 こんにちは、ABEJA Platform に搭載しているアプリケーション、「ABEJA Insight for Retail」の開発と運用を担当している森永です。
こんにちは、ABEJA Platform に搭載しているアプリケーション、「ABEJA Insight for Retail」の開発と運用を担当している森永です。
導入いただいた企業様がよりデータドリブンな組織へと変革できるように日々新しい機能をリリースしていて、現在ベータ版として提供しています「AIスーパーバイザー」もその機能の 1 つです。
「ABEJA Insight for Retail」に蓄積いただいたデータからAIエージェントが適切な示唆出しやレポート作りが行える機能となっていて、特にデータ分析を苦手とするユーザーを支援する目的で作っています。

今後のこのような AI を使ったアシスト機能を使いやすくするため、他社でのAIエージェントの取り組みを定期的に調査しているのですが、Uber社のテックブログで公開されていた財務部門向けのAIエージェント『Finch』についての記事が興味深かったので、要点の翻訳もかねつつ、コメントを行なっていければと思います。
(※同名のコンテナ開発ツールとは異なりますのでご注意を)
元のブログ記事へのリンクは下記です。
Finch が開発された背景
財務部門は重要な判断をデータを活用して行わなければならない一方で、財務部門のメンバーがデータにアクセスするには複数のボトルネックがあったため、その解消を図るために Finch が開発されました。
最新の正確なデータを探すために、幾つものシステム (Presto, IBM Planning Analytics, Oracle EPM, Google Docs) に個別にアクセスして調べなければならないので手間がかかる。
必要な情報を取得するために複雑な SQL クエリを記述しなければならず、スキーマやドキュメントを確認しつつ、場合によってはデバッグも行いつつクエリ構築してもなお、バグを含んだクエリを記述してしまうリスクがある。
クエリが複雑すぎる場合や、必要なデータへのアクセス権を持たない場合、データサイエンスチームの人にデータ取得を依頼しなければならず、数時間から数日のリードタイムが発生してしまう。
Uber の財務部門に限らず、多くの企業で似たような問題は抱えているかと思います。 特に 1 の課題については大きい企業であればあるほど課題になっているのではないかと推測しています。
Finch が提供する価値
ユーザーの観点に立って考え、次のような価値が提供できるように設計されています。
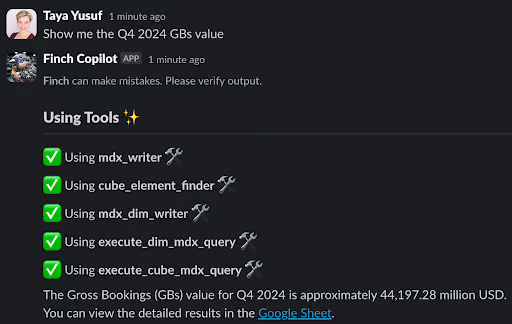
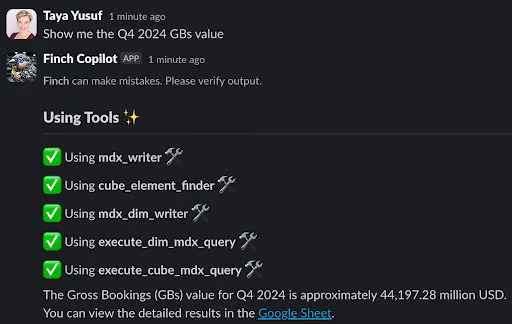
Slack を通じて自然言語で会話できる AI: 例えば、「What was GB value in US&C in Q4 2024?」と質問すれば正しいデータを自律的に取得して応答してくれる。
Uber の社内用語に精通: 前述の質問にあるような社内特有の用語を適切な一般用語に変換してくれる。 (例: 「US&C」 → US and Canada region、 「GBs」 → gross bookings)
自律的にクエリを実行: アクセスができるすべてのテーブルのメタデータから、ユーザーのリクエストに最も関連性のあるテーブルを選択して、正確な SQL クエリを実行してくれる。
適切なアクセス制御とセキュリティの確保: RBAC が実行時に組み込まれることにより機密性の高い財務情報にアクセスできるユーザーを適切に制限。
Google Sheets へのクエリ結果の出力: 大規模なテーブルのクエリ結果は自動的に Google Sheets に出力することによって、後続のワークフローをユーザーが自分の好むツールを利用して処理できるように工夫。
Finch のアーキテクチャ
Uber 社では、社内から提供元を問わず大規模言語モデルにアクセスするには社内の生成 AI ゲートウェイを経由してアクセスするようです。
このブログ記事内で詳細な言及はないですが、このようなゲートウェイ経由でのアクセス方式を採用している背景としては、各社が提供する大規模言語モデルのインターフェイスを統一して開発工数を低減させたり、大規模言語モデルの課金を一元管理できたり、外部への情報流出を防ぐためにセキュリティ観点のチェックを行い、個人情報等のセンシティブな文言は検閲をかけるためです。
生成 AI ゲートウェイは Uber 社内の機械学習プラットフォームである Michelangelo を開発しているチームが開発しており、本記事では詳細には解説しませんが、Uber 社のテックブログにて解説がありますのでご興味がある方は読んでみてください。
また、大規模言語モデルの統一インターフェイス開発に関しては弊社のメンバーより自作ライブラリを開発した経緯等や苦労ポイントを紹介した記事がありますので、こちらもご覧ください。
Finch の AI エージェントは LangChain 社が提供する LangGraph のライブラリを利用して実装されており、 データ取得エージェント (Data Retrieval Agent) や統括エージェント (Supervisor Agent) といったそれぞれの担当分野を担うエージェント間でやり取りが行われ、各タスクが適切な順序で実行されるように制御されています。
また、データソースとなる SQL テーブルのカラムとその値、また対応する自然言語の別名といったメタデータを OpenSearch のインデックスに保存しています。
これにより LLM が抽出した用語を OpenSearch の検索機能の 1 つであるファジーマッチング (曖昧検索) を使った情報取得が可能となり、LLM 単体でクエリを生成させた場合に比べて正確な WHERE 句フィルターを生成させることができるようになったようです。
ユーザーとのやり取りでは Slack SDK を用いて API 経由で Slack と連携しています。
そして、クエリ処理の各段階でエージェントの進捗状況をユーザーが追跡できるように、 LangGraph ライブラリ内の専用コールバックハンドラを使って、逐一 Slack のステータスメッセージをリアルタイム更新し、待たされている感を低減させたり、正しい情報を取得できているかをユーザーに見せてユーザービリティを向上させているようです。
さらには、最近公開された Slack AI Assistant API を活用し、ユーザーと Finch が新しいやり取りを始めた時におすすめ質問の提示、Slack アプリ内で Finch のピン留めや、Finch と常時やり取りできる分割ペインの常時表示を実現しています。
アーキテクチャの全体像は下記のようになっており、ブログでは詳細な言及のなかったセキュリティとの連携や SQL 以外でのデータ形式を使ったデータ取得にも対応していることが伺えます。

Finch 内のデータ処理の流れ
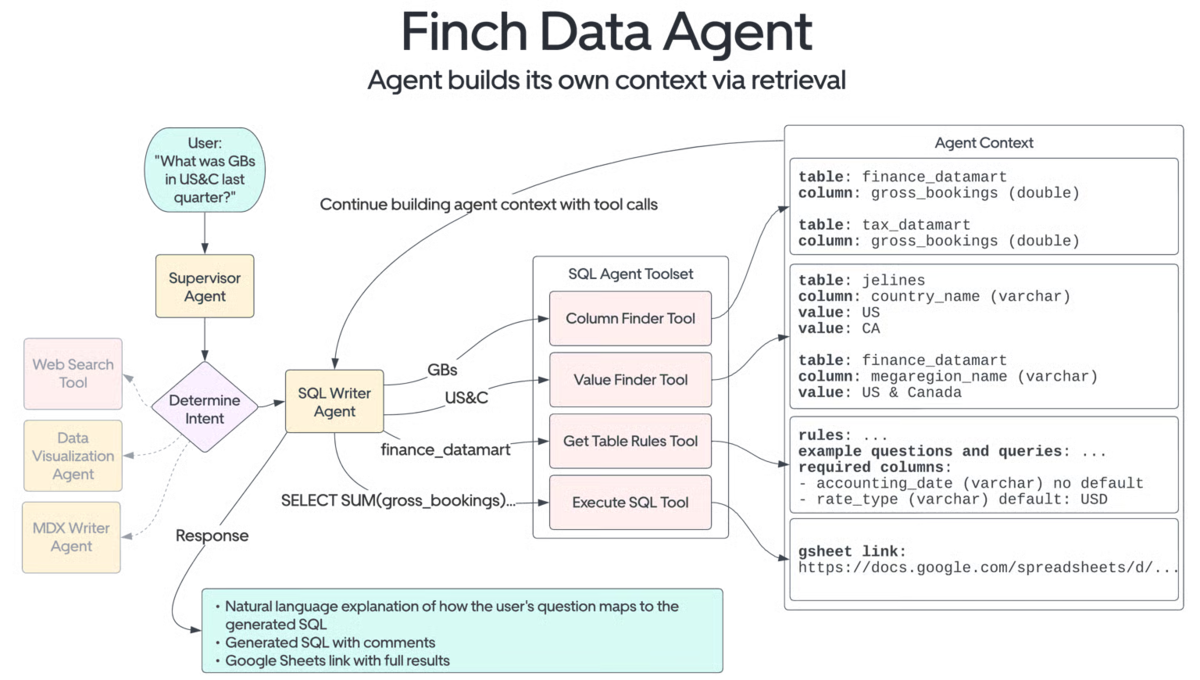
以上に基づいて、改めてデータ処理について SQL を使ってクエリするデータベースにあるデータを例に、順を追って整理すると以下になります。
[1] ユーザーが質問を入力: 財務部門のメンバーが Slack で Finch に質問を投げます。
[2] エージェントの連携: 統括エージェント(Supervisor Agent) がクエリを受け取り、データ取得エージェントの 1 つである SQL Writer Agent など適切なサブエージェントを呼び出します。どのエージェントを使うかはクエリの内容を統括エージェントが判断します。
[3] メタデータの取得: 呼び出されたエージェントが OpenSearch インデックスを検索し、必要に応じてカラム名や値、自然言語の別名といったメタデータを取得。これにより大規模言語モデルがデータベース向けのクエリ (例の場合は SQL クエリ) を精緻に構築できます。
[4-i] データベース向けクエリの構築と実行: SQL Writer Agent が取得したメタデータを用いてクエリを動的に組み立て、適切なデータソースに対して実行。
[4-ii] Slack を通じたリアルタイムのフィードバック: 処理全体を通して、LangGraph ライブラリ内の Slack コールバックハンドラが、ツール呼び出し等の各ステップを説明するステータスメッセージをリアルタイム更新し、ユーザーが進捗を追跡可能に。
[5] 取得したデータの応答: クエリ実行して得られた結果を、実行内容の詳細と共に Google Sheets へのリンクを添えて、Slack に分かりやすく実務で使いやすい形式でユーザーに応答。
図に起こすと下記のようになります。
パフォーマンスと精度の担保
Finch のパフォーマンスと精度を担保するために、以下のモニタリングを実施しています。
実際に AI エージェントを開発する方には参考になるかと思います。
AI エージェントの精度評価: 各サブエージェント (SQL Writer、Document Reader) を事前に用意した「期待される応答」の一覧に対して評価しています。特にデータ取得系のサブエージェント(例: SQL Writer Agent)では、生成したクエリの結果を「正解クエリ (ゴールデンクエリ) 」の結果と (おそらく構文解析を行なって) 比較し、クエリの書きっぷりが多少変化したとしても、最終的に出力されるデータの正しさを担保しています。
統括エージェント (Supervisor Agent) のサブエージェント選択精度: 質問が曖昧だったりツールの機能が似通っている場合に誤選択が起きる事例を特定。こちらは元のブログ記事では言及はありませんが、恐らく一般的な単体テストのようにテストケースとなる質問と想定される選択ツールを用意しているのだと推測しています。(例: Presto と Oracle EPM のデータ取得ツールは用途が異なるのに混同してしまうといったケースがあるそう)
エンドツーエンド検証: 実運用に近いクエリをシミュレーションし、システム全体の信頼性を検証。これは一般的な結合テストのようなシナリオを用意しているのでしょうね。
回帰テスト: 過去に実行されたクエリを再実行し、システムプロンプトやモデル変更をデプロイする前に精度ドリフトを検知しています。
上記のモニタリングを継続的に実施することにより、Finch は正確な財務データを提供して、デプロイを重ねても一貫した品質を維持しています。
AI エージェントのような大規模言語モデルを用いたアプリケーションは一般的に精度担保が難しいと言われますが、上記のように細かくモニタリングやテストを行うことで安定した品質で提供できているようです。
既存のアプリケーション以上に大規模言語モデルを用いたアプリケーションはやはりテストが重要になっていきそうですね。
補足コメント
他のツールとの比較や今後のロードマップについても元のブログ記事では言及されていましたが、際立った内容は見受けられなかったと判断したので、本記事は翻訳を割愛しています。
もし気になる方がいれば是非、元のブログ記事を読んでみてください!
元のブログ記事へのリンクは下記です。
最後に
社内向けの AI エージェントではありましたが、ユーザー体験からしっかり検討した上で設計して作り込まれていることが伺える内容かと思いました。
特に、SQL クエリを記述するために必要なメタデータを OpenSearch のインデックスとして検索しやすく用意してある点は非常に参考になりました。
非常に多くのデータセットを扱う時にはシステムプロンプトには入れ込める分量ではなくなるので、必要に応じてエージェントに検索させるというのは新しい発想でした。
今後、AI エージェントを使ったアプリケーション開発でも参考にしてみたくなりました。
We Are Hiring!
ABEJAは、様々な業界におけるテクノロジーの社会実装に取り組んでいます。 技術はもちろん、技術をどのようにして社会やビジネスに組み込んでいくかを考えるのが好きな方は、下記採用ページからエントリーください! 新卒の方やインターンシップのエントリーもお待ちしております!
