こんにちは、ABEJAでエンジニアをしている宇留嶋です。今回は Vision‑Language‑Action (VLA) モデルSmolVLAをSO‑101ロボットアーム上で非同期推論してみた結果と、その仕組みをアーキテクチャ/gRPCレベルまで掘り下げて紹介します。モデルは自作データでファインチューニングしたsmolvla-move-cubeを利用しました。 SO‑101アームの組み立て・模倣学習やTPU製グリッパー検証については、以前公開した以下の記事もぜひご覧ください。
tech-blog.abeja.asia
tech-blog.abeja.asia
tech-blog.abeja.asia SmolVLAの同期推論はこちらの記事で検証しています。
https://tech-blog.abeja.asia/entry/so101-smolvla-202507/tech-blog.abeja.asia SmolVLAは小型で効率的なオープンソースのVision‑Language‑Actionモデルです。約450Mパラメータという軽量構成ながら、視覚トークン削減や層スキップ、フローマッチングによる連続行動予測などの工夫で、単一GPUやCPUでもリアルタイム制御を目指しています。LeRobotの公式実装では非同期推論スタックが用意されており、「知覚(Perception)→ 行動予測(Policy Inference)→ 実行(Actuation)」をパイプライン化することで制御レートを落とさず、推論による遅延を感じさせない滑らかな動作を実現できる点が特徴です。 同期実行では毎ステップで「観測 → 推論 → 実行」を直列に待つため、推論が重いほど制御周期が遅れたり動きがカクつきやすくなります。非同期推論では、制御ループは一定Hzを保ったままアクションキューから即座に行動を取り出し、推論は別スレッド別プロセスで並列に進むため、待ち時間はキューで吸収されロボットの動きは滑らかに維持されます。加えて推論系と制御系を疎結合にできることで、計算資源の分離(例:ポリシーサーバをリモートGPUで実行)、障害切り分け・スケーリングの容易さ、キュー枯渇時の安全停止といったフェイルセーフ設計も単純化できます。 SmolVLAの論文によれば、非同期推論スタックを導入しても成功率(Pick‑Place・Stacking・Sorting)は73–78 %と同期推論と同水準を維持しつつ、タスク完了時間を約30 %短縮し、同じ60 秒内で処理できるタスク数を2倍以上向上させています。(arXiv) 上図は Robot Clientは 今回タスクは以下を設定しました。 実行コマンドは以下2つです。 以前同期実行で同タスクを行った結果と合わせると以下になりました。 同期実行と比べ成功率は20%落ち、タスク完了時間に変化はありませんでした。 初期にキューが50→13へ急減したのは、観測変化が小さく類似観測フィルタにより再推論が抑制され、最初のチャンクをほぼ使い切ったためと考えられます。以降は 成功例 失敗例 同期推論での成功例 www.youtube.com
同期推論に比べて非同期推論はアームの揺れが多いことがわかります。 今回の結果では、非同期推論スタック自体は正しく動作していたものの、タスクが短く単純だったためか恩恵は確認できませんでした。平均所要時間は同期・非同期ともに7秒で変わらず、成功率は56%まで低下しました。非同期推論は連続実行できる一方で観測フィードバックが疎になり、把持の軽微な失敗や物体位置のずれに気づく前にチャンク内の行動をオープンループで実行してしまうため、失敗が増えた可能性もあるかもしれません。今後は、把持ミスやリカバリ動作を多く含むデータで追加学習し、非同期の効果が出やすい長尺で分岐の多いタスクでも評価してみたいと思います。 ABEJAでは、AI・ロボティクスの社会実装に挑戦する仲間を募集しています。興味のある方は以下の採用ページをご覧ください!
はじめに
SmolVLAとは
非同期推論のメリット
非同期推論スタックの仕組み
全体構成
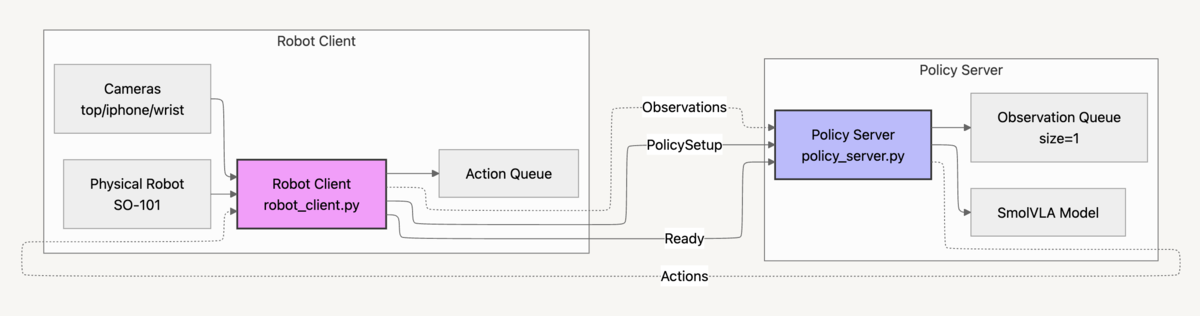
AsyncInference ServiceのRPC設計とデータフロー
services.proto で定義された AsyncInference Serviceの4つのRPCを中心に構成されています。// AsyncInference: from Robot perspective
// Robot send observations to & executes action received from a remote Policy server
service AsyncInference {
// Robot -> Policy to share observations with a remote inference server
// Policy -> Robot to share actions predicted for given observations
rpc SendObservations(stream Observation) returns (Empty);
rpc GetActions(Empty) returns (Actions);
rpc SendPolicyInstructions(PolicySetup) returns (Empty);
rpc Ready(Empty) returns (Empty);
}
Ready() で接続を宣言し、SendPolicyInstructions() で「SmolVLAをMPSデバイスで実行し、80ステップを1チャンクで返す」といった実行条件を送ります。ハンドシェイク完了後、ロボットからの観測は SendObservations() でストリーム送信され、Policy Server側では最新フレームだけをObservation Queue に保持します。キュー残量が閾値を下回るたびにClientが GetActions() を呼び、ServerはSmolVLAに最新観測を投入してアクションチャンクを返送します。こうして制御ループ・観測ストリーム・モデル推論が完全に並列化され、推論で生じる待ち時間は、事前に貯めたアクションを制御側が消費することでマスクされます。実験
タスク定義

実行コマンド
Policy Server起動コマンド
python src/lerobot/scripts/server/policy_server.py \
--host=127.0.0.1 \ # サーバが待ち受けるIP(既定: 127.0.0.1)
--port=8080 # サーバが待ち受けるポート(既定: 8080)
Robot Client起動コマンド
python src/lerobot/scripts/server/robot_client.py \
--server_address=127.0.0.1:8080 \ # Policy Serverのアドレス
--robot.type=so101_follower \ # ロボット種別(so100/so101/koch など)
--robot.port="/dev/tty.usbmodem5A4B0468471" \ # フォローアームのシリアルポート
--robot.id=main_follower \ # ロボット識別子
--robot.cameras="{camera setting}" \ # 各カメラ設定(JSON)
--task="Move the red cube into the black square area." \ # タスク指示文
--fps=30 \ # 制御ループの目標フレームレート
--policy_type=smolvla \ # 使用するポリシー種別
--pretrained_name_or_path=yuto-urushima/smolvla-move-cube \ # 事前学習済みモデル
--policy_device=mps \ # 推論デバイス(cuda/mps/cpu)
--actions_per_chunk=80 \ # 1回の推論で返すアクション数
--chunk_size_threshold=0.6 \ # キュー残量の閾値(比率)
--aggregate_fn_name=weighted_average \ # チャンク統合関数
--debug_visualize_queue_size=True # アクションキューサイズの可視化
actions_per_chunkとchunk_size_thresholdは複数パラメータを試した中で、安定してタスクを成功し、スムーズに動いたactions_per_chunk=80とchunk_size_threshold=0.6を設定しました。実験結果
実行方式
検証回数
成功回数
成功率
成功エピソードの平均所要時間
同期
25
19
76%
7.0秒
非同期
25
14
56%
7.0秒
アクションキューサイズの経時変化

actions_per_chunk=80, chunk_size_threshold=0.6により、残量が閾値を下回るたびに新チャンクを要求→ weighted_average(新旧チャンクの重なるステップを重み付きでブレンドして上書き)で統合→消費、というループが回り、16〜33付近で鋸歯状に振動しつつ枯渇を回避しました。ピークが32前後に収束したのは、実行レートと推論レートが釣り合い、実効キュー長が最適化された結果と推測されます。成功・失敗動画
考察とまとめ
We Are Hiring!
ABEJA Tech Blog
中の人の興味のある情報を発信していきます
