こんにちは!ABEJA で ABEJA Platform 開発を行っている坂井(@Yagami360)です。
先日の記事で、LeRobot で公開されているロボティクス領域の VLA モデル「π0」をファインチューニングした上で Gymnasium シミュレーター環境上で動かす方法を解説しました。 tech-blog.abeja.asia
前回の記事では、ただ単に公開されている学習用データセットでモデルをファインチューニングして推論させるだけの簡単な内容でしたが、今回はもう少し踏み込んでモデル自体の改善をやってみようと思います。
また前回はロボティクスモデルとして π0 モデルを動かしましたが、今回の記事では学習時間の都合上、より軽量なロボティクスモデルである「ACT」を使用してモデル改善を行います。
ACT [Action Chunking with Trasnformers] の詳細について気になる方は、以下のサイトを確認してもらえればと思います。とはいえ今回の記事では、ACT 内部のネットワーク部分以外での改善を行うのでパスしてもらっても OK です
さてモデル改善といってもいくつか方法があるとは思いますが、個人的な考えとしては大まかに以下の方法などに分類されるかと思ってます。(但し ②のファインチューニングに関しては、① や ⑦の一部の入出力ネットワーク改善との重複ありです)
- 学習用データセットを改善する
- ファインチューニングや転移学習を行い改善する
- データ拡張(Data Augmentation)を改善する
- 前処理や後処理を追加して改善する
- 最適化アルゴリズムの改善
- ハイパーパラメーターチューニング
- モデル内部のネットワーク構造を改善する
- 損失関数を改善する
- モデルをアンサンブルして改善する
など
① ~ ④ の方法は、比較的簡単に行えて改善効果が大きく(但し①はデータセットの収集が難しい場合は難易度あがる)ケースが多いかと思います。
⑤ ~ ⑥ は簡単ですが、そんなに改善効果高くないケースが多いです(全然チューニングしてない状態なら別ですが)。
⑦ ~ ⑧ の方法は技術的難易度が高く(但し ⑦ は入出力部分のネットワーク改善のみなら難易度が下がる)、モデルにもよりますが改善効果がそこまで大きくないケースが多い(特に最近の高性能モデルでは)かと思ってます。
今回の記事では、② は既に前回記事で実施したかと思うので、比較的容易に行えて改善効果の高い ③ の方法で改善を試みます。
また以下の後半記事にて、④ の方法(一部 ① もあり)でもモデル改善を試みます。
なお、今回の改善手法は ACT に限らず、π0 や NVIDIA の Isaac-GR00T などの多くの VLA モデルでも行える改善手法かと思ってます。
データ拡張(Data Augmentation)によるモデル改善
今回の記事では、前回記事と同じく LeRobot を使用してロボティクスモデルの学習や推論を行います。
前回記事でも見たように LeRobot の学習用スクリプトで実施されているデータ拡張(Data Augmentation)は、ランダム輝度変換のデータ拡張しか実施していないです。
データ拡張ありでの学習コマンド例
python lerobot/scripts/train.py \ --policy.type=act \ --dataset.repo_id=lerobot/aloha_sim_insertion_human_image \ --dataset.image_transforms.enable=true \ --dataset.image_transforms.max_num_transforms=5 \ --env.type=aloha \ --batch_size=16 \ --num_workers=0 \ --steps=100000 \ --eval_freq 200000 \ --policy.device=cudaデータ拡張の内容(記事作成時点:2025/06/25)
ロボティクスモデルに限らずですが、AIモデルでは殆どのケースで推論時の環境が学習時と同じような理想的な環境ではないのでモデルの汎化性能を含めて性能評価することが大事なのですが、正直この程度のデータ拡張では汎化性能は出せないです。
カメラ画像がぼやけているケース
以下、具体的な事例で見ていきます。
推論時は学習時と違ってロボットからのカメラ画像がぼやけてしまうことが起こるかもしれません。
この状況を Gymnasium でのシミュレーター環境上で再現するために、シミュレーター環境から得られるカメラ画像を OpenCV の GaussianBlur でぼかした上でモデルに入力します。モデルは ACT で、学習用データセットは前回の記事と同じく lerobot/aloha_sim_insertion_human_image で学習したモデルを使用します。
結果は、以下のようになりました。
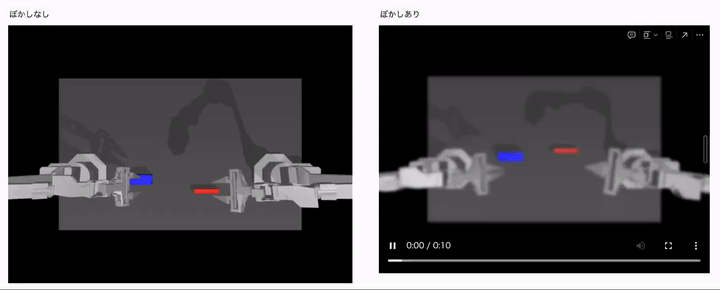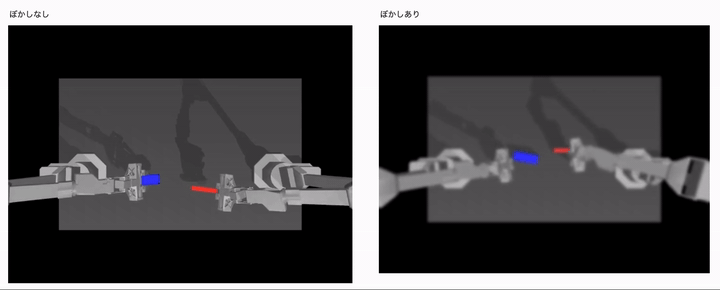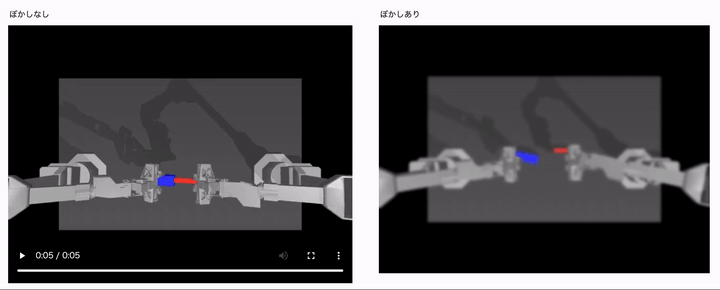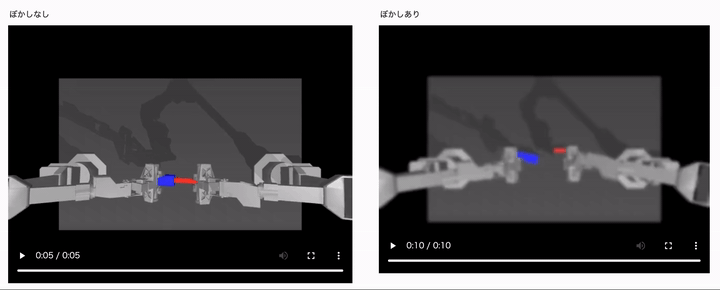
左側がカメラ画像のぼやけなしで、右側がカメラ画像のぼやけありの場合の結果になります。 ぼかしなしの学習用データセットと同じ理想的な環境では、うまく制御タスクに成功していますが、ロボットからのカメラ画像がぼやけた途端にうまく制御できていないことがわかるかと思います。
このようにAIモデルを評価する際には、理想的な環境での Max 品質だけではなく汎化性能を含めて評価することが大事になります。
そのため、カメラ画像がぼやけてしまっている場合の汎化性能をデータ拡張の改善で向上させようと思います。
具体的には、torchvision.transforms.v2.GaussianBlur でのデータ拡張を行うように Lerobot でデータ拡張設定を定義している lerobot/lerobot/common/datasets/transforms.py のコードを書き換えた上で学習します。(ライブラリのコードを直接書き換えているので再度 Lerobot コードの pip install が必要になる点に注意してください)
今回の記事では、GaussianBlur のデータ拡張の効果のみを確認したかったのでデフォルトで入っているランダム色調変換のデータ拡張は削除しています(実際には両方のデータ拡張を入れたほうがいいです)
また今回の記事では時間の都合上、データ拡張設定のハイパーパラメーターチューニングは行っていません。
コード例
... @dataclass class ImageTransformsConfig: """ These transforms are all using standard torchvision.transforms.v2 You can find out how these transformations affect images here: https://pytorch.org/vision/0.18/auto_examples/transforms/plot_transforms_illustrations.html We use a custom RandomSubsetApply container to sample them. """ # Set this flag to `true` to enable transforms during training enable: bool = False # This is the maximum number of transforms (sampled from these below) that will be applied to each frame. # It's an integer in the interval [1, number_of_available_transforms]. max_num_transforms: int = 3 # By default, transforms are applied in Torchvision's suggested order (shown below). # Set this to True to apply them in a random order. random_order: bool = False tfs: dict[str, ImageTransformConfig] = field( default_factory=lambda: { "Identity": ImageTransformConfig( weight=0.75, type="Identity", kwargs={}, ), # NOTE: GaussianBlur のデータ拡張を追加して、カメラ画像がぼやけていたときの汎化性能を向上させる # v2.GaussianBlur ではぼかし範囲(カーネスサイズ)が固定値になるので、様々なぼかし範囲(カーネルサイズ)での transform を定義しています。必要に応じてぼかし範囲や実行確率を調整してください "blur_1": ImageTransformConfig( weight=0.10, type="GaussianBlur_1", kwargs={"kernel_size": (1, 1), "sigma": (0.01, 0.01)}, ), "blur_5": ImageTransformConfig( weight=0.05, type="GaussianBlur_5", kwargs={"kernel_size": (5, 5), "sigma": (0.1, 2.0)}, ), "blur_9": ImageTransformConfig( weight=0.05, type="GaussianBlur_9", kwargs={"kernel_size": (9, 9), "sigma": (0.1, 2.0)}, ), "blur_13": ImageTransformConfig( weight=0.05, type="GaussianBlur_13", kwargs={"kernel_size": (13, 13), "sigma": (0.1, 2.0)}, ), "blur_15": ImageTransformConfig( weight=0.05, type="GaussianBlur_15", kwargs={"kernel_size": (15, 15), "sigma": (0.1, 2.0)}, ), } ) def make_transform_from_config(cfg: ImageTransformConfig): if cfg.type == "Identity": return v2.Identity(**cfg.kwargs) elif cfg.type == "ColorJitter": return v2.ColorJitter(**cfg.kwargs) elif cfg.type == "SharpnessJitter": return SharpnessJitter(**cfg.kwargs) # NOTE: GaussianBlur のデータ拡張を追加して、カメラ画像がぼやけていたときの汎化性能を向上させる elif cfg.type.startswith("GaussianBlur_"): return v2.GaussianBlur(**cfg.kwargs) else: raise ValueError(f"Transform '{cfg.type}' is not valid.") ...
以下のその結果です。(※ 学習ステップ数 20K にしているのは、20K 時点で loss 値が十分に収束していたためです)
| モデル | 学習ステップ数 | 成功率(at 50 episode) blur なし |
成功率(at 50 episode) blur なし |
|---|---|---|---|
| 改善前モデル(ACT without data-aug) | 20K | 24.00% | 0.00% |
| 改善後モデル(ACT with random blur data-aug) | 20K | 16.00% | 28.00% |
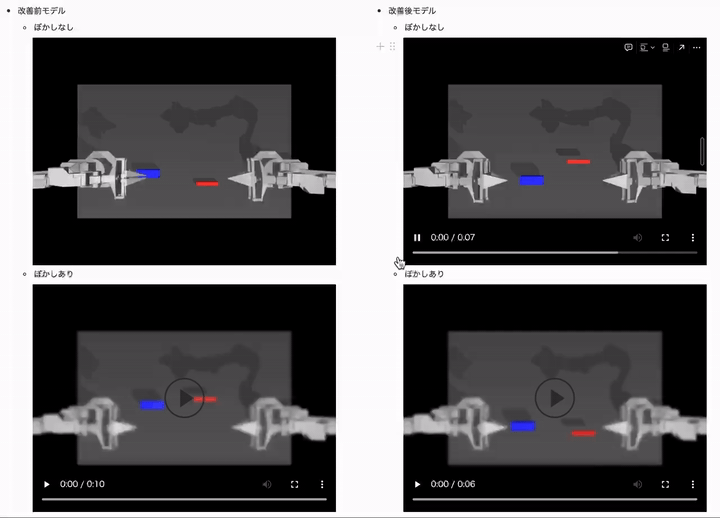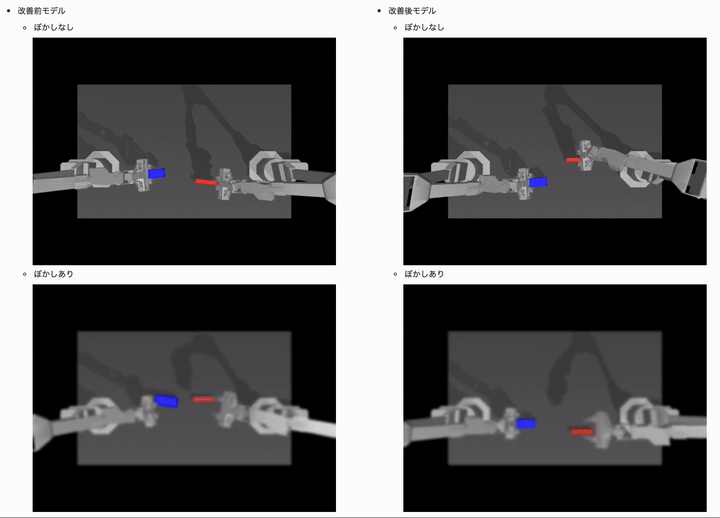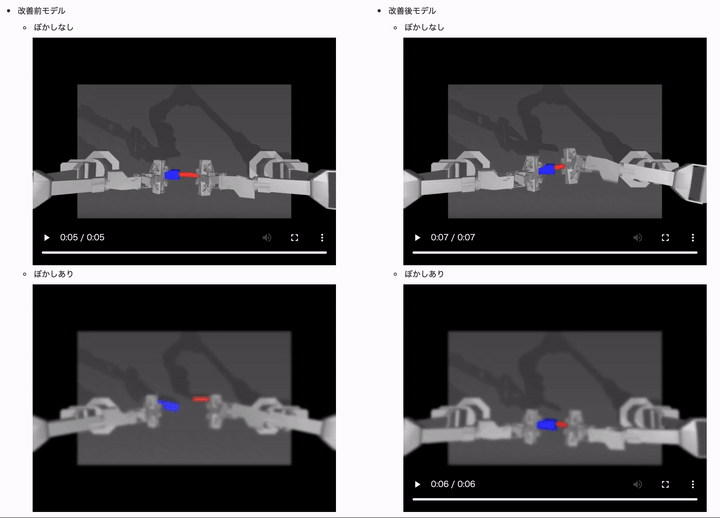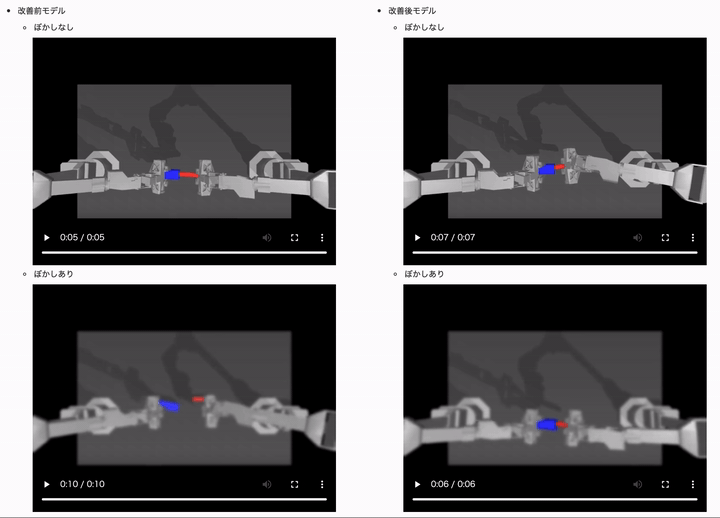
動画の右側が改善後モデルでのシミュレーション結果になります。 そもそもの理想的な環境での成功率自体低いというのはありますが、改善後のモデルではカメラ画像がぼやけていたときの成功率が 20% ~ 30% 近くも向上しているのがわかるかと思います! (※ ぼかしなしの成功率が多少下がっていますが、GaussianBlur の実施確率を大きくしすぎたのが原因です。データ拡張のハイパーパラメーターチューニングを行えばもう少し性能が向上すると思いますが今回の記事では時間の都合上やっていません。)
カメラ画像に障害物が映り込んでいるケース(オクルージョン)
次に別の事例として、ロボットからのカメラ画像に障害物が映り込んでしまうケース(オクルージョンといいます)もあるかもしれません。
この状況を Gymnasium でのシミュレーター環境上で再現するために、シミュレーター環境から得られるカメラ画像の一部を OpenCV を使って隠した上でモデルに入力します。
結果は、以下のようになりました。(モデルは ACT や学習用データセットは同じです)
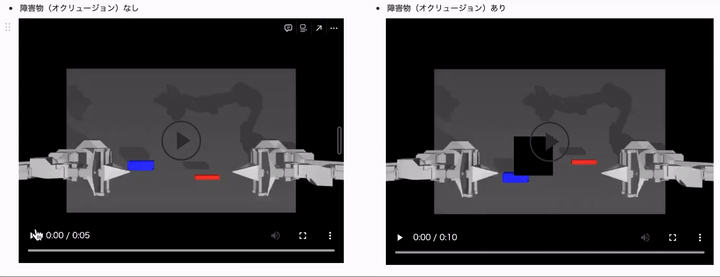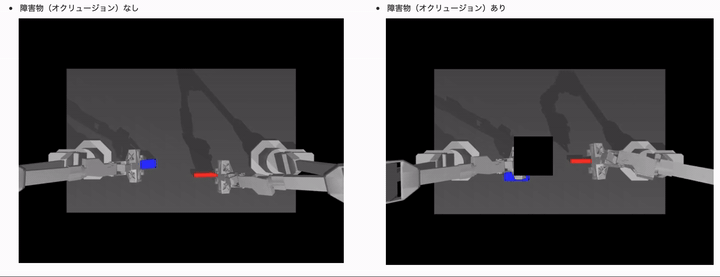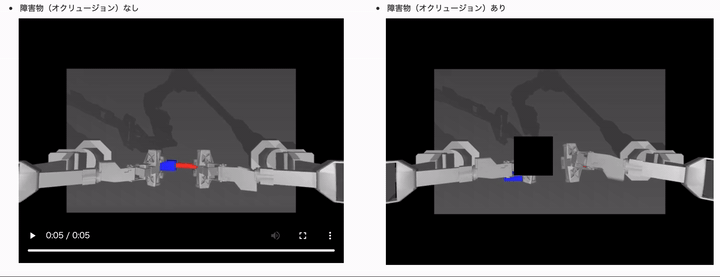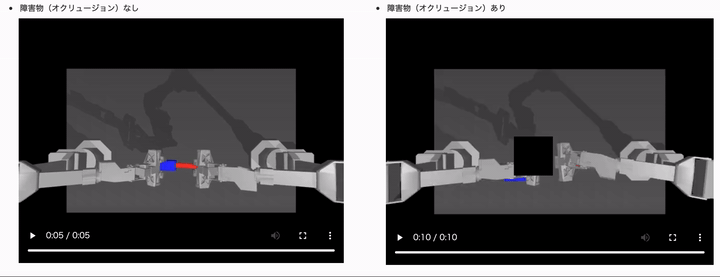
障害物(オクルージョン)ありのケースでは、制御タスクに失敗するようになっていることがわかるかと思います。
そのため障害物(オクルージョン)ありのケースでの汎化性能を向上させるために、
GaussianBlur のときと同様にして、torchvision.transforms.v2.RandomErasing でのデータ拡張を行うように Lerobot の lerobot/lerobot/common/datasets/transforms.py のコードを書き換えた上で学習します。今回は RandomErasing を使用しましたが、Cutout や Mixup のデータ拡張も有効かと思います
コード例
@dataclass class ImageTransformsConfig: """ These transforms are all using standard torchvision.transforms.v2 You can find out how these transformations affect images here: https://pytorch.org/vision/0.18/auto_examples/transforms/plot_transforms_illustrations.html We use a custom RandomSubsetApply container to sample them. """ # Set this flag to `true` to enable transforms during training enable: bool = False # This is the maximum number of transforms (sampled from these below) that will be applied to each frame. # It's an integer in the interval [1, number_of_available_transforms]. max_num_transforms: int = 3 # By default, transforms are applied in Torchvision's suggested order (shown below). # Set this to True to apply them in a random order. random_order: bool = False tfs: dict[str, ImageTransformConfig] = field( default_factory=lambda: { # NOTE: RandomErasing のデータ拡張を追加して、カメラ画像にオクルージョン(障害物)がある場合の汎化性能を向上させる "random_erasing": ImageTransformConfig( weight=1.0, type="RandomErasing", kwargs={"p": 0.25, "scale": (0.005, 0.20), "ratio": (0.5, 2.0), "value": 0, "inplace": False}, ), } ) def make_transform_from_config(cfg: ImageTransformConfig): if cfg.type == "Identity": return v2.Identity(**cfg.kwargs) elif cfg.type == "ColorJitter": return v2.ColorJitter(**cfg.kwargs) elif cfg.type == "SharpnessJitter": return SharpnessJitter(**cfg.kwargs) # NOTE: RandomErasing のデータ拡張を追加して、カメラ画像にオクルージョン(障害物)がある場合の汎化性能を向上させる elif cfg.type == "RandomErasing": return v2.RandomErasing(**cfg.kwargs) else: raise ValueError(f"Transform '{cfg.type}' is not valid.")
以下のその結果です。
| モデル | 学習ステップ数 | 成功率(at 50 episode) 障害物なし |
成功率(at 50 episode) 障害物あり |
|---|---|---|---|
| 改善前モデル(ACT without data-aug) | 20K | 18.00% | 4.00% |
| 改善後モデル(ACT with random erasing data-aug) | 20K | 22.00% | 12.00% |
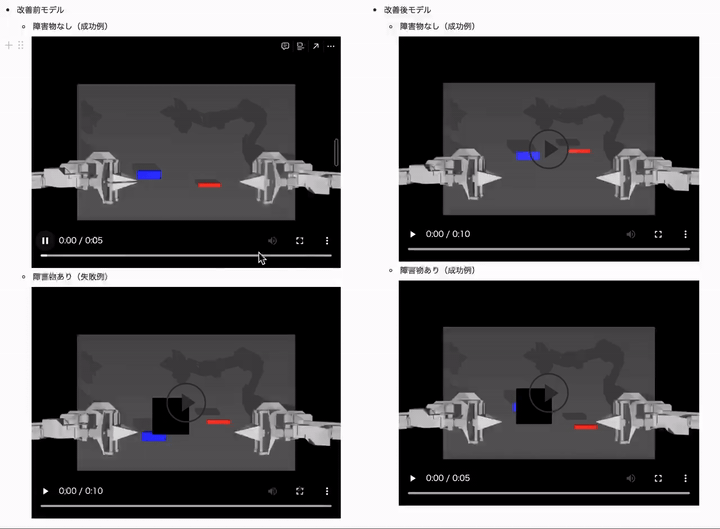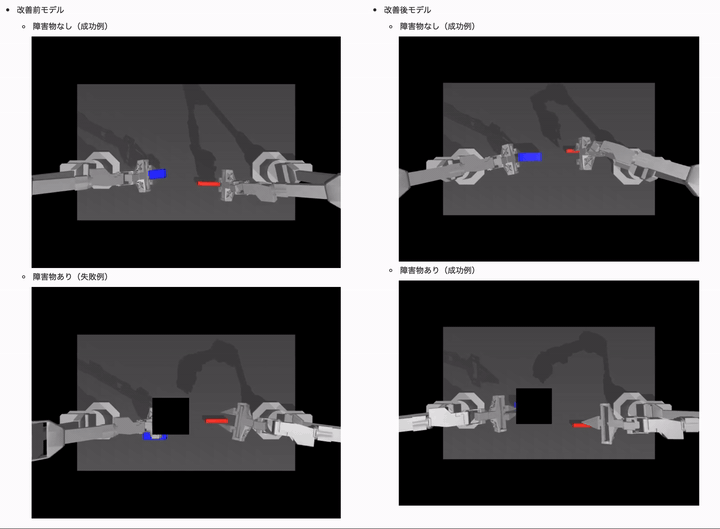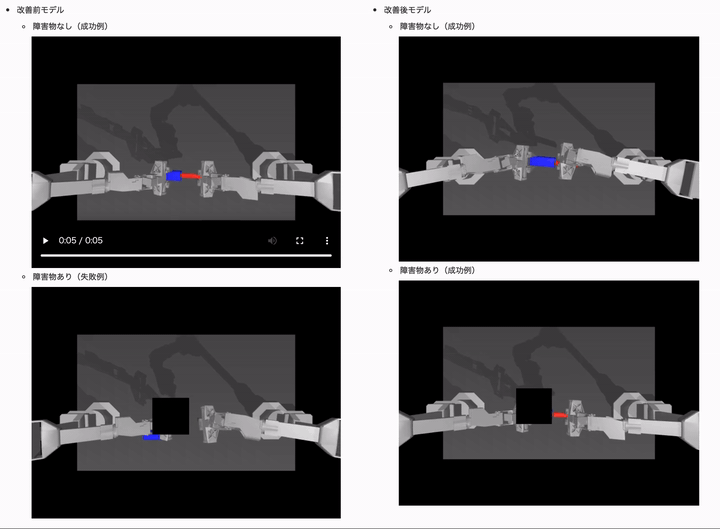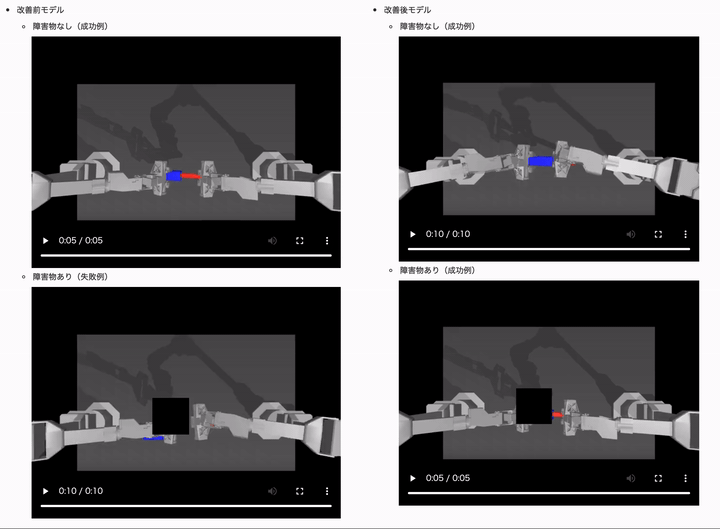
改善後のモデルでは障害物ありときの成功率が 10% 近くも向上しているのがわかるかと思います!
カメラ画像がぼやけておりさらに障害物が写っているケース
最後に、複合ケース(カメラ画像がぼやけておりさらに障害物が写っているケース)での汎化性能を向上させるために、GaussianBlur と RandomErasing 両方のデータ拡張を行ったモデルでの改善効果も見てみます。
同じく、torchvision.transforms.v2.GaussianBlurと torchvision.transforms.v2.RandomErasing 両方でのデータ拡張を行うように Lerobot の lerobot/lerobot/common/datasets/transforms.py のコードを書き換えた上で学習します。
コード例
... @dataclass class ImageTransformsConfig: """ These transforms are all using standard torchvision.transforms.v2 You can find out how these transformations affect images here: https://pytorch.org/vision/0.18/auto_examples/transforms/plot_transforms_illustrations.html We use a custom RandomSubsetApply container to sample them. """ # Set this flag to `true` to enable transforms during training enable: bool = False # This is the maximum number of transforms (sampled from these below) that will be applied to each frame. # It's an integer in the interval [1, number_of_available_transforms]. max_num_transforms: int = 3 # By default, transforms are applied in Torchvision's suggested order (shown below). # Set this to True to apply them in a random order. random_order: bool = False tfs: dict[str, ImageTransformConfig] = field( default_factory=lambda: { "Identity": ImageTransformConfig( weight=1.00, type="Identity", kwargs={}, ), # NOTE: RandomErasing のデータ拡張を追加して、カメラ画像にオクルージョン(障害物)がある場合の汎化性能を向上させる "random_erasing": ImageTransformConfig( weight=1.0, type="RandomErasing", kwargs={"p": 0.50, "scale": (0.005, 0.20), "ratio": (0.5, 2.0), "value": 0, "inplace": False}, ), # NOTE: GaussianBlur のデータ拡張を追加して、カメラ画像がぼやけていたときの汎化性能を向上させる # v2.GaussianBlur ではぼかし範囲(カーネスサイズ)が固定値になるので、様々なぼかし範囲(カーネルサイズ)での transform を定義しています。必要に応じてぼかし範囲や実行確率を調整してください "blur_1": ImageTransformConfig( weight=0.10, type="GaussianBlur_1", kwargs={"kernel_size": (1, 1), "sigma": (0.01, 0.01)}, ), "blur_5": ImageTransformConfig( weight=0.05, type="GaussianBlur_5", kwargs={"kernel_size": (5, 5), "sigma": (0.1, 2.0)}, ), "blur_9": ImageTransformConfig( weight=0.05, type="GaussianBlur_9", kwargs={"kernel_size": (9, 9), "sigma": (0.1, 2.0)}, ), "blur_15": ImageTransformConfig( weight=0.05, type="GaussianBlur_15", kwargs={"kernel_size": (15, 15), "sigma": (0.1, 2.0)}, ), } ) def make_transform_from_config(cfg: ImageTransformConfig): if cfg.type == "Identity": return v2.Identity(**cfg.kwargs) elif cfg.type == "ColorJitter": return v2.ColorJitter(**cfg.kwargs) elif cfg.type == "SharpnessJitter": return SharpnessJitter(**cfg.kwargs) # NOTE: RandomErasing のデータ拡張を追加して、カメラ画像にオクルージョン(障害物)がある場合の汎化性能を向上させる elif cfg.type == "RandomErasing": return v2.RandomErasing(**cfg.kwargs) # NOTE: GaussianBlur のデータ拡張を追加して、カメラ画像がぼやけていたときの汎化性能を向上させる elif cfg.type.startswith("GaussianBlur_"): return v2.GaussianBlur(**cfg.kwargs) else: raise ValueError(f"Transform '{cfg.type}' is not valid.")
以下のその結果です。
| モデル | 学習ステップ数 | 成功率(at 50 episode) ぼかしなし + 障害物なし |
成功率(at 50 episode) ぼかしあり + 障害物なし |
成功率(at 50 episode) ぼかしなし + 障害物あり |
成功率(at 50 episode) ぼかしあり + 障害物あり |
|---|---|---|---|---|---|
| 改善前モデル(ACT without data-aug) | 20K | 18.00% | 0.00% | 4.00% | 0.00% |
| 改善後モデル(ACT with random blur data-aug) | 20K | 16.00% | 28.00% | 0.00% | 6.00% |
| 改善後モデル(ACT with random erasing data-aug) | 20K | 22.00% | 4.00% | 12.00% | 0.00% |
| 改善後モデル(ACT with random blur + erasing data-aug) | 20K | 20.00% | 26.00% | 14.00% | 14.00% |
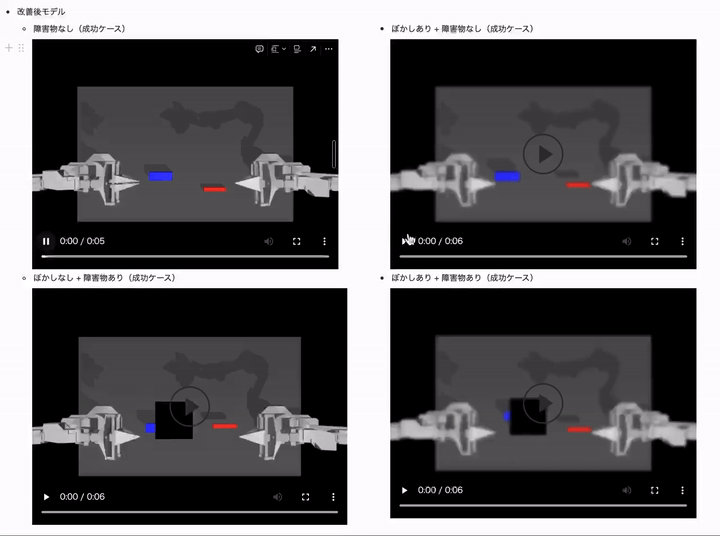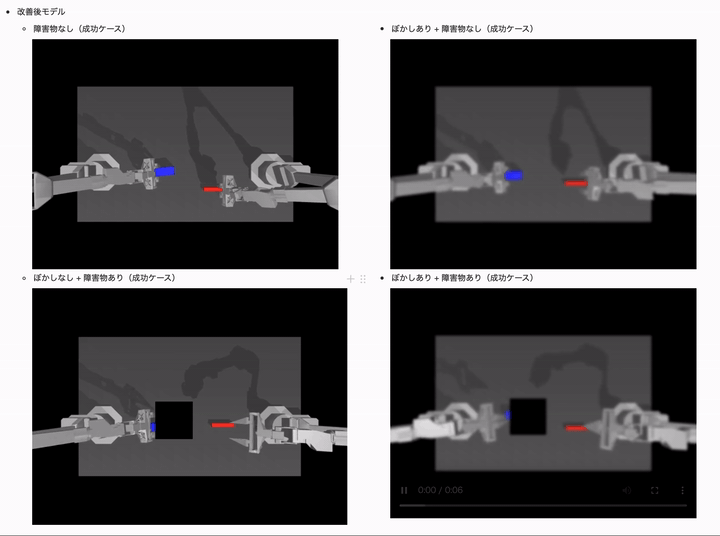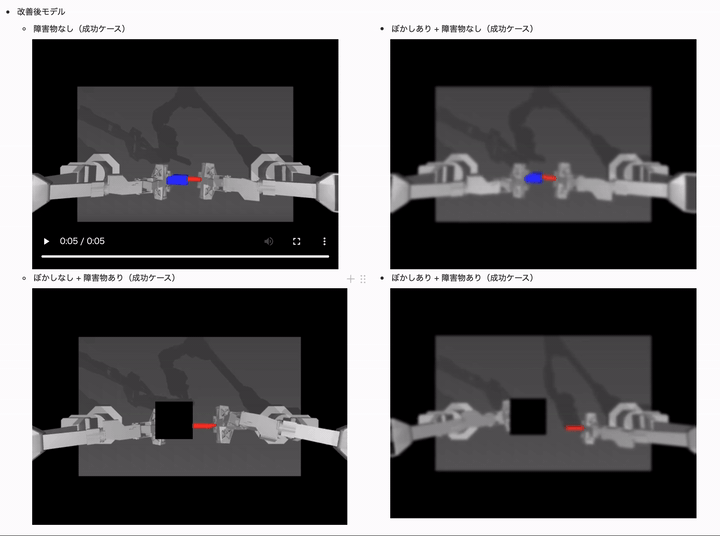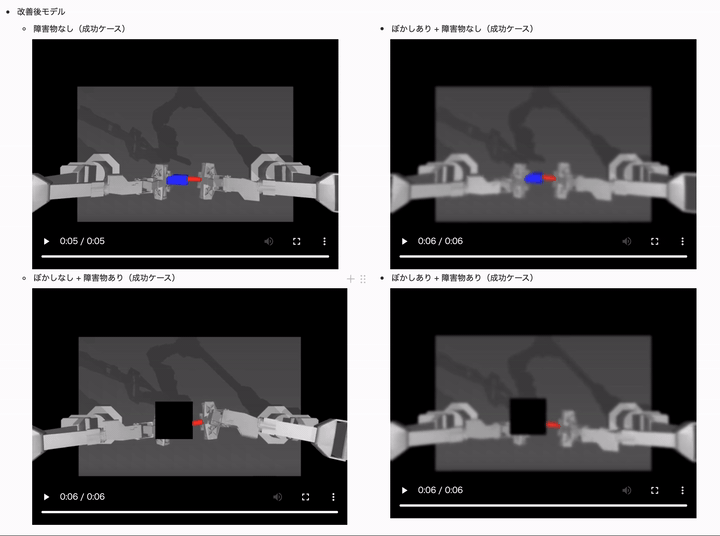
両方のデータ拡張を追加した改善モデルでは、全てのケースで成功率を高いレベルで維持できていることがかわるかと思います!
今回の記事では、時間の都合上この2種類のデータ拡張での改善にとどめますが、他にも様々なデータ拡張(Cutout, Mixup などなど)を追加することにより、それぞれの状況に応じた汎化性能を大きく向上させることが出来ると思います。
また今回の例では、Pytorch 公式のデータ拡張用メソッドを使用しましたが、Albumentations にある各種データ拡張ライブラリも有用だと思います。
但し、一番メジャーでよく使われるランダム Affine 変換のデータ拡張や水平垂直 flip のデータ拡張をカメラ画像に適用すると、今回のようなロボティクスタスクでは画像とロボット状態ベクトル及び行動ベクトルの位置関係が破綻するので逆に品質が落ちることがあるかもです(試してませんが)。画像を回転された分だけ状態ベクトルや行動ベクトルも回転させるとこういった問題はなくなるかもです
後半へ続く・・・
後編は以下の記事をご参照ください
We Are Hiring!
株式会社ABEJAでは共に働く仲間を募集しています!
ロボティクスやLLMに興味ある方々!機械学習プロダクトに関わるフロントエンド開発やバックエンド開発に興味ある方々! こちらの採用ページから是非ご応募くださいませ!
