
こんにちは!ABEJAでデータサイエンティストをしている大田です。
先日Hugging FaceでDifferential Transformer V2の発表があり、そこでは昨年発表されたDifferential Transformer (V1)と比べてもさらに実用的な改変があったとのことです。去年にV1の論文が出たときは日本語のまとめ記事をざっと読んだくらいでしたが、2つのアテンションの差分を取ってノイズを消すというシンプルなアイデアであるにもかかわらず、実験結果ではアテンションノイズの抑制、スケーリング効率、ハルシネーションの低減など、いろいろな面できれいに改善していて驚いた記憶があります。
論文でも触れられていた検索など特定のタスクでの性能向上やロバスト性の改善、V2で実現されたKVキャッシュの効率化など、学習の安定性と高速な推論の両立に貢献したという内容は、特定ドメインの特化型ローカルLLMを手元で構築・運用していく際にも、計算リソースの節約と精度の向上という両面で重要な役割を果たしそうです。
ローカルLLM開発や運用に携わっていく立場として、LLMアーキテクチャに標準的に採用される機構は追っていきたいという観点から、Differential Transformerは興味があります。V1成果及びV2での改善点をちゃんと把握しておきたく、今更ながら論文や最新の発表内容に目を通してみました。
以下はDifferential Transformer (V1) の論文及び、V2の発表記事です。
なお、Differential Transformer V2については、2026年1月29日現在、Microsoftによる大規模な比較実験が継続中であり、V1とV2の直接的な最終性能比較データはまだ公開されていません。本記事では、現時点で判明している設計変更の意図と、中間報告ベースの知見をまとめています。
おさらい:Differential Transformer (V1) のアプローチと成果
まずは、昨年に発表された最初のバージョンの Differential Transformer (V1) の論文を読んで、そこで確認された特性やV2に関連する話題について振り返ります。
課題:Attention Noise
従来のTransformerが抱える構造的な課題として、論文ではAttention Noiseの存在を指摘しています。 Softmax関数は出力の合計が必ず1になる性質を持つため、文脈の中に無関係な情報(ノイズ)が大量に含まれている場合でも、それらにAttention scoreを割り振ってしまいます。この微小なノイズが思っているより大きく、特にコンテキスト長が増加する場合などに本来注目すべき正解(Answer)のシグナルを埋没させてしまうという問題が指摘されていました。
論文中の可視化(下図)を見ると、従来のTransformerは無関係なコンテキスト全体に薄く広くアテンションが分散しているのに対し、Differential Transformerは正解部分に集中して反応していることがわかります。
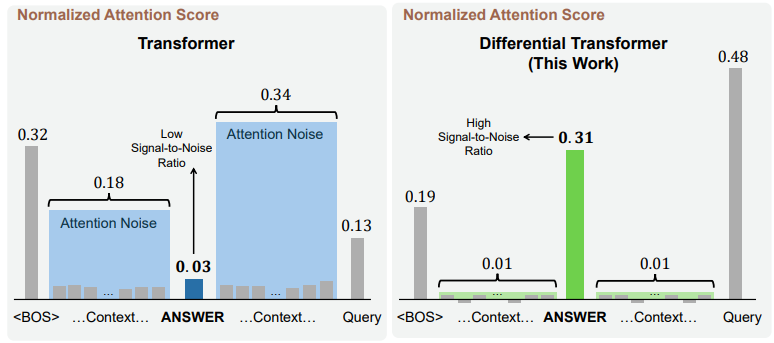
Differential Transformer (V1) で提案されたDifferential Attention
Differential Transformerは差動増幅器やノイズキャンセリングに着想を得て、Attention Noiseを取り除くためのDifferential Attentionという機構が導入されています。
仕組み自体はシンプルで、クエリとキーをそれぞれ2つのグループ( および
))に分割し、それぞれで計算したSoftmaxアテンションマップの差分を取ります。
ここでノイズキャンセルの強さを決める係数 ですが、V1論文では単なる学習パラメータではなく、論文曰く学習ダイナミクスを安定させるために、以下のような再パラメータ化が行われていました。
さらに、この (初期値)には、レイヤーの深さ
に応じた値が設定されるようになっていて、V1におけるこの
は、レイヤー内のヘッドやトークンでグローバルに共有されていました。(固定値でも比較的ロバストに動作することはアブレーションの節で書かれてはいますが)
例えばレイヤーの深さが10だった時の は約0.76になります。層が深くなるほど不要な応答を抑圧するノイズキャンセルが強く入り、浅い層では広い文脈を保持し、深い層に向かうほど特定のトークンに対するアテンションの集中度が高まると考えられます。
また、Differential Attentionは、2つのSoftmaxの差分を取ることでノイズをキャンセルします。その結果、Attention scoreは従来のTransformerよりもスパースになり、各ヘッドが出力する値の統計的性質がヘッドごとに大きく異なる状態になります。そこで、V1ではアテンションの出力直後に「各ヘッド独立の正規化(論文ではGroupNormとして記述)」が配置されており、当時のアブレーションでも有用性が示されていて、この処理は性能を出すために重要であるとされています(なおV2の解説記事では、この系統の処理を per-head RMSNorm として言及しています)。
なお、V1のSelf-Attention機構以外のアーキテクチャについては、Pre-RMSNorm、SwiGLU FFN など、ベースラインのLLM(LLaMA系)に合わせた標準的な構成に揃え、標準的なTransformerとパラメータ数や計算量が揃うように調整されているようです。
実験結果と課題
論文では3Bパラメータ規模のモデル等で検証が行われ、実験結果は以下のようになっています。
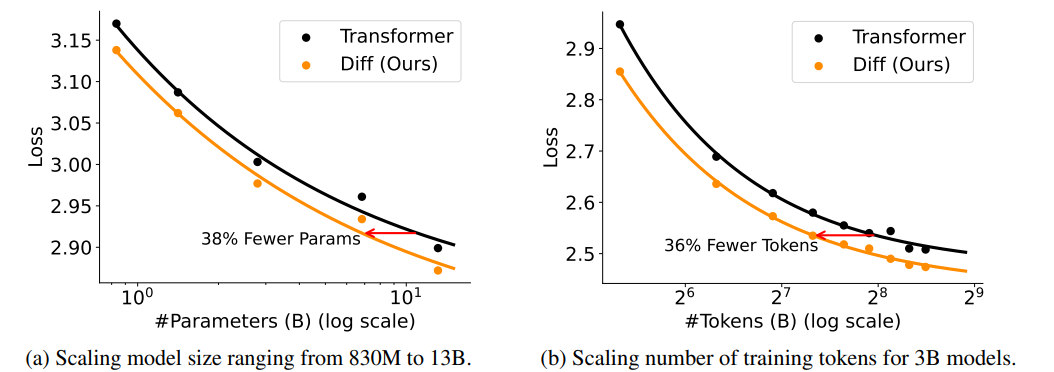
1. スケールした場合のトークン当たりのモデルの性能
言語モデルのTrain Lossにおいて、Transformerと同等の性能に到達するために必要な学習トークン数やモデルサイズが、約65%程度で済む傾向が見られました。これは、同じ計算リソースであればより高い性能が得られることを示唆しています。
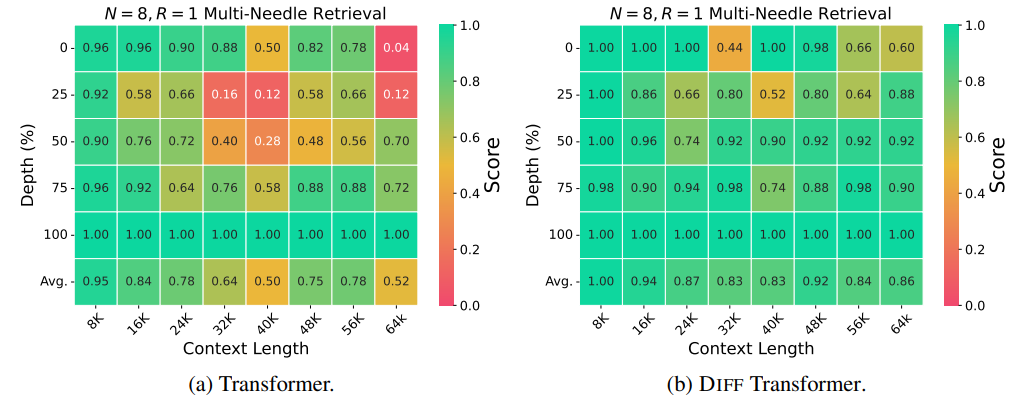
2. 情報検索タスクの性能
「Needle In A Haystack(干し草の中の針)」テストの結果が下図です。 従来のTransformer(図a)は、コンテキスト長が増加するにつれて検索精度が低下していますが、Differential Transformerはコンテキスト長が増加しても高い精度を維持しており、ノイズ除去の効果が顕著に表れています。
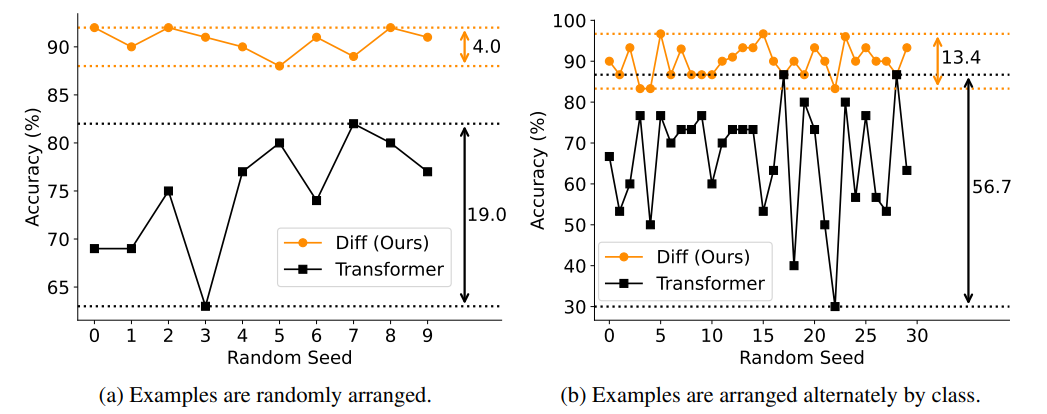
3. In-context学習
many-shotの分類問題で、1-shotから限界(64shot)まで増やした場合の性能の推移の図から、一貫して従来法を上回った(5.2% → 21.6%)ことが分かります。
また、Few-shotプロンプトにおいて例示の提示順序を入れ替えても精度が変動しにくい(ロバスト性が高い)という特性も示されています。
4. アテンションノイズの比較
Differential Transformer (Attention)は有用な情報により強く反応し、Attention Noiseを効果的に打ち消していることが分かります。

5. ハルシネーションの抑制
要約や質問応答タスクにおいて、文脈中の事実に即した回答を行う傾向が強まり、幻覚の発生率が低下することが確認されました。

他にも、モデル内部の中間表現における外れ値が減少し、低ビット量子化を行っても精度が劣化しにくいことも確認できているようです。
残された課題:推論速度と学習の不安定性
一方で、V1には実用化に向けたエンジニアリング上の課題も残されていました。
1. 推論速度の低下(約6〜12%減)
標準的なTransformerと比較して、V1はデコードの推論時のスループットが約6〜12%低下することが報告されています。 差分計算のために推論パスでValueキャッシュを複数回用意することや、標準のFlashAttentionのデコード用カーネル実装がそのまま使えないという制約に起因するようです、詳しくは次節で見ます。
2. RMSNorm に起因する学習不安定性
V1では、差分アテンションの出力がスパースになり統計的なバラつきが大きくなるため、各ヘッドの出力を整える目的で ヘッドごとのRMSNormが適用されていました。 学習を安定させるために必須とされていましたが、後のV2の解説記事によるとヘッドごとにやったことにより勾配スパイクの原因になるとのことです。
3. の一律設定による限界
の一律設定による限界
V1ではノイズ除去係数 がレイヤー内で一律(Global)に共有されていました。しかし、残すべき情報と消すべきノイズは文脈に応じて変わると考えられます。V2ではこの観点でより柔軟な制御をすることになります。
このように、V1は理論的な有効性を示したものの、エンジニアリング観点では推論速度や学習安定性などの観点で、改善の余地を残していました。これらをシンプルな方法で解決し、より実用的に性能改善したものがDifferential Transformer V2です。
Differential Transformer V2:V1の課題をどう解いたか
V2では、V1で残った実装上の問題や学習を不安定にしていた問題を解決できるとしています。 Hugging Face の記事を読んで理解したことをまとめてみました。
1. デコード高速化とカスタムカーネル不要化
これに対してV2では、Key/Valueのヘッド数は増やさずにQueryのヘッド数だけを2倍にする構成へ変更していて( が
、
が
)、これによりデコードで律速になりやすいKV-cacheのサイズを増やさずに処理できます。そのうえで、FlashAttentionを通常どおり1回呼び出し、得られた出力を偶数・奇数ヘッドで分けて差分を取る形に落とし込んでいます。V1で残っていた推論時の余計なcache読み出しや、カスタムカーネルへの依存を避けつつ、デコード速度を標準的なTransformerに近い水準へ寄せることができるようになってます。
2. Softmaxの出力振幅制約と、RMSNormの整理
V2記事では、softmaxを使う通常のAttentionでは、注意が特定のトークンに集中しているときは出力ベクトルもそれなりの大きさになりますが、注意が文脈全体に薄く広がると出力ベクトルが小さくなりやすい、と説明されてます。
V1ではこの小さくなりやすい出力を整える目的で、ヘッドごとのRMSNormをアテンション出力の直後に置いていました。一方で長系列になると、注意が広く拡散したヘッドほどRMSが小さくなり、RMSNormで元のスケールへ戻そうとしたときの増幅率が大きくなります。その結果、勾配スパイクが発生しやすくなり、学習が不安定になり得るということです。記事中では の例で約90倍(おおむね100倍級)の増幅が起こり得る、とのことです。
それに対しV2では、V1でRMSNormが必要になっていた要因(value head dimension が倍になっていた点と、 が全トークンでグローバル共有だった点)を解消し、ヘッドごとのRMSNormに依存しない形で学習を安定させる方針に変更しています。
具体的には、
をトークンごと・ヘッドごとに射影し、sigmoidで差分の強さを制御することで、RMSをモデル側が調整できるようにしています。
3. の動的化(トークンごと・ヘッドごと)
V2の差分は、V1のようにレイヤー内で一律な を使うのではなく、各トークン・各ヘッドに対して入力
から射影した
を使う点です。さらに、そのまま差分に使うのではなく sigmoid を通してスケールに用います。V2記事では、これによりコンテキストの大きさ(RMS)を制御しやすくなり、特に下限を0まで落とせることがAttention sinkの抑制と学習安定性に効果的だとのことです。
数式としては、概ね以下の形になります(記法は記事に合わせて簡略化してあります)。
実装の形:FlashAttention出力をペアで差分する
V2側は、FlashAttentionで得た出力から、偶数・奇数ヘッドを取り出して差分を取るだけ、という形になっています。
差分を取る2つのヘッドが同じGQAグループ内にあり同じKey/Valueを共有してるのが大事で、ここが崩れると学習が不安定になり、損失も悪化した、というアブレーション結果も書いてあります。
以下は疑似コードです。
# Differential Transformer V2 (concept; matches HF article structure) def diff_attn_v2(q, k, v, lam): """ q: (N, 2h, d) k: (N, h_kv, d) v: (N, h_kv, d) lam: (N, h, 1) # projected from X for each token, each head """ attn = flash_attn_func(q, k, v) # Important: pair heads within the same GQA group attn1 = attn[:, 0::2] attn2 = attn[:, 1::2] lam_val = sigmoid(lam) return attn1 - lam_val * attn2
アブレーション:どこが効いているか
V2記事では、実装上の勘所をアブレーションで確認しています。重要なのは次の3点です。
- 同じGQAのグループに属さないヘッド同士を差分すると、学習が明確に不安定になり(損失・勾配スパイクが増え)、損失も悪化する
にすると、初期化時点でRMSが小さくなりすぎ、損失が悪化する
- 射影した
学習上の観測:大規模事前学習での傾向
V2記事の実験はまだ進行中とのことですが、現時点の観測として以下が挙げられています。
- Transformerより言語モデル損失が低い(1Tトークン時点で0.02〜0.03の差)
- 特に学習率が大きい設定で、Transformerベースラインが不安定になるのに対して、損失や勾配のスパイクが減る
- 活性の外れ値(activation outliers)の大きさが減る
production-scaleのDenseモデルと、30A3のMoEを含み、トークン数は数兆規模、学習率は 〜
で実験しているようです。学習率は大きめに感じます。
今後の確認事項としては、中盤以降の学習効率や、長文ベンチマーク(context rot の緩和)での性能が挙げられています。
まとめ
V2は、V1で発生した実用上の問題を、できるだけ素直な設計変更で解きにいっています。
- デコードでは、KVを増やさずにクエリヘッドを増やす構成で、標準Transformerと同等水準の速度を狙い、カスタムカーネルを不要にした
- ヘッドごとのRMSNormに依存しない形へ移行し、長系列での過大な増幅と数値不安定性を避ける設計に寄せた
実験はまだ進行中ですが、現時点でも損失・学習安定性・外れ値抑制に関する前向きな観測がまとめられており、V1で見えた方向性を大規模学習の現場に持ち込む意図が明確になっている印象でした。
差分を導入した形で学習できそうでも、最適化として難しいという話が出てくるのは実務的で勉強になりました。本当は手元で推論してみたかったのですが、執筆時点では重みが見当たらなかったので手を動かすのは次の機会(後編?)に譲りたいと思います。
We Are Hiring!
ABEJAは、テクノロジーの社会実装に取り組んでいます。 技術はもちろん、技術をどのようにして社会やビジネスに組み込んでいくかを考えるのが好きな方は、下記採用ページからエントリーください! (新卒の方やインターンシップのエントリーもお待ちしております!)
特に下記ポジションの募集を強化しています!ぜひ御覧ください!
トランスフォーメーション領域:データサイエンティスト トランスフォーメーション領域:データサイエンティスト | 株式会社ABEJA
トランスフォーメーション領域:データサイエンティスト(ミドル)
トランスフォーメーション領域:データサイエンティスト(シニア) トランスフォーメーション領域:データサイエンティスト(シニア) | 株式会社ABEJA
