN|PROPN|ADJ>*<NOUN|PROPN>} NP: {<NBAR>} {<NBAR><ADP><NBAR>} """ # Parse sentence using the chunker grammar_parser = RegexpParser(grammar) tuples = [(str(i), words_pos[i]) for i in range(len(words))] tree = grammar_parser.parse(tuples) # Extract phrases and their POS tags candidates = set() for subtree in tree.subtrees(): if subtree.label() == "NP": leaves = subtree.leaves() first = int(leaves[0][0]) last = int(leaves[-1][0]) phrase = " ".join(words[first : last + 1]) candidates.add(phrase) # Add individual words if they are not part of NP and match the POS list for word, pos in zip(words, words_pos, strict=True): if pos in self.pos_list and word not in candidates: candidates.add(word) return list(candidates) def _tokenize_text(self, text: str, phrasing: bool = True) -> list[str]: doc: Doc = self.text_processor(text) words = [] words_pos = [] for token in doc: words.append(token.text) words_pos.append(token.pos_) if phrasing: tokens = self._words_to_phrases(words=words, words_pos=words_pos) else: tokens = list( set( [ _word for _word, _pos in zip(words, words_pos, strict=True) if _pos in self.pos_list ] ) ) return tokens def _extract_sentences( self, docs: list[str], sentences: list[list[str]] ) -> list[list[tuple[str, float]]]: # Calculate sentence-level similarity to document doc_embeddings: np.ndarray sentence_embeddings: list[np.ndarray] if self.use_prompt: doc_embeddings = self.model.encode( sentences=docs, prompt="passage", batch_size=1, show_progress_bar=self.show_progress_bar, ) sentence_embeddings = [ self.model.encode( sentences=_sentences, prompt="query", batch_size=32, show_progress_bar=self.show_progress_bar, ) for _sentences in sentences ] else: doc_embeddings = self.model.encode( sentences=docs, batch_size=1, show_progress_bar=self.show_progress_bar ) sentence_embeddings = [ self.model.encode( sentences=_sentences, batch_size=32, show_progress_bar=self.show_progress_bar, ) for _sentences in sentences ] key_sentences: list[list[tuple[str, float]]] = [] for chunk_idx, (_sent_embeds, _sentences) in enumerate( zip(sentence_embeddings, sentences, strict=True) ): _doc_embed: np.ndarray = doc_embeddings[chunk_idx].reshape(1, -1) if self.params.cutoff_ratio_sentences is None: _top_n = self.params.max_filtered_sentences _nr_candidates = self.params.nr_candidates else: _top_n = max( int(len(_sentences) * self.params.cutoff_ratio_sentences), 1 ) _nr_candidates = max( int(len(_sentences) * self.params.nr_candidates_ratio), _top_n ) try: # Maximal Marginal Relevance (MMR) if self.params.use_mmr: _key_sentences = mmr( _doc_embed, _sent_embeds, _sentences, _top_n, self.params.diversity, ) # Max Sum Distance elif self.params.use_maxsum: _key_sentences = max_sum_distance( _doc_embed, _sent_embeds, _sentences, _top_n, _nr_candidates, ) # Cosine-based keyphrase extraction else: distances = cosine_similarity(_doc_embed, _sent_embeds) _key_sentences = [ (_sentences[i], round(float(distances[0][i]), 4)) for i in distances.argsort()[0][-_top_n:] ][::-1] if self.params.threshold is not None: _key_sentences = [ key for key in _key_sentences if key[1] >= self.params.threshold ] # Capturing empty keyphrases except ValueError: _key_sentences = [] key_sentences.append(_key_sentences) return key_sentences def _extract_phrases( self, sentences: list[list[str]], phrases: list[list[list[str]]] ) -> list[list[list[tuple[str, float]]]]: sentence_embeddings: list[np.ndarray] phrase_embeddings: list[list[np.ndarray]] if self.use_prompt: sentence_embeddings = [ self.model.encode( sentences=_sentences, prompt="passage", batch_size=32, show_progress_bar=self.show_progress_bar, ) for _sentences in sentences ] phrase_embeddings = [ [ self.model.encode( sentences=_phrases_one_sentence, prompt="query", batch_size=32, show_progress_bar=self.show_progress_bar, ) for _phrases_one_sentence in _phrases ] for _phrases in phrases ] else: sentence_embeddings = [ self.model.encode( sentences=_sentences, batch_size=32, show_progress_bar=self.show_progress_bar, ) for _sentences in sentences ] phrase_embeddings = [ [ self.model.encode( sentences=_phrases_one_sentence, batch_size=32, show_progress_bar=self.show_progress_bar, ) for _phrases_one_sentence in _phrases ] for _phrases in phrases ] key_phrase: list[list[list[tuple[str, float]]]] = [] for _sentence_embeds, _phrase_embeds_list, _phrases_list in zip( sentence_embeddings, phrase_embeddings, phrases, strict=True ): _key_phrase_chunk = [] for sent_idx, (_phrase_embeds, _phrases) in enumerate( zip(_phrase_embeds_list, _phrases_list, strict=True) ): _sentence_embed: np.ndarray = _sentence_embeds[sent_idx].reshape(1, -1) if self.params.cutoff_ratio_phrases is None: _top_n = self.params.max_filtered_phrases _nr_candidates = self.params.nr_candidates else: _top_n = max( int(len(_phrases) * self.params.cutoff_ratio_phrases), 1 ) _nr_candidates = max( int(len(_phrases) * self.params.nr_candidates_ratio), _top_n ) try: # Maximal Marginal Relevance (MMR) if self.params.use_mmr: _key_phrases = mmr( _sentence_embed, _phrase_embeds, _phrases, _top_n, self.params.diversity, ) # Max Sum Distance elif self.params.use_maxsum: _key_phrases = max_sum_distance( _sentence_embed, _phrase_embeds, _phrases, _top_n, max(self.params.nr_candidates, _top_n), ) # Cosine-based keyphrase extraction else: distances = cosine_similarity(_sentence_embed, _phrase_embeds) _key_phrases = [ (_phrases[i], round(float(distances[0][i]), 4)) for i in distances.argsort()[0][-_top_n:] ][::-1] if self.params.threshold is not None: _key_phrases = [ key for key in _key_phrases if key[1] >= self.params.threshold ] # Capturing empty keyphrases except ValueError: _key_phrases = [] _key_phrase_chunk.append(_key_phrases) key_phrase.append(_key_phrase_chunk) return key_phrase def _reciprocal_rank_fusion( self, sentence_similarities: list[list[float]], key_phrases: list[list[list[tuple[str, float]]]], ) -> list[list[tuple[str, float]]]: # Calcurate the ranks of sentences sentence_ranks: list[list[int]] = [ (np.array(_similarities).argsort()[::-1] + 1).tolist() for _similarities in sentence_similarities ] # Calcurate the ranks of phrases phrases_flatten: list[list[tuple[str, float]]] = [] rrf_scores: list[list[float]] = [] for _sent_ranks, phrases_list in zip(sentence_ranks, key_phrases, strict=True): _phrases: list[str] = [] _scores: list[float] = [] for _sent_rank, _phrases_and_scores in zip( _sent_ranks, phrases_list, strict=True ): _phrases += [ _phrase_and_score[0] for _phrase_and_score in _phrases_and_scores ] _phrase_ranks: list[int] = ( np.array( [ _phrase_and_score[1] for _phrase_and_score in _phrases_and_scores ] ).argsort()[::-1] + 1 ) _scores += [ (1 / (_sent_rank + self.rrf_k)) + (1 / (_phrase_rank + self.rrf_k)) for _phrase_rank in _phrase_ranks ] rrf_scores.append(_scores) phrases_flatten.append( [ (_phrase, _score) for _phrase, _score in zip(_phrases, _scores, strict=True) ] ) sorted_indices = [np.argsort(_scores)[::-1] for _scores in rrf_scores] sorted_phrase_scores: list[list[tuple[str, float]]] = [ [_phrases[_idx] for _idx in _indices] for _phrases, _indices in zip(phrases_flatten, sorted_indices, strict=True) ] return sorted_phrase_scores def extract_keyphrases( self, docs: list[str], sentences: list[list[str]], params: Parameters, filter_sentences: bool = True, phrasing: bool = True, ) -> list[list[tuple[str, float]]]: self.params = params if filter_sentences: # Extract the key sentences key_sentences: list[list[tuple[str, float]]] = self._extract_sentences( docs=docs, sentences=sentences ) # Get phrases sentences: list[list[str]] = [] phrases: list[list[list[str]]] = [] for _sentences in key_sentences: phrases.append( [ self._tokenize_text(text=_sent[0], phrasing=phrasing) for _sent in _sentences ] ) sentences.append([_sent[0] for _sent in _sentences]) # Extract the key phrases key_phrases: list[list[list[tuple[str, float]]]] = self._extract_phrases( sentences=sentences, phrases=phrases ) # Reciprocal Rank Fusion for final ranking sentence_similarities: list[list[float]] = [ [_sent[1] for _sent in _sentences] for _sentences in key_sentences ] sorted_keyphrases: list[list[tuple[str, float]]] = ( self._reciprocal_rank_fusion( sentence_similarities=sentence_similarities, key_phrases=key_phrases, ) ) else: docs: list[list[str]] = [[_doc] for _doc in docs] phrases: list[list[list[str]]] = [] for _sentences in sentences: _phrases: list[str] = [] for _sent in _sentences: _phrases += self._tokenize_text(text=_sent, phrasing=phrasing) phrases.append([list(set(_phrases))]) # Extract the key phrases key_phrases: list[list[list[tuple[str, float]]]] = self._extract_phrases( sentences=docs, phrases=phrases ) sorted_keyphrases: list[list[tuple[str, float]]] = [ _phrases[0] for _phrases in key_phrases ] # Get top-n phrases result_keyphrases: list[list[tuple[str, float]]] = [] for _keyphrases in sorted_keyphrases: unique_keyphrases: dict[str, float] = {} for _keyphrase in _keyphrases: if _keyphrase[0] not in unique_keyphrases: unique_keyphrases[_keyphrase[0]] = _keyphrase[1] top_n_keyphrases = sorted( unique_keyphrases.items(), key=lambda x: x[1], reverse=True )[: self.params.top_n_phrases] result_keyphrases.append(top_n_keyphrases) return result_keyphrases
▶︎ キーフレーズ抽出器 (extractor.py)
import re from typing import Literal import pandas as pd import spacy from sentence_transformers import SentenceTransformer from spacy import Language from ..base_extractor import BaseExtractor from .data import EmbeddingModel, Parameters from .model import JapaneseKeyBERTModel class KeyBERTBasedExtractor(BaseExtractor): def __init__( self, model_config: EmbeddingModel, batchsize: int = 32, use_prompt: bool = False, stop_words: list[str] | None = None, show_progress_bar: bool = True, pos_list: list[ Literal[ "NOUN", "PROPN", "VERB", "ADJ", "ADV", "INTJ", "PRON", "NUM", "AUX", "CONJ", "SCONJ", "DET", "ADP", "PART", "PUNCT", "SYM", "X", ] ] = ["NOUN", "PROPN", "ADJ", "NUM"], ): super().__init__(stop_words) # Initialize an embedding model use_prompt = False if model_config.prompts is None else True prompts = model_config.prompts.model_dump() if use_prompt else None model = SentenceTransformer( model_name_or_path=model_config.name, prompts=prompts, **model_config.model_dump(exclude=["name", "prompts"]), ) # Initialize an extractor self.stop_words = ( stop_words if stop_words is not None else self._get_stopword_list() ) self.text_processor: Language = spacy.load("ja_ginza") self.kw_model = JapaneseKeyBERTModel( model=model, text_processor=self.text_processor, batchsize=batchsize, use_prompt=use_prompt, stop_words=stop_words, pos_list=pos_list, show_progress_bar=show_progress_bar, ) def _split_text_into_sentences( self, text: str, minimux_strings: int = 10 ) -> list[str]: # 正規表現で改行、句点、ピリオドで分割 sentences = re.split(r"(?<=[\n。.])|(?<=\. )", text) # 空の文字列を除外し、リストを返す return [ sentence.strip() for sentence in sentences if sentence.strip() and (len(sentence.strip()) >= minimux_strings) ] def _normalize_keyphrase(self, text: str, pred_keyphrases: list[str]) -> list[str]: doc = self.text_processor(text) word_list = [ {"word": token.text, "lower_case": token.text.lower()} for token in doc if not token.is_space ] word_df = pd.DataFrame(word_list).drop_duplicates() norm_list = [] for word in pred_keyphrases: if " " in word: splited_words = word.split(" ") norm_word = "".join( self._get_norm_word(s, word_df) for s in splited_words ) else: norm_word = self._get_norm_word(word, word_df) norm_list.append(norm_word) return norm_list def get_keyphrase( self, input_text: str, max_characters: int | None = None, diversity_mode: Literal["normal", "use_maxsum", "use_mmr"] = "normal", top_n_phrases: int = 10, max_filtered_phrases: int = 10, max_filtered_sentences: int = 10, cutoff_ratio_phrases: float | None = None, cutoff_ratio_sentences: float | None = None, threshold: float | None = None, nr_candidates: int = 20, nr_candidates_ratio: float | None = None, diversity: float = 0.7, filter_sentences: bool = True, phrasing: bool = True, ) -> list[list[str]]: params = Parameters( diversity_mode=diversity_mode, top_n_phrases=top_n_phrases, max_filtered_phrases=max_filtered_phrases, max_filtered_sentences=max_filtered_sentences, cutoff_ratio_phrases=cutoff_ratio_phrases, cutoff_ratio_sentences=cutoff_ratio_sentences, threshold=threshold, nr_candidates=nr_candidates, nr_candidates_ratio=nr_candidates_ratio, diversity=diversity, ) docs: list[str] if isinstance(input_text, str): if max_characters is not None: docs = self._chunk( text=input_text, max_characters=max_characters, ) else: docs = [input_text] elif isinstance(input_text, list): docs = input_text else: raise ValueError( f"The type of input_text must be str or list[str]; {type(input_text)=}" ) sentences: list[list[str]] = [] for _doc in docs: sentences.append(self._split_text_into_sentences(text=_doc)) keyphrases_list: list[list[tuple[str, float]]] = ( self.kw_model.extract_keyphrases( docs=docs, sentences=sentences, params=params, filter_sentences=filter_sentences, phrasing=phrasing, ) ) keyphrases: list[list[str]] = [ [t[0].replace(" ", "").strip() for t in _words] for _doc, _words in zip(docs, keyphrases_list, strict=True) ] return keyphrases
実験条件
実験の内容としては、まず PKE と今回実装したキーフレーズ抽出の結果を比較します。その後、Embedding Model での抽出結果の比較を行います。
PKE でのキーフレーズ抽出では、モデルは MultipartiteRank を使用し、一つの文章から抽出するキーフレーズの個数は30個とします。(.get_n_best(n=30))
Embeddingベースの抽出では、類似度が上位の文を何件抽出するか(max_filtered_phrases)、各文から類似度の高いフレーズを何件抽出するか(max_filtered_sentences)という引数があり、これらはすべての条件で 30 に固定します。また、一つの文章から抽出するキーフレーズの個数(top_n_phrases)はPKEの条件と同様に30個とします。
入力の文章には私が以前に書いた記事「欠損, 非同期, 不規則な時系列データのモデリング - Neural CDEs の理論の導入部と実装」を Markdown 形式に変換したものを使います。入力の記事の中でトピックに直結するようなキーワードは主に「微分方程式、ニューラルネットワーク、NeuralDEs、NeuralCDEs、不規則な時系列データ、非同期」などになるため、これに類するものがキーフレーズとして抽出してほしいものになります。
実験結果
実験1. キーフレーズ抽出のアルゴリズムの比較
ここでは以下の5条件を比較します。
- PKE の MultipartiteRank での抽出
- Embedding Model に cl-nagoya/ruri-base を用いて、フレーズ化および文章のフィルタリングを導入しない
- Embedding Model に cl-nagoya/ruri-base を用いて、フレーズ化のみ導入する
- Embedding Model に cl-nagoya/ruri-base を用いて、文章のフィルタリングのみ導入する
- Embedding Model に cl-nagoya/ruri-base を用いて、フレーズ化および文章のフィルタリングを導入する
以下が各条件での抽出結果です。左から条件1~5の抽出結果が並んでおり、各列において上の行の単語・フレーズが重要度(類似度)が高いキーワード・キーフレーズになってます。また、キーワード・キーフレーズとみなせるものを赤色の太字、キーフレーズと近いが必要な単語が不足(「ニューラル」や「Differential」など)していたり、余分な単語が結合されているもの(「離散化NeuralCDEs」など)は青色の太字でハイライトしています。
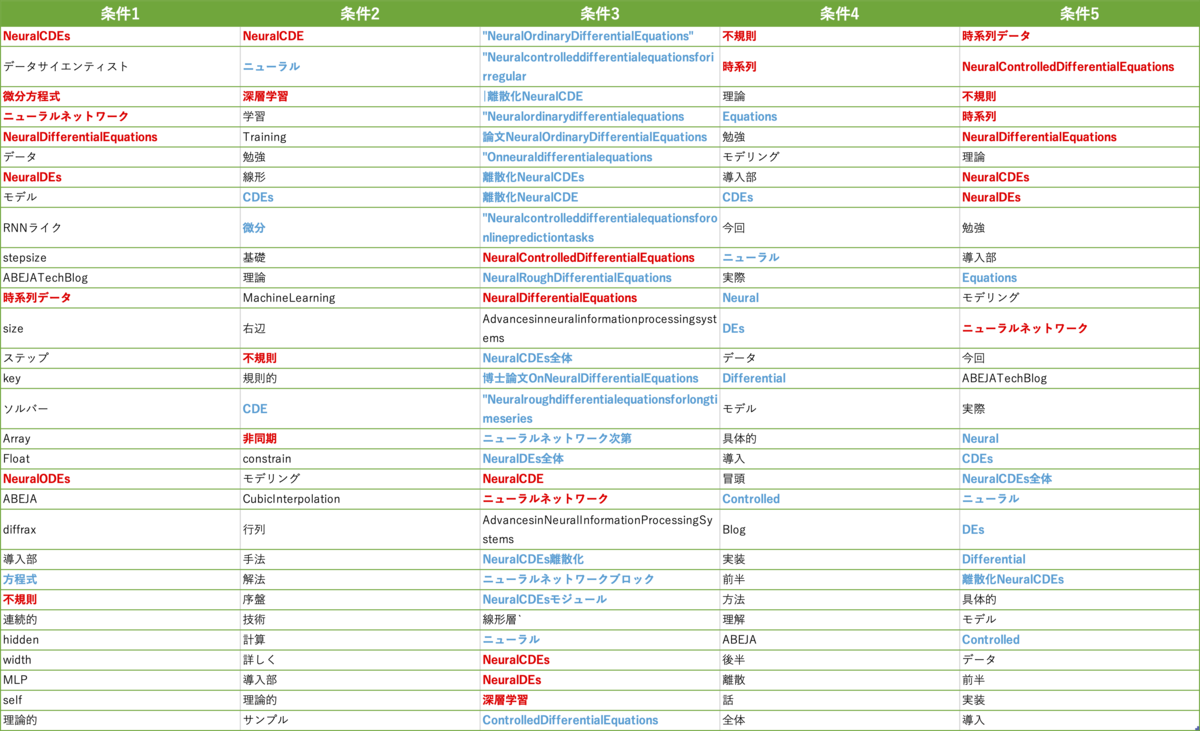
分析1.1. フレーズ化および文章フィルタリングの効果
まず条件2,3を比較してみると、フレーズ化の導入によって「NeuralOrdinaryDifferentialEquations」や「ニューラルネットワーク」など単語単位では分割されていたものが一つのまとまりとして抽出できています。しかしながら、フレーズ化して文章との類似度を算出しているため、やや長めのフレーズがキーフレーズとして抽出されている傾向があるように見えます。逆に抽出できていないものとして「微分」、「不規則」、「非同期」など元の KeyBERT のアルゴリズムでしか抽出できていません。全体的にみると、フレーズ化の導入によって似たようなフレーズが多く抽出されており、抽出精度としてはやや低下しているような印象を受けます。
次に条件2,4を比較してみると、文章のフィルタリングによって「不規則」、「時系列」といった単語の順位が上位に来ています。一方で、「非同期」、「微分」といった単語は抽出できていません。その他、文章フィルタリングありの条件では17位以降に「具体的」、「冒頭」、「Blog」など記事のトピックとは直接関係がない単語が比較的多く抽出されているように見えます。そのため、文章フィルタリングの導入も総合的には抽出精度はやや低下しているような印象を受けます。
今度は条件2,5を比較してみると、フレーズ化および文章のフィルタリングによって、「時系列データ」、「NeuralControlledDifferentialEquations」、「不規則」、「NeuralDifferentialEquations」といったフレーズが上位で抽出されており、片方だけの導入だとむしろ抽出性能がやや低下気味でしたが、両方導入することで上手く重要なフレーズの抽出ができるようになった印象です。とはいえ、「微分方程式」関連のフレーズ・単語があまり抽出できていません。またトピックとは直接関係がない単語もまだ残っています。この辺りは max_filtered_phrases 、 max_filtered_sentences などのパラメータを用いて、一つの文・文中の単語の影響度を調整することで改善できるかもしれません。
分析1.2. PKE との比較
最後に条件1,5を比較してみると、PKEは上位の抽出結果に「データサイエンティスト」、「データ」、「モデル」といった記事のトピックに特有ではない単語・フレーズがいくつか含まれていますが、Embedding ベースの抽出結果では上位8位までは記事のトピックに直結するフレーズだけが抽出されています。一方で、抽出結果全体としては、PKEの方が「微分方程式」、「RNNライク」、「ソルバー」など記事のトピックに特有のフレーズが多様に抽出されています。どちらの抽出結果が良いとはこの結果だけでは判断しづらいですが、PKEのMultipartiteRankが強いのがわかりますね。PKEとEmbeddingベースで記事のトピックに特有のフレーズはある程度同様のものが抽出されていますが、それ以外のフレーズはかなり違いがあるので、PKEでの抽出結果とEmbedding ベースでの抽出結果を Reciprocal Rank Fusion などでマージすると良い抽出結果が得られるかもしれません。
次は Embedding Model を変えることで抽出結果がどのように変わるかみてみます。
実験2. Embedding Model の比較
ここでは先ほどの条件5で Embedding Model を色々と変えて抽出結果を比較します。実験はすべて M2 Mac 上で実施しており、今回は M2 Mac のGPUで実行できるモデルに限定して実験を行っています。以下が各モデルでの抽出結果です。
- sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2
- sentence-transformers/paraphrase-multilingual-mpnet-base-v2
- bclavie/JaColBERTv2
- answerdotai/JaColBERTv2.5
- intfloat/multilingual-e5-large
- intfloat/multilingual-e5-base
- pkshatech/GLuCoSE-base-ja-v2
- pkshatech/RoSEtta-base-ja
- cl-nagoya/ruri-large
- cl-nagoya/ruri-base
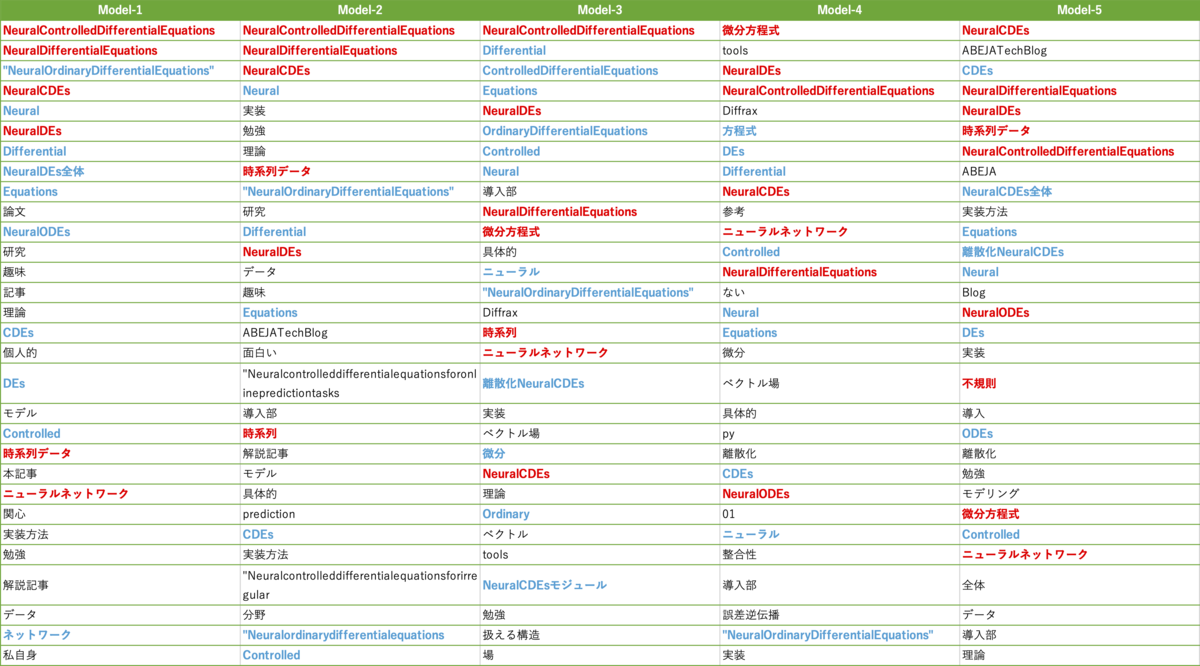
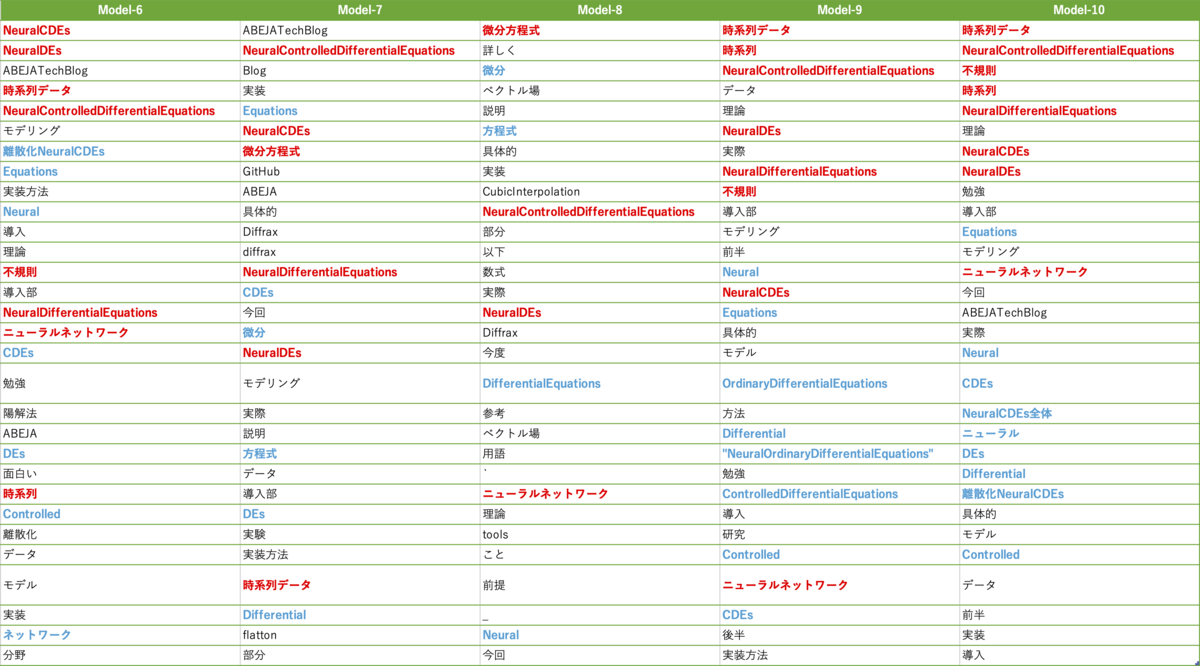
先にモデル間の比較結果をまとめると、抽出結果が良かった順に
- intfloat/multilingual-e5-large(Model-5), cl-nagoya/ruri-base(Model-10)
- bclavie/JaColBERTv2(Model-3), answerdotai/JaColBERTv2.5(Model-4), intfloat/multilingual-e5-base(Model-6), cl-nagoya/ruri-large(Model-9)
- その他のモデル
という抽出結果になった印象です。
以下は各モデルの抽出結果の個別の評価になります。
Model-1:sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2
上位は英語のフレーズが多く、下位のフレーズを見ても「不規則」、「非同期」、「微分方程式」などのフレーズは抽出できていません。
Model-2:sentence-transformers/paraphrase-multilingual-mpnet-base-v2
sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 に比べて日本語のフレーズも上位に入っていますが、記事のトピック特有のフレーズが少ないためいまいちといった印象です。
Model-3:bclavie/JaColBERTv2
上位は英語のフレーズが多いですが、「時系列」、「微分方程式」、「ニューラルネットワーク」といったフレーズが抽出できており良さそうです。
Model-4:answerdotai/JaColBERTv2.5
上位で「微分方程式」、「NeuralDEs」、「NeuralControlledDifferentialEquations」などが上位で抽出できているのはいい感じですが、「時系列」、「非同期」、「不規則」関連のフレーズがないのがマイナスポイントです。
Model-5:intfloat/multilingual-e5-large
すべてが上位ではないですが「NeuralCDEs」、「時系列データ」、「不規則」、「微分方程式」、「ニューラルネットワーク」などが一通り抽出されていてかなりいい感じです。
Model-6:intfloat/multilingual-e5-base
intfloat/multilingual-e5-largeとある程度似たような抽出結果ですが、重要だと思われるフレーズの抽出件数自体は多いですし、上位にキーフレーズが多く抽出できています。ただし、「時系列」と「時系列データ」で同じ意味の用語が抽出されていたり、「微分方程式」が抽出できていなかったり、 large に比べると少し抽出されているフレーズの種類が減っている印象です。
Model-7:pkshatech/GLuCoSE-base-ja-v2
「NeuralControlledDifferentialEquations」、「微分方程式」、「時系列データ」などのフレーズが抽出できているのは良いですが、上位の抽出結果に「ABEJATechBlog」、「Blog」、「実装」、「GitHub」などの不要なフレーズが多いのは少しマイナスポイントです。
Model-8:pkshatech/RoSEtta-base-ja
上位にNeuralCDEs関連のフレーズが少ないのが他のモデルと大きく違うところです。「時系列」、「非同期」、「不規則」関連のフレーズが抽出できていないのと、不要なフレーズが多めで、上手く抽出できていない印象です。
Model-9:cl-nagoya/ruri-large
「時系列データ」、「NeuralControlledDifferentialEquations」、「不規則」、「ニューラルネットワーク」などが抽出できていますが、上位に「データ」、「理論」、「実際」などが含まれているのが少しマイナスポイントな印象です。
Model-10:cl-nagoya/ruri-base
抽出できているキーフレーズは cl-nagoya/ruri-large と概ね同じですが、「ニューラルネットワーク」の順位が上がり、「データ」、「実際」の順位は下がっているなど、上位にフレーズが集まっている点で cl-nagoya/ruri-large よりも良い抽出結果になっていそうです。「微分方程式」、「不規則」といったフレーズも抽出できているとなお良かったです。
おまけ
ちょうど新しく日本語の Embedding Model が公開されたので、そのモデルでの抽出結果も出してみました。 - sbintuitions/sarashina-embedding-v1-1b
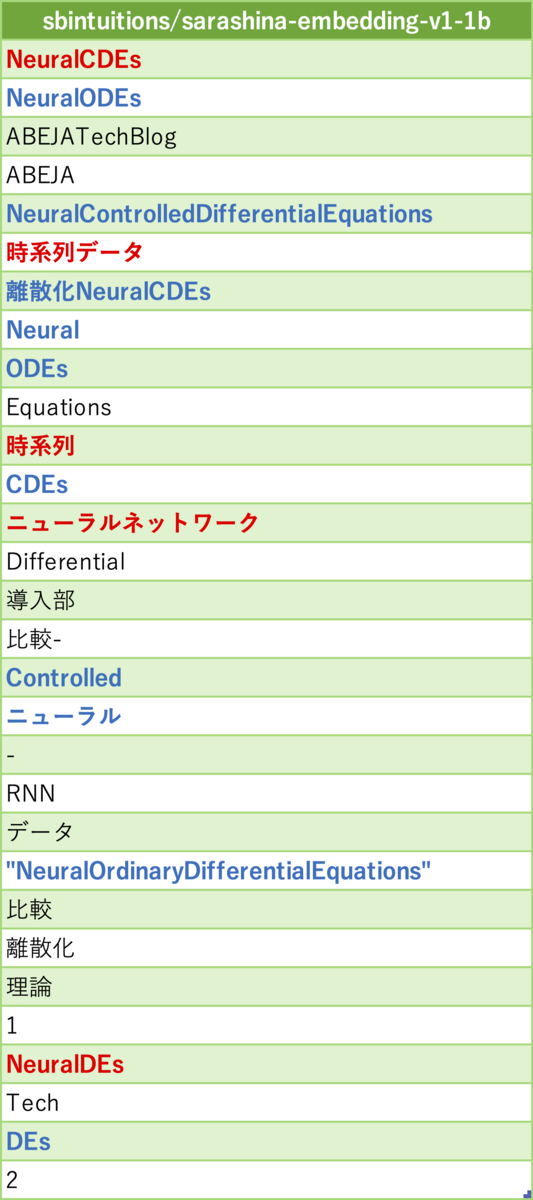
「NeuralCDEs」、「NeuralODEs」、「時系列」、「微分方程式」、「ニューラルネットワーク」などが抽出できていてある程度良さそうです。先ほどの順位に入れるとしたら2位のモデル群に入る抽出結果という印象です。
他のモデル達の抽出結果を見ても感じていた部分ですが、今回実装したアレンジ版のアルゴリズムでも Embedding Model の性能を活かしきれていないかと思います。このモデルは他のモデルに比べてモデルサイズがかなり巨大なので Embedding 自体の性能も優れているかと思うのですが、それでも抽出結果があまり良くなってないため、フレーズのEmbedding 作成時の入力プロンプトにコンテキストを追加するなど、もう少しアルゴリズムを練って Embedding Model の性能を活かし切れるようにすれば抽出精度が Embedding Model に比例するようになるかもしれません。
とはいえ、元の思惑としてはノートPCでも PKE と同じくらい高速に処理できて欲しいというのがあったため、 ruri-base 等のかなり小型のモデルで他のもっと大規模なモデルに比べて高精度な抽出結果が得られたのは個人的には良い検証結果になりました。
まとめ
今回は Embedding Model を用いたキーフレーズ抽出を KeyBERT をアレンジする形で実装し、PKEとの抽出結果の比較や Embedding Model 間での抽出結果の比較を行いました。キーフレーズ抽出のアルゴリズムを少しアレンジしたことで、定性的にですが Embedding Model ベースでもフレーズ単位での抽出がある程度綺麗にできるようになりました。
今回は比較のために PKE 内で実装されているフレーズ化と同じ条件でフレーズ化をしていますが、フレーズ化する条件を変更することでもう少し抽出したいフレーズが取得できる可能性があるかと思います。また、max_filtered_phrases 、 max_filtered_sentencesなどのパラメータや、KeyBERT を wrap しており use_maxsum、use_mmr なども使用できるため、この辺りのパラメータの調整をすることでキーフレーズ抽出の精度を高められる可能性があるかと思います。
また、Embedding Model の比較で、モデルによって予想以上に抽出結果に差が出たのも面白かったです。どの Embedding Model が良いかについては、今回は評価データが一種類で定性的にしか評価していないため判断できず、文章の長さやドメインで結果は変わってくると思います。とはいえ、軽量なモデルでもより大きなモデルよりも良い精度を出せる可能性があるのは面白い検証結果になったと思います。
We Are Hiring!
ABEJAは、テクノロジーの社会実装に取り組んでいます。 技術はもちろん、技術をどのようにして社会やビジネスに組み込んでいくかを考えるのが好きな方は、下記採用ページからエントリーください! (新卒の方やインターンシップのエントリーもお待ちしております!)
特に下記ポジションの募集を強化しています!ぜひ御覧ください!
プラットフォームグループ:シニアソフトウェアエンジニア | 株式会社ABEJA
